
Template guidelines
To ensure Zabbix templates are easy to follow for users and developers alike, whenever possible, please follow the guidelines below.
The guidelines are organized by template elements and fields. Use the Table of Contents to navigate to the relevant section.
For additional details on the concepts discussed below, please consult Zabbix documentation.
See also: JavaScript coding guidelines
General best practices
-
A Zabbix template directory consists of a README file and one or more source files:
- Provide the template README file in
.mdformat. In addition to the present guidelines, use existing Zabbix template README files as guides for content, layout, and structure: Zabbix templates. - Provide the template source file in
.yamlformat.
- Provide the template README file in
-
Follow the naming guidelines to keep element names and keys descriptive and consistent. Pay particular attention to:
- Template-level guidelines
- Macros
- Items
- Triggers
- LLD rules
-
Use tags whenever possible:
-
Prefer collecting data via native APIs when they offer the same or broader metrics as other methods, unless specific requirements call for an alternative approach.
-
To reduce the number of requests to a device, collect data via a master item (storage period=0) and create dependent items with preprocessing steps to extract individual metrics (default storage period recommended). See more: Preprocessing
-
Use low-level discovery (LLD) to autodiscover hosts with the required items and triggers. See more: LLD rules
-
Template parameters are stored as Macros. For security reasons, use authentication tokens instead of a username and password. If tokens aren't an option and data collection requires authentication (username, password), follow the principle of least privilege to create a user named zbx_monitor and specify it in macros as well as the template description.
-
Set trigger dependencies to avoid duplicate alerts on the same item or overlapping states. See more: Triggers
-
Include at least one dashboard optimized for full HD (1920×1080) and relevant widgets. See more: Dashboards
Template
Name
-
Separate each word in the template name with a space.
-
Add the data collection method at the end of the name (e.g.,
by SNMP).- For templates using multiple data collection methods, either specify the primary or the most complex one.
Good examples:
Apache by HTTP
Linux by SNMP
Docker by Zabbix agent 2Bad examples:
HTTP template Apache
LinuxSNMP
Agent2 template DockerDescription
- Include short instructions on how to use the template. The instructions may be a simplified version of the
README.mdfile.
Template groups
-
Template groups use the
Templates/prefix for consistency and simpler permission management. -
Add the template to one of the groups below. If none of the groups apply, create a new one following the same convention.
Templates/ApplicationsTemplates/CloudTemplates/DatabasesTemplates/Network devicesTemplates/Operating systemsTemplates/PowerTemplates/SANTemplates/Server hardwareTemplates/TelephonyTemplates/Video surveillanceTemplates/Virtualization
Tags
-
Tags help categorize templates for easier organization and filtering.
-
Use one of the
classtags below to indicate the monitored entity type. If none of the tags apply, create a new one following the same convention.application- user-facing software (MS Exchange, Jenkins, GitLab)business- reserved for user-defined templatesdatabase- database management systems (MongoDB)device- embedded hardware and devices (phones, smart bulbs, video cameras)hardware- computer hardware (servers, workstations)network- network devices (hardware routers, switches, WLAN)os- operating systems (FreeBSD, Windows, Linux)power- power supply sources (APC UPS)service- external services and APIs (a bank's PSD2 API)software- system software and application platforms (VMware, Bind, Kubernetes)storage- network and attached storage (SANs, disk enclosures)voip- VOIP hardware or software including video conferencing (Asterisk, Cisco PBX)cloud- cloud systems (AWS, GCP)
-
Use at least one
targettag for the product name, brand name, or any other convenient reference.
Tag value format:
- Lowercase
- 255 characters max
- Recommended characters: a-z, 0-9, -, . (alphanumeric, hyphen, period)
- Use the hyphen to separate words (
cloud-region) - Use common nouns in the singular (
pipeline, notpipelines), unless the term is only used in the plural - Tag values may be left empty when representing a boolean condition
Examples for template Apache by HTTP:
class: software
subclass: webserver
target: apacheExamples for template Kubernetes API server by HTTP:
class: software
subclass: automation
subclass: containers
subclass: deploy
subclass: development
subclass: virtualization
target: api-server
target: kubernetesMacros
-
Use template-specific prefixes (namespaces) for macro names to avoid conflicts with other templates, as macros are template configuration parameters.
- Use context macros to differentiate similar macros across templates.
-
Use only widely accepted abbreviations—AVG (average), CERT (certificate), DB (database), MAX (maximum), etc. If your keyword has none, leave it in full.
-
Use the following suffixes for user macros in trigger expressions (thresholds):
.OK- for normal states (deviation from these is considered a problem); use only if the user might want to change it.WARN,.CRIT- for trigger thresholds with different problem event severity.MAX,.MIN,.HIGH,.LOW- for low/high-level thresholds depending on the metric, used functions, and trigger logic
Macro format:
- Uppercase only.
- Allowed character sets: A-Z, 0-9, _, . (uppercase alphanumeric, underscore, period).
- Use the period to mark the hierarchy level.
- Use the underscore for compound words.
Good examples:
{$APACHE.STATUS.HOST}
{$APACHE.RESPONSE_TIME.MAX.WARN}
{$MYSQL.HOST}
{$MYSQL.PORT}Bad examples:
{$STATUS.HOST}
{$APACHE.RESPONSE_T.MAXI.ALRT}
{$mysql/host}
{$MYSQL-PORT}
{$MYSQL.SLOW.QUERIES.MAX.WARN}Suggested macros:
- Authorization-related (use what's relevant):
{$CEPH.TOKEN},{$CEPH.USER},{$CEPH.PASSWORD} - Connection-related (use what's relevant):
{$CEPH.URL},{$CEPH.PORT},{$CEPH.SCHEME},{$CEPH.ENDPOINT} - For LLD filters (use both):
{$CEPH.PROJECT_NAME.MATCHES},{$CEPH.PROJECT_NAME.NOT_MATCHES}
Examples of macros for trigger expressions:
{$VFS.FS.INODE.PFREE.MIN.CRIT} = 10
{$VFS.FS.INODE.PFREE.MIN.WARN} = 20
{$DISK.ARRAY.CACHE.BATTERY.STATUS.OK} = 1
{$OPENSTACK.NOVA.INSTANCES.UTIL.HIGH} = 90-
Add descriptions to macros.
-
Store passwords, access tokens, and other sensitive data as secret text.
- Use plain text only when strictly required, and consider using a secret management tool such as Vault.
-
You may use user macros with context to set specific macro values for each entity during its discovery (LLD).
Items
Name
-
Keep item names as short as possible, simple, and descriptive.
-
Prefix item names with the resource (short name of template/service).
- For master items that retrieve data for dependent items, add the prefix
Getafter the resource name.
- For master items that retrieve data for dependent items, add the prefix
-
Use the colon (
:) to separate segments of the name. Use sentence case. -
Use suffixes to clarify the measurement (e.g.,
in %,per second)
Examples:
CockroachDB: Disk: Reads, rate
CockroachDB: Disk: Writes, rate
CockroachDB: Memory: Allocated by SQL
Nextcloud: PHP memory used, in %
Nextcloud: Get server informationKey
- Set item keys based on the metric or component names used by the monitored system. If needed, adjust to the key format below.
Key format:
- Begins with a letter
- Lowercase Latin alphabet
- 255 characters max (including parameters)
- Use the period to mark the hierarchy level between key elements:
namespace- often a short product reference (e.g.,nginx,pgsql,pgbouncer,docker)component- component/sub-resource of the monitored object; may be hierarchical (e.g.,upstream,pool,db,db.table,db.client,ecs.ephemeral.storage):- If the same service has several templates, use different component names (e.g.,
kubernetes.kubeletandkubernetes.controller).
- If the same service has several templates, use different component names (e.g.,
metric_name- final segment representing what's measured (e.g.,version,iops); use underscores for compound words (e.g.,max_reached,response_time).
- Use suffixes:
.getfor master items (e.g.,nomad.client.metrics.get).ratefor per-second metrics (e.g.,nginx.connections.accepted.rate).totalfor accumulators (e.g.,influxdb.buckets.total)- For SNMP items, specify the key from the MIB file and append static indexes, if applicable, in the parameters field (e.g.,
system.hw.uptime[hrSystemUptime.0])
Good examples:
azure.vm.data.disk.read.ops
azure.vm.data.disk.read.bps
azure.db.mssql.tempdb.log.size
openstack.nova.limits.ram.freeBad examples → Good examples (fixed by adding a common level of hierarchy):
aws.ec2.network_in.rate → aws.ec2.network.bytes.in.rate
aws.ec2.packets_in.rate → aws.ec2.network.packets.in.rateType of information
- Set based on the type of data to be stored in the database after performing conversions (if any):
| Type | Use for |
|---|---|
| Numeric (unsigned) | Non-negative integers (e.g., number of CPUs, disk count, inventory quantity) |
| Numeric (float) | Calculated items or fractions or negatives (e.g., CPU load percentage, temperature readings, memory usage) |
| Character | Short text, such as inventory details (e.g., serial numbers, model names, OS descriptions) |
| Log | Long text, optionally including log-related properties (e.g., timestamp, source, severity, logeventid). Note that Log type items are commonly used to store SNMP trap information as a fallback. |
| Text | Long text items (e.g., HTTP or Script item values, large data sets to be processed) |
Units
-
Provide units whenever possible.
