


Table of Contents
11 Descoberta usando consultas ODBC SQL
Visão geral
Este tipo de baixo nível discovery é feito usando SQL consultas, cujos resultados são transformados automaticamente em um objeto JSON adequado para descoberta de baixo nível.
Chave do item
As consultas SQL são executadas usando um tipo de item "Monitor de banco de dados". Portanto, a maioria das instruções sobre ODBC monitoramento se aplicam em para obter uma regra de descoberta "Monitor de banco de dados" funcional.
Duas chaves de item podem ser usadas nas regras de descoberta do "Monitor de banco de dados":
- db.odbc.discovery[<curto exclusivo descrição>,<dsn>,<string de conexão>] - este item transforma o resultado da consulta SQL em um array JSON, tornando o nomes de coluna do resultado da consulta na macro de descoberta de baixo nível nomes emparelhados com os valores de campo descobertos. Essas macros podem ser usado na criação de protótipos de itens, gatilhos, etc. Veja também: Usando db.odbc.discovery.
- db.odbc.get[<curto exclusivo descrição>,<dsn>,<string de conexão>] - este item transforma o resultado da consulta SQL em um array JSON, mantendo a nomes de colunas originais do resultado da consulta como um nome de campo em JSON emparelhado com os valores descobertos. Comparado com
db.odbc.discovery[], este item não cria uma descoberta de baixo nível macros no JSON retornado, portanto, não há necessidade de verificar se os nomes das colunas podem ser nomes de macros válidos. A descoberta de baixo nível macros podem ser definidas como uma etapa adicional conforme necessário, usando o LD personalizado macro funcionalidade com JSONPath apontando para os valores descobertos no retornou JSON. Veja também: Usando db.odbc.get.
Usando db.odbc.discovery
Como exemplo prático para ilustrar como a consulta SQL é transformada em JSON, vamos considerar a descoberta de baixo nível de proxies Zabbix por realizando uma consulta ODBC no banco de dados Zabbix. Isso é útil para criação automática de "zabbix[proxy,<name>,lastaccess]" itens internos para monitorar quais proxies estão vivos.
Vamos começar com a configuração da regra de descoberta:
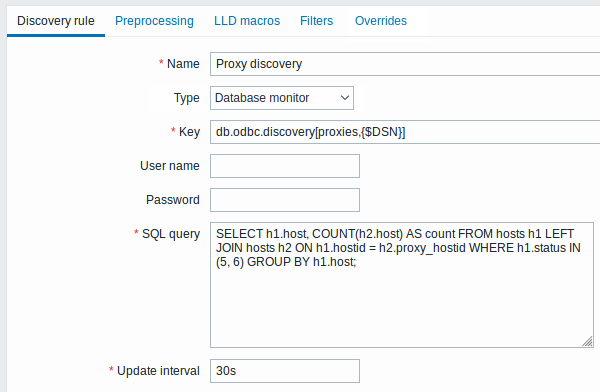
Todos os campos de entrada obrigatórios estão marcados com um asterisco vermelho.
Aqui, a seguinte consulta direta no banco de dados Zabbix é usada para selecionar todos os proxies Zabbix, juntamente com o número de hosts que eles são monitoramento. O número de hosts pode ser usado, por exemplo, para filtrar proxies vazios:
mysql> SELECT h1.host, COUNT(h2.host) AS count FROM hosts h1 LEFT JOIN hosts h2 ON h1.hostid = h2.proxy_hostid WHERE h1.status IN (5, 6) GROUP BY h1.host;
+---------+-------+
| anfitrião | contar |
+---------+-------+
| Japão 1 | 5 |
| Japão 2 | 12 |
| Letônia | 3 |
+---------+-------+
3 linhas em conjunto (0,01 seg)Pelo funcionamento interno do item "db.odbc.discovery[,{$DSN}]", o resultado desta consulta é transformado automaticamente no seguinte JSON:
[
{
"{#HOST}": "Japão 1",
"{#COUNT}": "5"
},
{
"{#HOST}": "Japão 2",
"{#COUNT}": "12"
},
{
"{#HOST}": "Letônia",
"{#COUNT}": "3"
}
]Pode-se ver que os nomes das colunas se tornam nomes de macros e linhas selecionadas tornam-se os valores dessas macros.
Se não for óbvio como um nome de coluna seria transformado em um nome de macro, sugere-se usar aliases de coluna como "COUNT(h2.host) AS count" no exemplo acima.
Caso um nome de coluna não possa ser convertido em um nome de macro válido, o a regra de descoberta não é suportada, com a mensagem de erro detalhando o número da coluna incorreta. Se for desejada ajuda adicional, o valor obtido nomes de colunas são fornecidos em DebugLevel=4 no arquivo de log do servidor Zabbix:
$ grep db.odbc.discovery /tmp/zabbix_server.log
...
23876:20150114:153410.856 Na consulta db_odbc_discovery():'SELECT h1.host, COUNT(h2.host) FROM hosts h1 LEFT JOIN hosts h2 ON h1.hostid = h2.proxy_hostid WHERE h1.status IN (5, 6) GROUP BY h1.host;'
23876:20150114:153410.860 db_odbc_discovery() coluna[1]:'host'
23876:20150114:153410.860 db_odbc_discovery() coluna[2]:'COUNT(h2.host)'
23876:20150114:153410.860 Fim de db_odbc_discovery():NOTSUPPORTED
23876:20150114:153410.860 Item [Zabbix server:db.odbc.discovery[proxies,{$DSN}]] erro: Não é possível converter o nome da coluna nº 2 em macro.Agora que entendemos como uma consulta SQL é transformada em um JSON objeto, podemos usar a macro {#HOST} em protótipos de itens:
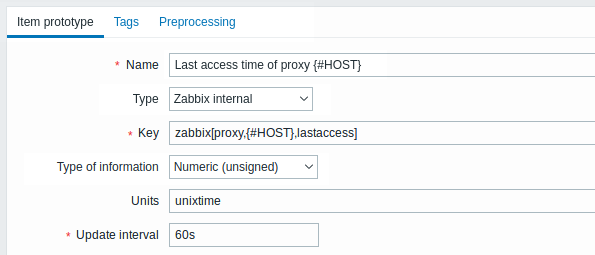
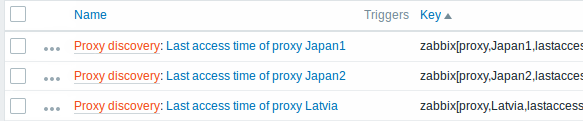
Depois que a descoberta for realizada, um item será criado para cada proxy:
Usando db.odbc.get
Usando db.odbc.get[,{$DSN}] e o seguinte exemplo SQL:
mysql> SELECT h1.host, COUNT(h2.host) AS count FROM hosts h1 LEFT JOIN hosts h2 ON h1.hostid = h2.proxy_hostid WHERE h1.status IN (5, 6) GROUP BY h1.host;
+---------+-------+
| anfitrião | contar |
+---------+-------+
| Japão 1 | 5 |
| Japão 2 | 12 |
| Letônia | 3 |
+---------+-------+
3 linhas em conjunto (0,01 seg)este JSON será retornado:
[
{
"host": "Japão 1",
"contar": "5"
},
{
"host": "Japão 2",
"contar": "12"
},
{
"host": "Letônia",
"contar": "3"
}
]Como você pode ver, não há macros de descoberta de baixo nível. No entanto, macros de descoberta de baixo nível personalizadas podem ser criadas no LLD macros de um regra de descoberta usando JSONPath, por exemplo:
Agora esta macro {#HOST} pode ser usada em protótipos de itens: