Documentation

Table of Contents
3 Низкоуровневое обнаружение
Обзор
Низкоуровневое обнаружение предоставляет возможность автоматического создания элементов данных, триггеров и графиков для разных ресурсов на компьютере. Например, Zabbix может автоматически начать мониторить файловые системы или сетевые интерфейсы на вашем устройстве, без необходимости создания вручную элементов данных для каждой файловой системы или сетевого интерфейса. Кроме того, в Zabbix имеется возможность настроить удаление ненужных объектов, основываясь на фактических результатах периодически выполняемого обнаружения.
В Zabbix 2.0, поддерживаются три встроенных типа элементов данных для обнаружения:
- обнаружение файловых систем;
- обнаружение сетевых интерфейсов;
- обнаружение нескольких SNMP OID'ов.
Пользователь имеет возможность определить свои собственные типы обнаружения, обеспечив их функционирование согласно спецификации JSON протокола.
Общая архитектура процессов обнаружения представлена ниже.
Сначала, пользователь создает правило обнаружения в "Настройка" → "Шаблоны" → колонка "Обнаружение". Правило обнаружения состоит из (1) элемента данных, который осуществляет обнаружение необходимых объектов (например файловые системы или сетевые интерфейсы) и (2) прототипов элементов данных, триггеров и графиков, которые должны быть созданы на основании полученных значений этого элемента данных.
Элемент данных, который осуществляет обнаружение необходимых объектов - это как бы обычный элемент данных, видимый в других местах интерфейса: Zabbix сервер запрашивает у Zabbix агента значение для этого элемента данных (или любой другой обозначенный тип элемента данных), а агент отвечает текстовым значением. Разница в том, что значение, которое возвращает агент, должно содержать список обнаруженных объектов в специальном JSON формате. Хотя детали этого формата важны только для создателей собственных проверок обнаружения, но всем необходимо знать, что возвращаемое значение содержит список из пар: макрос → значение. Например, элемент данных "net.if.discovery" мог бы вернуть две пары: "{#IFNAME}" → "lo" и "{#IFNAME}" → "eth0".
Элементы данных низкоуровневого обнаружения - vfs.fs.discovery, net.if.discovery поддерживаются Zabbix агентом версии 2.0.
В Zabbix прокси максимальное возвращаемое значение для правила низкоуровневого обнаружения составляет 4000 символов для Oracle DB и 2048 символов для IBM DB2.
Эти макросы потом используются в именах, ключах и в других полях прототипов при создании элементов данных, триггеров и графиков для каждого обнаруженного объекта. Для элементах данных, эти макросы могут быть использованы в именах, ключах, SNMP OID, в выражениях вычисляемых элементов данных, в SSH и Telnet скриптах, в параметрах мониторинга баз данных. Для триггеров, в именах и в выражениях. Для графиков, только в поле имени.
Когда сервер получает значение для обнаруживаемого элемента данных, он смотрит на пару макрос → значение и для каждой пары генерирует реальные элементы данных, триггера и графики, основываясь на их прототипах. В приведенном выше примере с "net.if.discovery", сервер будет генерировать один набор элементов данных, триггеров и графиков для интерфейса "lo" и другой набор для интерфейса "eth0".
Следующий раздел иллюстрирует в деталях процесс, описанный выше, и служит руководством к действию как осуществлять обнаружения файловых систем, сетевых интерфейсов и нескольких SNMP OID. Последний раздел описывает формат JSON для элементов данных обнаружения и дает пример того, как внедрить ваш собственный обнаружитель файловых систем в виде Perl скрипта.
1 Обнаружение файловых систем
Для настройки обнаружения файловых систем, сделайте следующее:
- Перейдите в: Настройки → Шаблоны
- Нажмите на Обнаружение в строке соответствующего шаблона

- Нажмите на Создать правило обнаружения в верхнем правом углу экрана
- Заполните форму следующими деталями
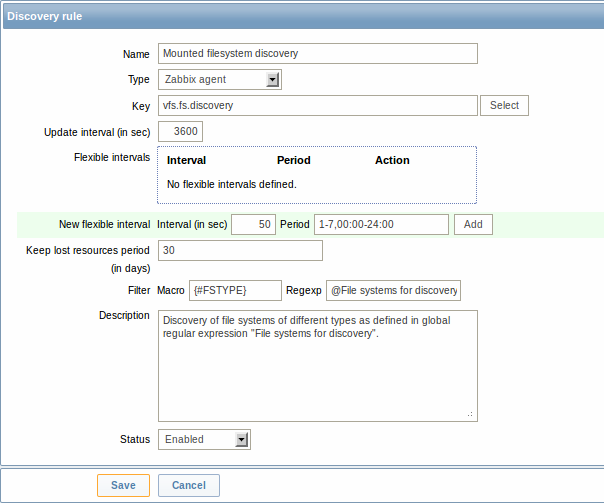
| Параметр | Описание |
|---|---|
| Имя | Имя правила обнаружения. |
| Тип | Тип проверки выполняемого обнаружения; должен быть Zabbix агент для обнаружения файловых систем. |
| Ключ | Элемент данных "vfs.fs.discovery" уже встроен в Zabbix агент под многие платформы (для получения более детальных сведений смотрите список поддерживаемых ключей элементов данных), и будет в JSON формате возвращать список файловых систем и их типы, присутствующих в компьютере. |
| Интервал обновления (в сек) | Этот фильтр задает как часто Zabbix будет выполнять обнаружение. В начале, когда вы только настраиваете обнаружение файловых систем, вы можете установить маленький интервал, но как только вы удостоверитесь что всё работает, вы можете установить его в 30 минут или более, потому что файловые системы обычно не меняются очень часто. Обратите внимание: Если зададите значение равное '0', элемент данных не будет обрабатываться. Однако, если также существует переменный интервал с ненулевым значением, элемент данных будет обрабатываться во течении действия переменного интервала. |
| Переменные интервалы | Вы можете создать исключения из Интервал обновления. Например: Интервал: 0, Период: 6-7,00:00-24:00 - отключит обработку на выходных. В остальное время будет использоваться интервал обновления по умолчанию. Если переменные интервалы перекрываются, то будет использовано наименьшее значение Интервал для перекрывающегося периода. Смотрите страницуСпецификации периода времени для получения информации о формате Период. Примечание: Если задано значение равное '0', элемент данных не будет обрабатываться в течении действия переменного интервала и будет вернется к обработке в соответствии с Периодом обновления как только переменный интервал завершится. |
| Период сохранения потерянных ресурсов (дней) | Это поле позволяет вам указать как много дней обнаруженный объект будет сохранен (не будет удален), как только его состояние обнаружения станет "Не обнаруживается более" (макс 3650 дней). Обратите внимание: Если значение равно "0", объекты будут удалены немедленно. Использование "0" не рекомендуется, так как простое ошибочное изменение фильтра может закончится тем, что объект будет удален вместе со всеми данными истории. |
| Фильтр | Фильтр может быть использован только для генерирования реальных элементов данных, триггеров и графиков для конкретных файловых систем. Ожидается Расширенные регулярные выражения POSIX. Например, если вы заинтересованы только в файловых системах C:, D: и E:, вы можете поместить {#FSNAME} в поле "Макрос" и регулярное выражение "^C|^D|^E" в поле "Регулярное выражение" (например "^ext|^reiserfs"). Фильтрация также возможна по типам файловых систем при использовании макроса {#FSTYPE}. Вы можете ввести в поле "Регулярное выражение" регулярное выражение или ссылку на глобальное регулярное выражение. Для проверки регулярного выражения вы можете использовать "grep -E", например: for f in ext2 nfs reiserfs smbfs; do echo $f \| grep -E '^ext\|^reiserfs' \|\| echo "SKIP: $f"; done |
| Описание | Введите описание. |
| Состояние | Активировано - правило будет обрабатываться. Деактивировано - правило не будет обрабатываться. Не поддерживается - элемент данных не поддерживается. Этот элемент данных не будет обрабатываться, однако Zabbix может пытаться периодически сменить состояние элемент данных в Активирован в соответствии с установленным интервалом для обновления не поддерживаемых элементов данных. |
История правила обнаружения не сохраняется
Как только правило будет создано, переходим к элементам данных для этого правила и нажимаем "Создать прототип" для создания прототипа элементов данных. Обратите внимание как макрос {#FSNAME} используется в месте, где нужно вписывать имя файловой системы. Когда правило будет обрабатываться, этот макрос будет замещен обнаруженной файловой системой.
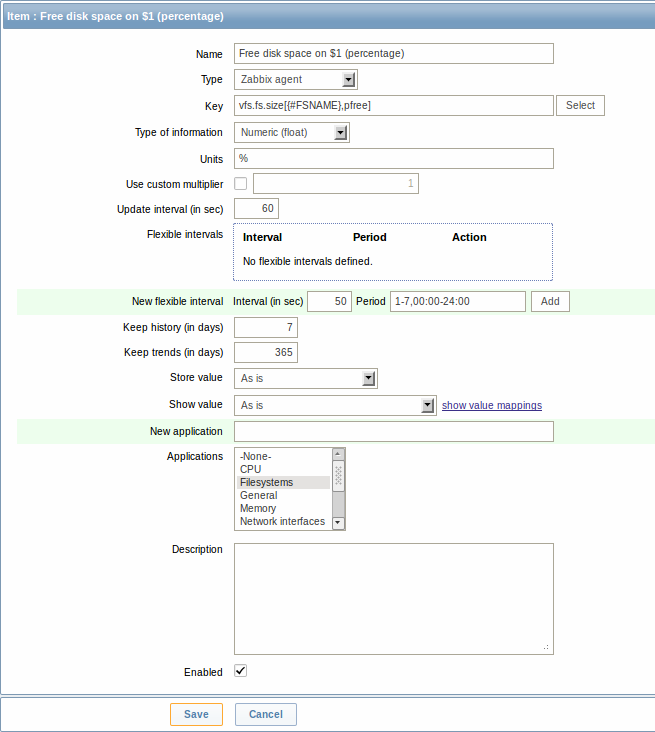
Если прототип элемента данных создан с состоянием Деактивирован, то он будет добавлен как обнаруженный объект, но в отключенном состоянии.
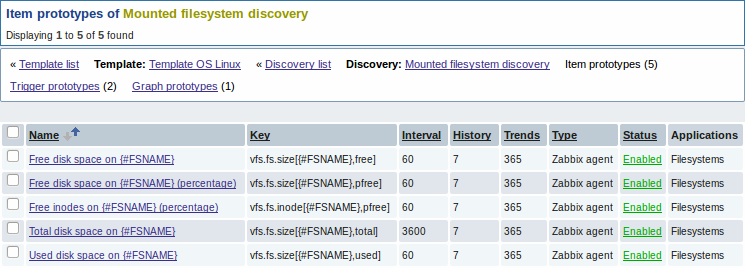
Мы можем создать несколько прототипов элемента данных для каждой интересующей нас характеристики файловой системы:
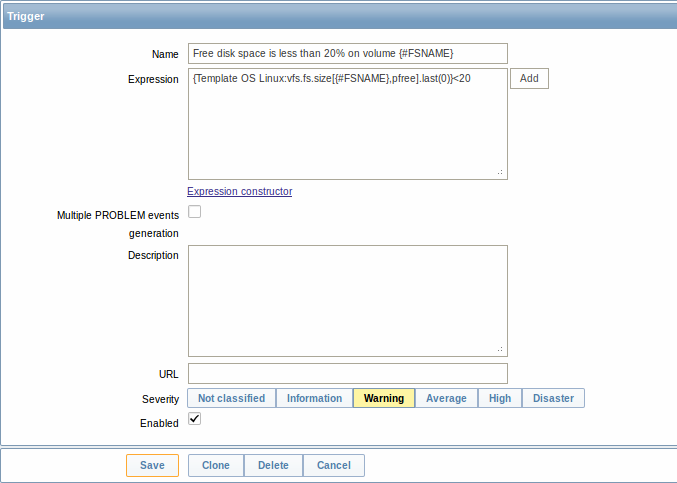
Теперь похожим способом мы создадим прототипы триггеров:
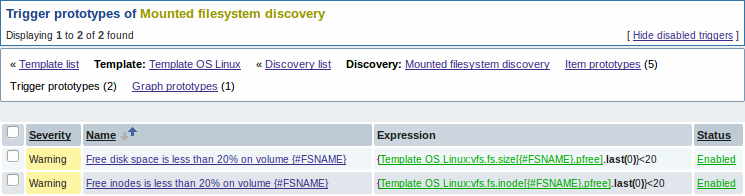
И также прототипы графиков:
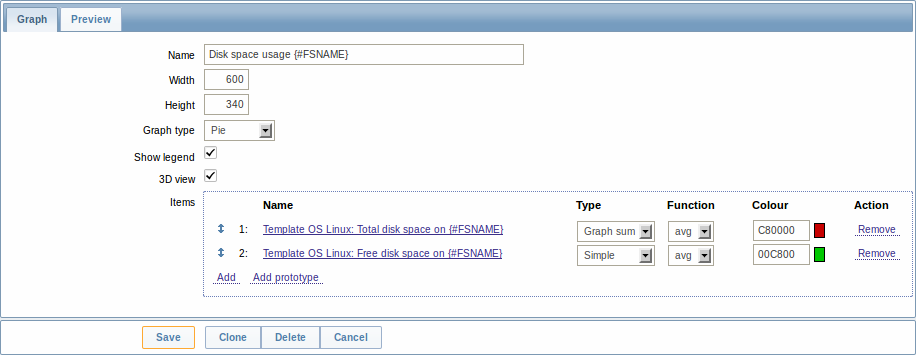
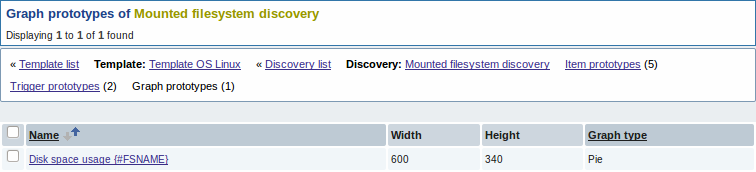
В конце концов, мы создали правило обнаружения, которое выглядит как показано ниже. Оно имеет пять прототипов элементов данных, два прототипа триггеров и один прототип графика.

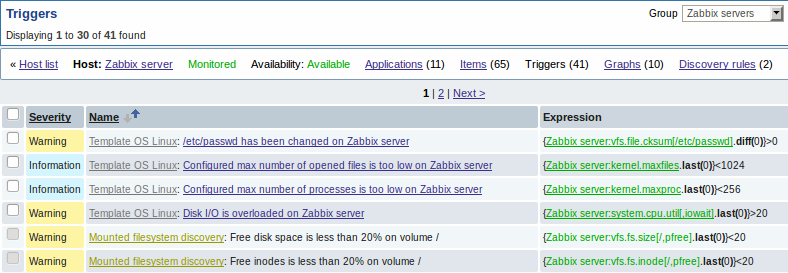
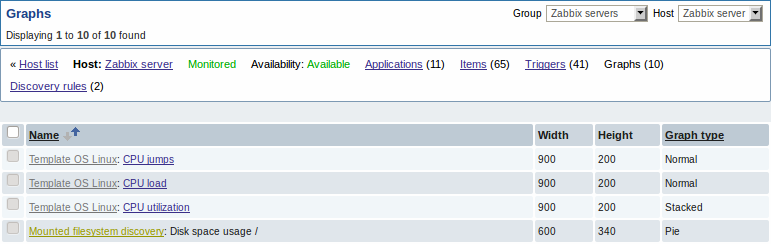
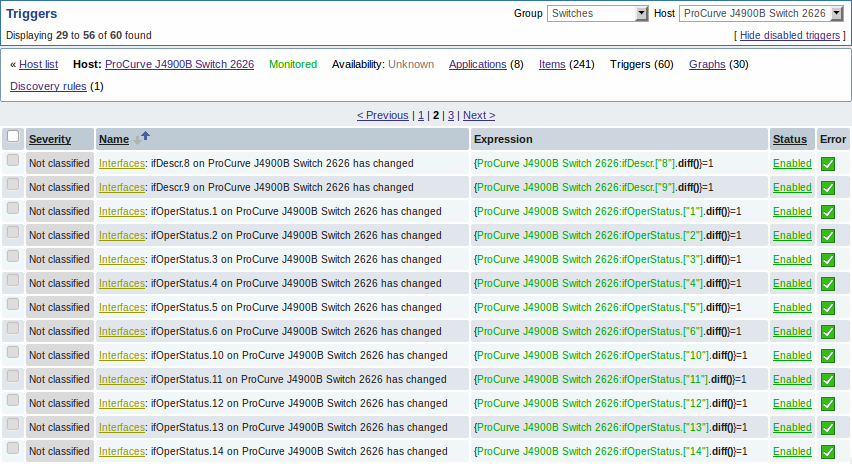
Представленные скриншоты иллюстрируют как уже обнаруженные элементы данных, триггера и графики выглядят в настройке узла сети. Обнаруженные объекты предварены префиксом-ссылкой золотистого цвета, которая ведет к правилу обнаружения, создавшего эти объекты.
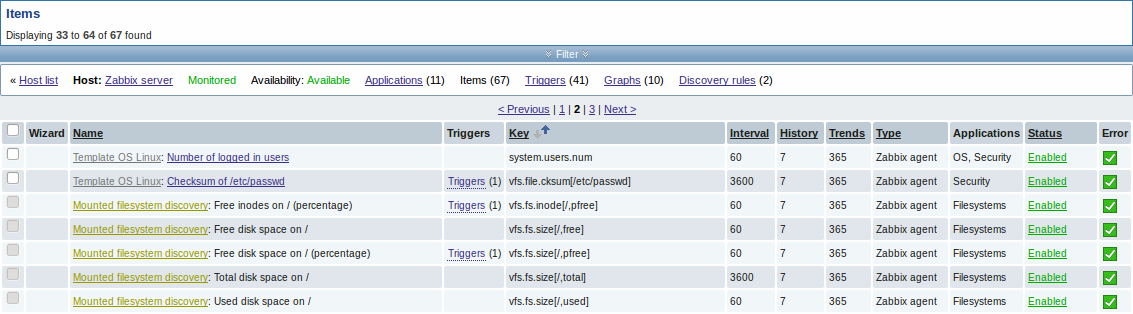
Элементы данных (а также, триггеры и графики) созданы с помощью низкоуровневого правила обнаружения невозможно удалить вручную. Тем не менее, они будут удалены автоматически, если обнаруженный объект (файловая система, интерфейс и т.д.) более не обнаруживаются (или не попадают более под фильтр). В этом случае они будут удалены спустя некоторое количество дней заданное в поле Период сохранения потерянных ресурсов.
Когда обнаруженный объект становится 'Более не обнаруживается', в списке элементов данных будет отображаться оранжевый индикатор времени жизни. Переместите курсор мыши на этот индикатор и вы увидите сообщение с количеством дней до момента удаления элемента данных.

2 Обнаружение сетевых интерфейсов
Обнаружение сетевых интерфейсов осуществляется таким же образом как и обнаружение файловых систем, за исключением того, что мы используем ключ правила обнаружения "net.if.discovery" вместо "vfs.fs.discovery" и макрос {#IFNAME} вместо {#FSNAME} в фильтре и в прототипах элементов данных/триггеров/графиков.
Примеры прототипов элементов данных, которые вы можете захотеть создать на основе "net.if.discovery": "net.if.in[{#IFNAME},bytes]", "net.if.out[{#IFNAME},bytes]".
3 Обнаружение нескольких SNMP OID'ов
В этом примере мы будем осуществлять обнаружение SNMP на коммутаторе. Сначала перейдем в "Настройка" → "Шаблоны".
Для редактирования правил обнаружения шаблона, щелкнем на ссылку в колонке "Обнаружение".
Теперь нажмем "Создать правило" и заполним форму так как представлено на скриншоте ниже:
В отличие от обнаружения файловых систем и сетевых интерфейсов - этот элемент данных не требует наличия ключа "snmp.discovery", а достаточно указать что тип элемента данных - SNMP агент.
Также в отличие от предыдущих примеров, этот элемент данных обнаружения будет генерировать два макроса для каждого обнаруженного объекта: {#SNMPINDEX} и {#SNMPVALUE}. В случае если вы хотите зафильтрровать loopback интерфейсы из возвращенных значений вам следует поместить "{#SNMPVALUE}" в фильтр "Макрос" и регулярное выражение "^([^l]|l$)[^o]?" в текстовое поле "Регулярное выражение". Смотрите выше для получения дополнительной информации об этом фильтре.
В поле "SNMP OID" мы должны вписать OID, который способен генерировать значения, поддающиеся интерпретации для макроса.
Чтобы понять что имеется ввиду, давайте осуществим snmpwalk на нашем коммутаторе:
$ snmpwalk -v 2c -c public 192.168.1.1 IF-MIB::ifDescr
IF-MIB::ifDescr.1 = STRING: WAN
IF-MIB::ifDescr.2 = STRING: LAN1
IF-MIB::ifDescr.3 = STRING: LAN2Макрос {#SNMPINDEX} возьмет свое значение из части OID, которая идет после ifDescr (в этом примере: 1, 2, 3). Макрос {#SNMPVALUE} возьмет свое значение из соответствующего значения OID (в этом примере: WAN, LAN1, LAN2). Таким образом, наш элемент данных "snmp.discovery" должен вернуть три набора пар макрос → значение:
{#SNMPINDEX} → 1 {#SNMPVALUE} → WAN
{#SNMPINDEX} → 2 {#SNMPVALUE} → LAN1
{#SNMPINDEX} → 3 {#SNMPVALUE} → LAN2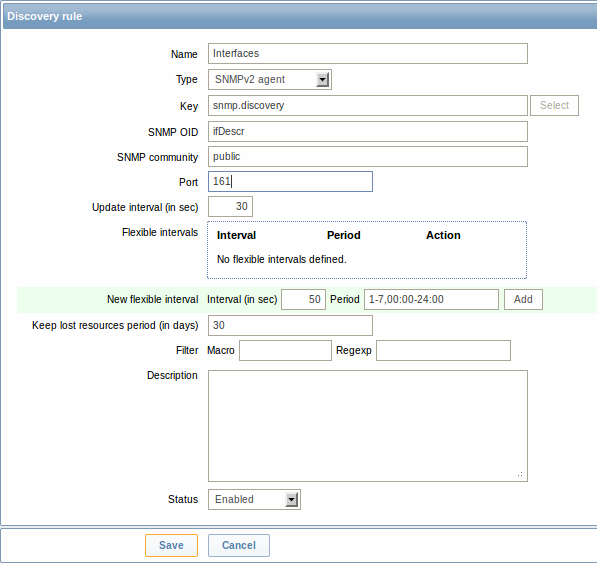
Представленный скриншот иллюстрирует как мы можем использовать эти макросы в прототипах элемента данных:
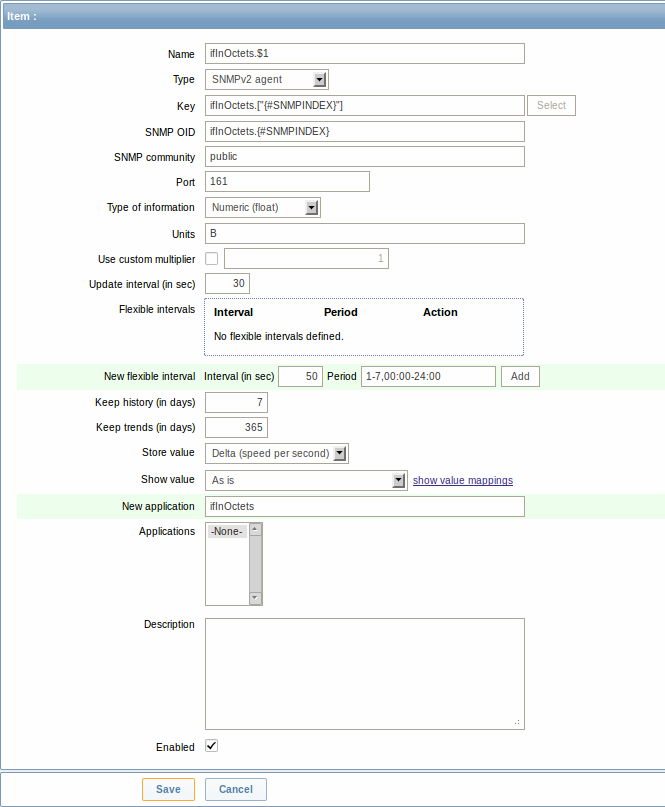
Опять же, создадим столько прототипов элемента данных, сколько нам необходимо:
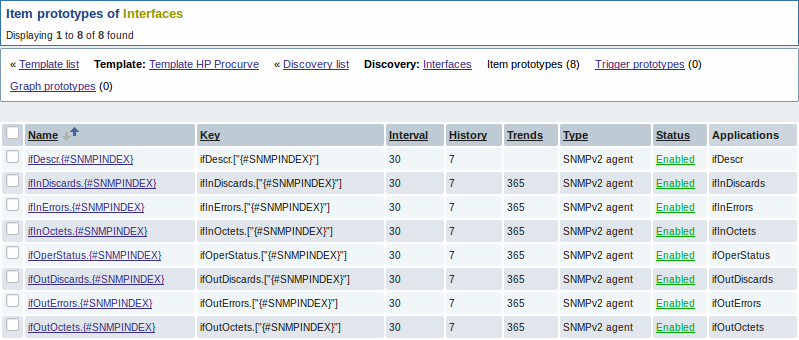
Также и прототипы триггера:
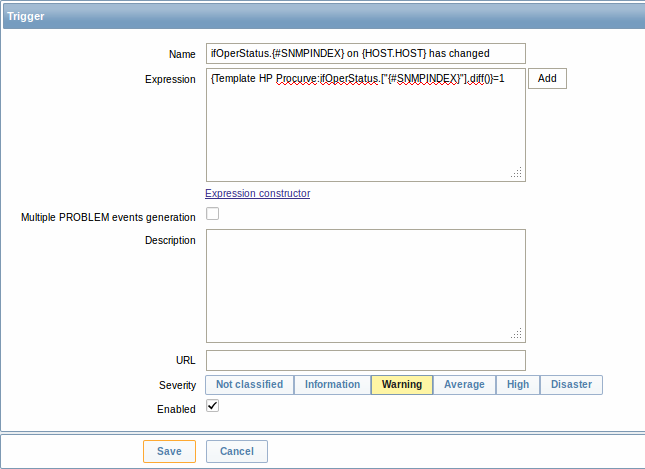
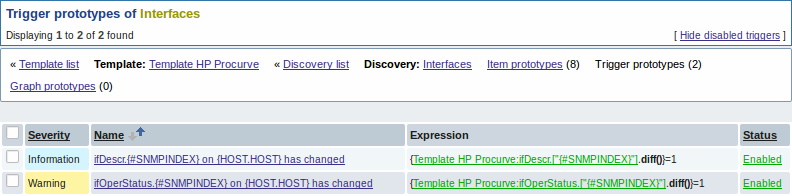
И прототипы графика:
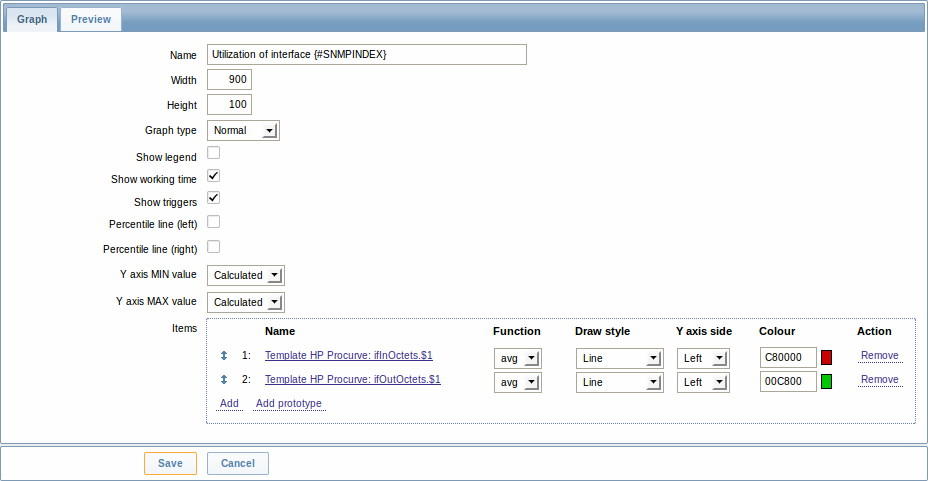
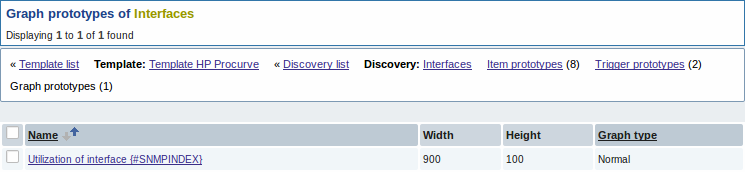
Результат нашего правила обнаружения:
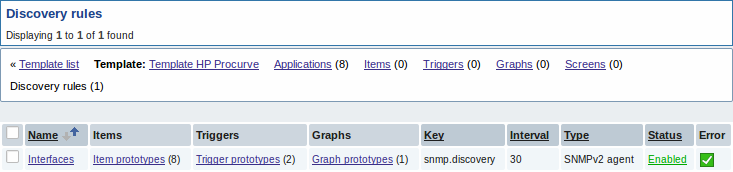
Когда сервер работает, он будет создавать реальные элементы данных, триггера и графики на основе значений, возвращаемых от "snmp.discovery". В настройках узлов сети они будут предварены префиксом-ссылкой золотистого цвета, которая ведет к правилу обнаружения, их создавшего.