-
Use base units (e.g., seconds, bytes) instead of scaled units (e.g., kilobytes, megabytes), since base units scale automatically.
-
To stop automatic scaling, use the exclamation mark, e.g.,
!rpsto preventKrps(kilorequests),!°Cto preventK°C(kilodegrees).
Update interval
-
Set the update interval according to the item type (e.g., 1m for health checks, 15m for inventory items).
-
Use time suffixes (
s,m,h,d). -
If needed, use custom intervals.
History
-
Keep the default history storage period whenever possible.
- For master items with unprocessed values, use
0. - For master items with unprocessed values and a linked trigger, use
1hinstead.
- For master items with unprocessed values, use
-
Use time suffixes (
s,m,h,d).
Trends
-
Keep the default trend storage period whenever possible.
- Don't store trends for items where they add no value (e.g., status items with only a few states).
-
Use time suffixes (
s,m,h,d).
Value mapping
-
Use value mapping for items with unclear values (e.g., 0 → Not Available, F → Full, <=209 → Low).
-
For SNMP items, set the value using the format
MIB::objectName, whereobjectNamematches the name defined in the MIB file.
Description
-
Explain why the item is important. Provide details on how the item collects data or how it can be configured.
-
To give an extended description, you may also borrow it from the vendor/service documentation. If relevant, provide reference to the documentation.
-
If applicable, add a list of possible item values; it should match the values used in value mapping.
Enabled
- Keep items enabled by default.
Tags
- Use at least one
componenttag with these values (if none apply to the metric type, use a different tag):cpudevicememorynetworkstoragepowerenvironmentossystem- low-level and system metrics unrelated to OS, unless a more specific component is definedapplicationraw- technical metric (e.g., a master item)business- internal information (e.g., number of company branches)kpi- internal information (e.g., monthly returned customers)sensor- internal information (e.g., pressure in a column still)
Tag value format:
- Lowercase
- 255 characters max
- Allowed character sets: a-z, 0-9, -, . (alphanumeric, hyphen, period)
- Use the hyphen to separate words (
cloud-region) - Use common nouns in the singular (
pipeline, notpipelines), unless the term is only used in the plural
Examples:
component: memory, component: storage (for 'Swap space' item)
component: raw (for Apache 'Get status' item )
component: requests, http-code: 2xx (for Kubernetes 'API server requests: 2xx, rate' item)Preprocessing
-
For items with rarely changing data (e.g., health checks, discrete states, textual/inventory data), use
Discard unchanged with heartbeat.- Skip this preprocessing if you rely on triggers that fire on absent data during the discard period, e.g.,
nodata(). - Always apply
Discard unchanged with heartbeatif the field is collected from a frequently polled master item.
- Skip this preprocessing if you rely on triggers that fire on absent data during the discard period, e.g.,
-
Convert coded string values into integers whenever possible (e.g., use
Boolean to decimalfor two-state values likeYES/NOorTRUE/FALSE) and apply value mappings.
Example JavaScript preprocessing to convert textual statuses to integers:
// 0 reserved for default value; element indexes start at 1
const idx = {
'PROVISIONING': 1,
'AVAILABLE': 2,
'STOPPING': 3,
'STOPPED': 4,
'STARTING': 5,
'TERMINATING': 6,
'TERMINATED': 7,
'RESTORE_IN_PROGRESS': 8,
'RESTORE_FAILED': 9,
'BACKUP_IN_PROGRESS': 10,
'SCALE_IN_PROGRESS': 11,
'AVAILABLE_NEEDS_ATTENTION': 12,
'UPDATING': 13,
'MAINTENANCE_IN_PROGRESS': 14,
'RESTARTING': 15,
'RECREATING': 16,
'ROLE_CHANGE_IN_PROGRESS': 17,
'UPGRADING': 18,
'UNAVAILABLE': 19,
'INACCESSIBLE': 20,
'STANDBY': 21
};
return typeof idx[value] === 'undefined' ? 0 : idx[value];Details on item types
Master item + dependent items
- Reuse master item values for dependent items and low-level discovery to minimize system and network load.
Calculated items
- Use newlines and spaces to make long formulas human-readable.
