
Helo!
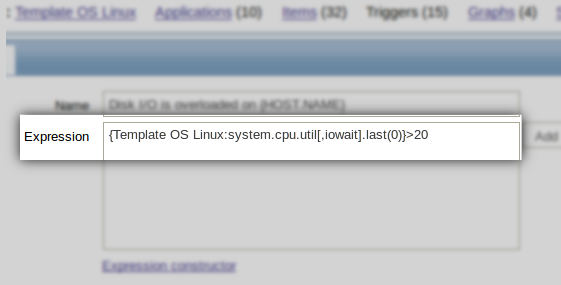
Can somebody help me? My trigger hysteresis not working. I have one trigger how below. I am using macros on the triggers.
This is a trigger result in the events tab.
Events:
Can somebody help me? My trigger hysteresis not working. I have one trigger how below. I am using macros on the triggers.
Code:
(({TRIGGER.VALUE}=0) & ({Template OS Linux:proc.num[].last(600)} > {$CPU_LOAD})) | (({TRIGGER.VALUE}=1) & ({Template OS Linux:proc.num[].last(600)} < {$CPU_LOAD}))
Code:
(({TRIGGER.VALUE}=0) & ({SERVER2:proc.num[].last(600)} > 400)) | (({TRIGGER.VALUE}=1) & ({SERVER2:proc.num[].last(600)} < 400))
Attached Files


Comment