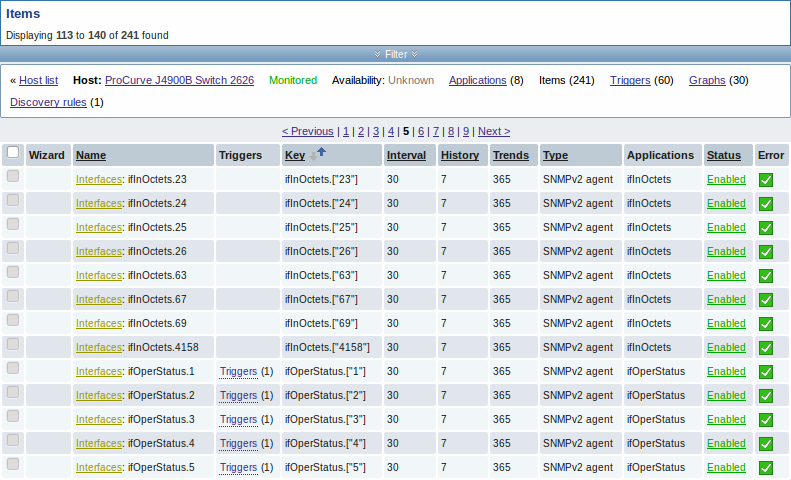
4 JSON формат обнаружения элемента данных
Требуемый JSON формат лучше всего иллюстрируется в примере. Предположим, что мы оставим старый Zabbix агент версии 1.8 (который не поддерживает "vfs.fs.discovery"), но нам также нужно обнаруживать файловые системы. Вот простой Perl скрипт для Linux, который обнаруживает смонтированные файловые системы и отдает на выходе JSON данные, в которых включено оба - и имя и тип файловой системы. Один из способов его использования это Пользовательский Параметр с ключем "vfs.fs.discovery_perl":
#!/usr/bin/perl
$first = 1;
print "{\n";
print "\t\"data\":[\n\n";
for (`cat /proc/mounts`)
{
($fsname, $fstype) = m/\S+ (\S+) (\S+)/;
$fsname =~ s!/!\\/!g;
print "\t,\n" if not $first;
$first = 0;
print "\t{\n";
print "\t\t\"{#FSNAME}\":\"$fsname\",\n";
print "\t\t\"{#FSTYPE}\":\"$fstype\"\n";
print "\t}\n";
}
print "\n\t]\n";
print "}\n";Пример его вывода (переформатирован для наглядности) представлен ниже. JSON данные от Пользовательских Параметров обнаружения должны придерживаться этого же формата.
{
"data":[
{ "{#FSNAME}":"\/", "{#FSTYPE}":"rootfs" },
{ "{#FSNAME}":"\/sys", "{#FSTYPE}":"sysfs" },
{ "{#FSNAME}":"\/proc", "{#FSTYPE}":"proc" },
{ "{#FSNAME}":"\/dev", "{#FSTYPE}":"devtmpfs" },
{ "{#FSNAME}":"\/dev\/pts", "{#FSTYPE}":"devpts" },
{ "{#FSNAME}":"\/", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"\/lib\/init\/rw", "{#FSTYPE}":"tmpfs" },
{ "{#FSNAME}":"\/dev\/shm", "{#FSTYPE}":"tmpfs" },
{ "{#FSNAME}":"\/home", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"\/tmp", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"\/usr", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"\/var", "{#FSTYPE}":"ext3" },
{ "{#FSNAME}":"\/sys\/fs\/fuse\/connections", "{#FSTYPE}":"fusectl" }
]
}Тогда, в правилах обнаружения в поле "Фильтр" мы можем указать "{#FSTYPE}" как макрос и "rootfs|ext3" как регулярное выражение.