SNMP items
- Do not use MIB object names in the SNMP OID field; numeric OIDs ensure templates work without importing MIBs.
- Include the MIB object name from the MIB file as an item key parameter (append static indexes if needed) and in the item description.
- Do not use a leading
.in the OID.
Good example:
Key - system.cpu.util[sgiCpuUsage.0]
SNMP OID - 1.3.6.1.4.1.6527.3.1.2.1.1.1.0Bad example:
Key - system.cpu.util
SNMP OID - .1.3.6.1.4.1.6527.3.1.2.1.1.1.0HTTP agent and Script items
- Include a macro to allow setting an HTTP proxy (e.g.,
{$KUBE.HTTP.PROXY},{$NOMAD.HTTP.PROXY}).
Triggers
Name/Event name
-
Keep trigger names as short as possible, simple, and descriptive. Use suffixes to improve readability.
-
Prefix trigger name/event name with the resource (short name of template/service).
-
If needed, use the Event name field to include details (macros, thresholds, etc.); it will be used to generate the problem name.
- Tip: Use expression macros to display additional metrics or aggregations not included in the trigger expression.
-
Don't use
{ITEM.LASTVALUE1-9}macros in trigger/event names. These are resolved only at problem creation, so the problem name will not update afterward.- Tip: Use them in the Operational data field instead.
- Tip: Use
{ITEM.VALUE1-9}macros in the Event name or Operational data fields for "at-the-moment-of-event" data.
Good examples:
Trigger name - Apache: Version has changed
Event name - Apache: Version has changed (new version: {ITEM.VALUE})
Trigger name - MySQL: Refused connections
Event name - MySQL: Refused connections (max_connections limit reached)Bad examples:
Temperature is too high (now: 40)
- No template/service prefix.
- The static "now:" will confuse users, as the name will not change.
MySQL: Refused connections
- No need to duplicate the trigger name without additional details.Operational data
- Use to include data that might be helpful in data analysis.
Examples:
Desired: {ITEM.LASTVALUE2}, available: {ITEM.LASTVALUE3}
- Compare desired vs. available deployment replicas in Kubernetes.
In: {ITEM.LASTVALUE1}, out: {ITEM.LASTVALUE3}, speed: {ITEM.LASTVALUE2}
- Show current bandwidth utilization of a network interface.Severity
- Set according to the importance and urgency of the event, including expected reaction times where applicable:
| Severity | Use | Examples | Reaction time |
|---|---|---|---|
| Not classified | Avoid in default templates. | - | - |
| Info | Events useful for analysis or auditing. | Serial number has changed, User has logged in. | - |
| Warning | Minor alarms that could escalate if unattended. | Available disk space is low. | During working hours; no notification expected. |
| Average | Performance or fault alarms indicating serious issues or partial resource failure that could escalate if unattended. | CPU utilization high, Memory utilization high, High device temperature, Disk health failure in the disk array, Website is slow to respond. | During working hours; create an issue ticket if the problem stays for hours. |
| High | Performance or fault alarms where key services or devices are not available. | No ICMP ping (if allowed), TCP port unreachable, Website is down. | Outside working hours if it affects key services; contact the responsible person via call/SMS/messenger notification; react with a ticket during working hours. |
| Disaster | Avoid in default and resource-level (host-level) templates; reserved for service-level monitoring—alarms indicating blackouts, disasters, global business service faults. | Riga data center is down, Level core network is down, >50% of users cannot make an online payment. | Always react off working hours and contact the responsible person via call/SMS immediately. |
Expression
-
Avoid unnecessary complexity and use hysteresis (separate trigger and recovery thresholds) only if it adds value.
-
Use several recent values—e.g., last 3-5 values or values over the last 5-10 minutes—to make the trigger less sensitive to short spikes.
- Tip: For jumpy values, use
min()(for high-level thresholds) andmax()(for low-level thresholds) functions to smooth spikes. - Tip: For metrics that require attention on any change, use the
last()function.
- Tip: For jumpy values, use
-
Use user macros or context macros to allow threshold tuning, except for discrete states, where value mapping can be used. See more: Macros
-
Use newlines, spaces, and suffixes for values to improve readability.
Good examples:
min(/TEMPLATE_NAME/temperature, 5m)>{$TEMP.MAX.WARN}
avg(/TEMPLATE_NAME/temperature,10m)>{$TEMP.MAX.WARN}
avg(/TEMPLATE_NAME/memory.free,10m)<{$MEM_FREE.WARN}
- where {$MEM_FREE.WARN} = 100M`Bad examples:
last(/TEMPLATE_NAME/temperature)>30
- Static threshold that can only be changed by editing the trigger expression.
- Sensitive trigger due to only the last value being considered.
avg(/TEMPLATE_NAME/temperature,600)>{$TEMP.MAX.WARN}
- Time period with suffix (10m) might be used instead of seconds.
avg(/TEMPLATE_NAME/memory.free,600)<{$MEM_FREE.WARN}
- where {$MEM_FREE.WARN} = 104857600 (use 100M via macro instead of bytes)OK event generation
- Set the type based on how the event should be generated and resolved:
Expression- when the same trigger expression determines both PROBLEM and OK states.Recovery expression- when a separate expression should control when to resolve the problem.None- when the problem event should always require manual acknowledgment.
PROBLEM event generation mode
- Set to
Single(Multiplemode is case-specific, e.g., log file monitoring).
OK event closes
- Set to
All problems(All problems if tag values matchmode is case-specific, used for event correlation).
Allow manual close
- Enable for special cases (e.g., the OS description or an object's version changed and a manual acknowledgment is desired).
Description
-
Provide details on the problem. If possible, give the root cause and actions to be taken.
-
Explain why the problem is important to check.
-
If applicable, describe the principle of the trigger expression. Use suffixes to improve readability.
-
If applicable, provide references to relevant documentation.
Enabled
- Keep triggers enabled by default.
Tags
- Use at least one
scopetag with these values (if none apply to the problem type, use a different tag):performanceavailability- a monitoring target or a part of it may become unavailablecapacity- a monitored resource may be exhaustednoticesecuritycompliance- reserved for user-defined templates
Tag value format:
- Lowercase
- 255 characters max
- Allowed character sets: a-z, 0-9, -, . (alphanumeric, hyphen, period)
- Use the hyphen to separate words (
cloud-region) - Use common nouns in the singular (
pipeline, notpipelines), unless the term is only used in the plural
Examples:
scope: capacity, scope: performance (for 'Linux: Load average is too high' trigger)
scope: availability (for 'Apache: Service is down' trigger)Graphs
- Prefix graph names with the resource (short name of the template or service).
Dashboards
Each template should include at least one dashboard, optimized for Full HD (1920×1080).
Widget list
Use the following widgets:
-
Honeycomb - For visually mapping discovered or grouped entities.
- 1 (or more) per dashboard.
- Use item patterns to match discovered items (e.g.,
Node[*]: Statusfor status items on all nodes). - Use the
\{ITEM.NAME}.regsubfunction to extract a concise primary label for each cell.
-
Pie chart - For percentages of entities (up/down, running/standby, etc.).
- 1 per dashboard.
- Use item patterns to match discovered items (e.g., Data set #1 for running containers; Data set #2 for stopped containers).
-
Gauge - For percentage-based metrics.
- 3-5 per dashboard.
- Consider linking gauges to Item navigator and Item card widgets (see below).
-
Item value - For displaying the latest value of key metrics.
- 1-2 per dashboard.
- Use background colors for thresholds (e.g., red for offline status; green for online status).
-
Item navigator - For controlling the content of other widgets.
- 1 per dashboard if linking widgets.
- Use item patterns to match discovered items.
-
Item card - For a quick item overview (last check, value, link to configuration, status).
- 1 (or more) per dashboard if linking widgets.
-
Geomap - For displaying hosts on a map, with colors indicating each host's most severe problem.
- 1 per dashboard if the template has items that provide coordinates.
-
Problems/Problems by severity - For current problems filtered by different parameters (host groups, hosts, problem names, etc.).
- 1 of each (or both) per dashboard if the template has triggers.
-
Graph - For numeric items with a wide value range.
- Use item patterns to match discovered items (e.g.,
*utilizationfor CPU utilization, Memory utilization, and similar items).
- Use item patterns to match discovered items (e.g.,
-
Top items - For ranking percentage-based metrics.
- Use item patterns to match discovered items (e.g.,
Node[*]: CPU utilizationfor CPU utilization across all nodes).
- Use item patterns to match discovered items (e.g.,
-
Item history - For item latest data (e.g., browser item screenshots)
-
Trigger overview/Top triggers - For a summary of triggers.
-
URL - For content retrieved from the specified URL.
-
Host card - For dashboard visual enhancement, providing a quick host overview, link to host configuration, host status.
-
Clock - For dashboard visual enhancement, providing local, server, or host time in analog or digital format.
Widget colors
To ensure dashboards look good in both dark and light themes, use the default trigger severity colors (required for Zabbix official templates). You can freely combine these colors in any widgets, including those not related to trigger severities. These colors can be applied to Gauge, Pie chart, Graph, and any other widget that supports color customization.
| Color name | Code | Corresponding trigger severity |
|---|---|---|
| Grey | #97AAB3 | Not specified |
| Blue | #7499FF | Information |
| Green | #00C48C | OK |
| Yellow | #FFBF59 | Warning |
| Orange | #FFA059 | High |
| Red | #E45959 | Disaster |
Example
The screenshot below illustrates how the recommended colors can be applied. It shows a global dashboard — note that not all functionality is available on template dashboards.
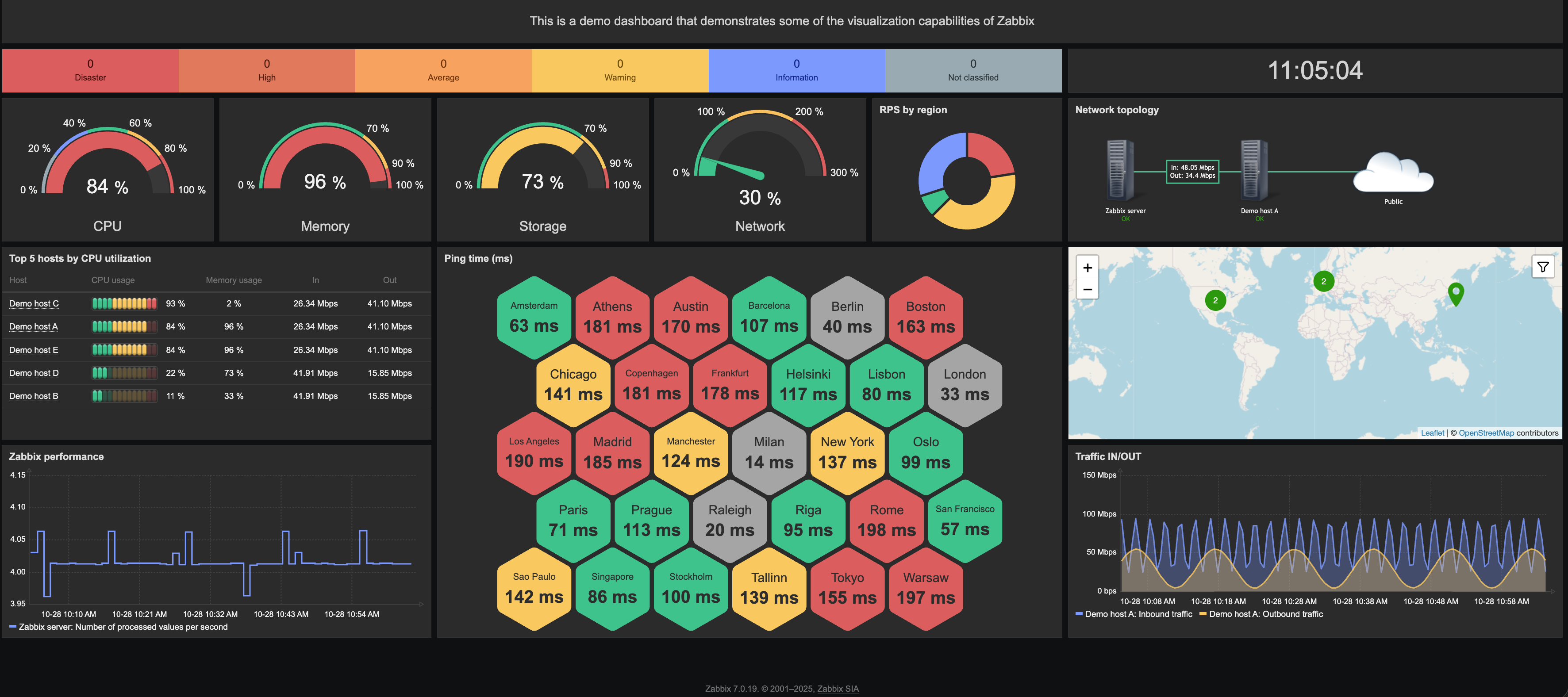
LLD rules
Name
-
Keep LLD rule names as short as possible, simple, and descriptive.
-
Always end with the word
discovery:
Good examples:
Network interface discovery
CPU core discoveryBad examples:
Network
Discovery of CPU coresKey
-
Always end the key with
.discovery(e.g.,gcp.cloudsql.pgsql.db.discovery). -
All other formatting rules for regular items also apply.
Update interval
- If the LLD rule has its own update interval, use the default
1h. Adjust as needed for specific cases.- If using
1h, theDiscard unchanged with heartbeatpreprocessing step may be skipped or adjusted to match the LLD rule frequency.
- If using
Delete lost resources
-
Use the default
7d; leaving it undefined will apply the default. -
For highly dynamic entities, it can be lowered or set to 0, but only with justification.
Description
- Explain why the LLD rule is important. Provide details on how the LLD rule collects data or how it can be configured.
Preprocessing
-
Use the
Discard unchanged with heartbeatpreprocessing step whenever possible. Start with a heartbeat of1hand adjust as needed. -
If LLD results contain frequently changing data, transform them to extract only LLD-related values, allowing
Discard unchanged with heartbeatto be applied effectively.
Example: a JSON retrieved from a master item with the vfs.fs.get key of Zabbix agent (truncated to 1 filesystem):
[
{
"fsname": "/",
"fstype": "ext4",
"bytes": {
"total": 19947929600,
"free": 15253876736,
"used": 3654811648,
"pfree": 80.671258,
"pused": 19.328742
},
"inodes": {
"total": 1248480,
"free": 1181988,
"used": 66492,
"pfree": 94.674164,
"pused": 5.325836
},
"options": "rw,relatime,errors=remount-ro"
}
]The result contains properties that change almost every time, so you can't apply Discard unchanged with heartbeat straight away.
Use the following JavaScript preprocessing in the LLD rule to modify it:
const filesystems = JSON.parse(value);
const result = filesystems.map(function (filesystem) {
return {
'fsname': filesystem.fsname,
'fstype': filesystem.fstype
};
});
return JSON.stringify(result);This will result in a JSON that contains only the data related to LLD.
Now, you can apply Discard unchanged with heartbeat as a next step:
[
{
"fsname": "/",
"fstype": "ext4"
}
]LLD macros
- Use to extract LLD macros from LLD data. In some cases, you can declare them directly in preprocessing steps (e.g., in JavaScript), but stick to using LLD macros whenever possible.
Filters
- Use user macros. Avoid global macros. See more: Macros
Good example:
{#IFNAME} MATCHES {$NET.IF.IFNAME.MATCHES} AND {#IFNAME} NOT_MATCHES {$NET.IF.IFNAME.NOT_MATCHES}
- where {$NET.IF.IFNAME.MATCHES} = ^.*$
- and {$NET.IF.IFNAME.NOT_MATCHES} = (^Software Loopback Interface|^NULL[0-9.]*$|^[Ll]o[0-9.]*$| ^[Ss]ystem$|^Nu[0-9.]*$)Bad example:
{#IFNAME} MATCHES "@Network interfaces for discovery"-
If needed, specify static values.
-
If you have multiple LLD rules that discover related objects (like network interfaces, filesystems, or disks) and they share the same LLD macros (for example, {#IFNAME} for interface names), apply consistent filters across all of them.
Overrides
- Use when you want to modify a configured prototype (item, trigger, etc.) when discovered objects meet specific criteria.
Example: A storage system might have a metric showing the predicted lifetime of a drive (usually an SSD):
{
"data": [
{
"{#SYSTEM_HOSTNAME}": "server01",
"{#STORAGE_ID}": "1",
"{#DRIVE_ID}": "1",
"{#DRIVE_TYPE}": "SSD",
"{#PREDICTED_MEDIA_LIFE_LEFT}": "87"
},
{
"{#SYSTEM_HOSTNAME}": "server01",
"{#STORAGE_ID}": "1",
"{#DRIVE_ID}": "2",
"{#DRIVE_TYPE}": "HDD",
"{#PREDICTED_MEDIA_LIFE_LEFT}": "N/A"
},
{
"{#SYSTEM_HOSTNAME}": "server01",
"{#STORAGE_ID}": "2",
"{#DRIVE_ID}": "1",
"{#DRIVE_TYPE}": "SSD",
"{#PREDICTED_MEDIA_LIFE_LEFT}": "93"
}
]
}You can create the following override so that items from item prototypes are created only when the discovered drive is an SSD:
Item prototype name - HPE iLO: Computer system [{#SYSTEM_HOSTNAME}]: Storage [{#STORAGE_ID}]: Drive [{#DRIVE_ID}]: Predicted media life left, in %
Discover - Disabled
LLD rule override name - Predicted media life left
Filter - {#DRIVE_TYPE} matches SSD
Operation:
Condition - Item prototype matches Predicted media life left
Discover - YesItem prototypes
- Item prototypes inherit all the rules from regular items and have some of their own listed below.
Name
-
Prefix names of item prototypes with the entity the discovered item will belong to (except in singleton discovery).
-
Use square brackets to specify discovered entities.
Examples:
Kubernetes: Namespace [{#NAMESPACE}]: Pod [{#NAME}]: Ready
Jenkins: Computer [{#DISPLAY_NAME}]: StateKey
- Always end the key with square brackets containing LLD macros.
- Use macros that guarantee unique keys for discovered items (e.g., a unique ID such as the SNMP index in SNMP templates, or a combination of LLD macros).
- If the key requires parameters, enclose the macro in double quotes.
Examples without quotes:
jenkins.computer.idle[{#DISPLAY_NAME}]
velocloud.sdwanpath.packets_rx[{#NAME}/{#SOURCE}/{#DESTINATION}]
system.cpu.idle[ssCpuRawIdle.{#SNMPINDEX}]Examples with quotes:
vmware.alarms.status["{#VMWARE.ALARMS.KEY}"]
db.odbc.select[pgsql.db.age,,"Database={#DBNAME};{$PG.CONNSTRING.ODBC}"]
mongodb.collection.stats["{$MONGODB.CONNSTRING}","{$MONGODB.USER}","{$MONGODB.PASSWORD}","{#DBNAME}","{#COLLECTION}"]- If item prototypes need to gather data from a master item outside the LLD rule, create an intermediate master item for the discovered entity. Make the other prototypes dependent on this item.
Tags
-
You can use custom keys and values in item prototype tags.
-
Include LLD macros in tag values to simplify data filtering.
Tag value format:
- Lowercase
- 255 characters max
- Allowed character sets: a-z, 0-9, -, . (alphanumeric, hyphen, period)
- Use the hyphen to separate words (
cloud-region) - Use common nouns in the singular (
pipeline, notpipelines), unless the term is only used in the plural - Values inherited from LLD macros might not follow these requirements, yet this is normal and expected.
Examples:
component: storage, disk: {#DEVNAME} (for '{#DEVNAME}: Disk utilization' item prototype)
component: datastore, datastore: {#DATASTORE}, type: {#DATASTORE.TYPE} (for 'Total size of datastore [{#DATASTORE}]' item prototype)Discovery
- If needed, disable and use LLD rule overrides to enable discovery for specific discovered entities.
Trigger prototypes
- Trigger prototypes inherit all the rules from regular triggers and have some of their own listed below.
Name
-
Prefix names of trigger prototypes with the entity the discovered trigger will belong to (except in singleton discovery).
-
Use square brackets to specify discovered entities.
Examples:
Kubernetes: NS [{#NAMESPACE}] PVC [{#NAME}]: PVC is pending
Jenkins: Computer [{#DISPLAY_NAME}]: Node is downExpression
- Use user macros with context to enable flexible threshold tuning for individual LLD entities.
Graph prototypes
Name
-
Graph prototypes inherit all the rules from regular graphs and have some of their own listed below.
-
Prefix names of graph prototypes with the entity the discovered graph will belong to (except in singleton discovery).
-
Use square brackets to specify discovered entities.
Examples:
Tenant [{#TENANT_ID}]: Total disk utilization
Azure Cost: ["{#AZURE.RESOURCE.GROUP}"]: Month ["{#AZURE.BILLING.MONTH}"] costSingleton discovery
-
Use the singleton discovery pattern to find a single entity that either exists or does not exist at all.
- If the entity exists, an item will be created for it, which will then collect data.
- This keeps templates clean and avoids unsupported items on hosts with different configurations.
-
To use the singleton discovery pattern:
- Create an LLD rule using a regular item or dependent item that returns a value not in LLD format (e.g., the string
foundormissing). - In the LLD rule, use preprocessing to check the received value; if it meets your conditions, create an LLD array of length 1 containing an empty
{#SINGLETON}macro using JavaScript:
- Create an LLD rule using a regular item or dependent item that returns a value not in LLD format (e.g., the string
return JSON.stringify(value === 'found' ? [{'{#SINGLETON}': ''}] : []);-
How to use the
{#SINGLETON}macro:- Place it inside square brackets of all item prototype keys, e.g.,
consul.raft.state_leader[{#SINGLETON}] - Append it to all graph prototype names, e.g.,
Apache: Current async connections{#SINGLETON}
- Place it inside square brackets of all item prototype keys, e.g.,
-
Item and trigger prototype names do not need the
{#SINGLETON}macro; after discovery, the macro expands only in graphs, leaving item and trigger names clean and identical to statically defined names.