
- - #6 Monitoramento de arquivos de Log
- #6 Monitoramento de arquivos de Log
Visão geral
O Zabbix pode ser utilizado como para monitoração e análise centralizada de arquivos de log, com ou sem suporte a rotação.
As notificações podem ser utilizadas para avisar os usuários quando um arquivo de log contêm determinados textos ou padrões de texto.
Para monitorar um log você precisa:
- de um Zabbix Agent em execução no host
- configurar um item de monitoramento de log
O tamanho limite de um arquivo a ser monitorado depende do suporte a arquivos grandes.
Configuração
Verificação dos parâmetros do agente
Certifique-se que o arquivo de configuração do agente tenha, no mínimo, os parâmetros a seguir devidamente configurados:
- O parâmetro 'Hostname' deverá estar igual ao campo Nome no host configurado na interface web do Zabbix
- O parâmetro 'ServerActive' esteja definido apropriadamente para permitir o processamento de verificações ativas
Configuração do item
Para configurar um item de monitoração de log:
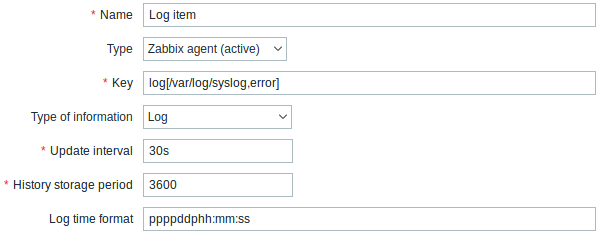
Você deverá preencher alguns campos específicos:
| Tipo | Selecione Agente Zabbix (ativo). |
| Chave | Defina como: log[/caminho/para/o/arquivo,<regexp>,<encoding>,<maxlines>,<mode>,<output>] ou logrt[/caminho/para/o/arquivo/expressao_regular_do_padrao,<regexp>,<encoding>,<maxlines>,<mode>,<output>] O Zabbix Agent irá filtrar as entradas no arquivo de log pelo conteúdo da expressão regular, se informado. Certifique-se que o usuário 'zabbix' tem permissões de acesso para ler o arquivo, a ausência destas fará com que o arquivo fique como 'não suportado'. Para maiores detalhes veja as entradas log e logrt na seção de chaves da lista de itens do Zabbix Agent. |
| Tipo da informação | Tipo do dado de Log. Se o parâmetro opcional output for informado, você poderá selecionar um tipo apropriado de informação que não seja o "Log".Observe que ao selecionar um tipo diferente de "Log" o dado salvo não terá a informação de data e hora. |
| Intervalo entre atualizações (em segundos) | Este parâmetro define de quanto em quanto tempo o Zabbix irá verificar se existem alterações no arquivo de log. O menor valor é 1 segundo. |
| Formato de data no log | Com este campo você pode, de forma opcional, definir o padrão para análise de data e hora no log. Se for deixado em branco, os dados de data e hora não serão analisados. Máscara suportada: * y: Ano (0001-9999) * M: Mês (01-12) * d: Dia (01-31) * h: Hora (00-23) * m: Minuto (00-59) * s: Segundo (00-59) Por exemplo, considere a linha a seguir do log do Zabbix Agent: " 23480:20100328:154718.045 Zabbix agent started. Zabbix 1.8.2 (revision 11211)." Ela começa com seis caracteres para o PID, seguidos de uma data, hora e o resto da linha. A máscara desta linha pode ser definida como "pppppp:yyyyMMdd:hhmmss". Observe que os caracteres "p" e ":" são espaços reservados que podem conter qualquer coisa, ao contrário de "yMdhms". |
Notas importantes
- O Zabbix Server/Agent mantêm a informações sobre o tamanho e última modificação (para o logrt) dos logs monitorados em dois contadores. Adicionalmente:
<!-- --> * O agente também utiliza internamente os números de inodes (em UNIX/GNU/Linux), índices de arquivos (no Microsoft Windows) e sumarização MD5 dos primeiros 512 bytes do arquivo de log para acelerar a detecção de arquivos de log truncados ou rotacionados.
* Em ambiente UNIX/GNU/Linux é assumido que os sistemas de arquivos onde os logs estão armazenados informem o número do inode, através do qual o arquivo será rastreado.
* Em ambiente Windows o agente determina o tipo do sistema de arquivos onde o arquivo de log está e usa:
* Em sistema de arquivo NTFS de 64-bit a indexação de arquivo.
* Em sistema de arquivo ReFS (apenas no Windows Server 2012) usa a identificação de 128-bit do arquivo.
* Em sistema de arquivo onde os índices mudam (Ex. FAT32, exFAT) um algorítimo de retorno é utilizado para melhorar a detecção quando vários arquivos de log possuem a mesma data de modificação.
* Os números de inode, índices de arquivo e sumarização MD5 são coletados internamente pelo Zabbix Agent. Eles não são transmitidos para o Zabbix Server e tais informações são perdidas quando a execução do agente é finalizada.
* Não altere a data de última modificação dos aquivos de log com utilitários de "toque", não copie um arquivo de log com data de restauração anterior do que o original (isso irá alterar o número do inode). Em ambos os casos o arquivo será considerado diferente e será analisado, possivelmente resultando em alertas duplicados.
* Se existirem vários arquivos de log compatíveis com o item ''logrt[]'' e o Zabbix Agent estiver acompanhando o arquivo mais recente e este for excluído, será registrada uma mensagem de aviso ''"there are no files matching "<regexp mask>" in "<directory>"''. O Zabbix Agent irá ignorar os arquivos de log com data de última modificação menor do que o valor mais recente visto pelo item de ''logrt[]''.
* O agente inicia lendo o arquivo de log a partir do local lido pela última vez.
* A quantidade de bytes já analisada (tamanho do contador) e o momento da última modificação (o contador de hora) são armazenados no banco de dados do Zabbix e enviados para o agente para garantir que a leitura dos logs comece a partir deste ponto quando o agente for iniciado, reabilitado ou o item deixar de ser 'não suportado'.
* Sempre que o arquivo de log tornar-se menor do que o último valor conhecido pelo agente o contador no lado do agente é zerado e o arquivo é analisado desde o seu início.
* Se existirem vários arquivos correspondentes e com o mesmo momento de alteração no diretório monitorado o agente tentará ler todos os aquivos e evitar duplicidades, embora não seja possível garantir isso. O agente não irá presumir nenhum método de rotação de arquivos, simplesmente os lerá em ordem decrescente. Assim, para alguns esquemas de rotação de arquivos de log, os dados serão analisados e relatados em sua ordem original. Para outros esquemas de rotação a ordem dos arquivos originais poderão não ser respeitada (o que não ocorrerá se os arquivos tiverem datas de modificação diferentes).
* O Zabbix Agent processa os novos registros de um arquivo de log respeitando o //Intervalo de atualização// em segundos.
* O Zabbix Agent, a cada segundo, não enviará mais linhas do que o definido pelo parâmetro **maxlines**. Esta característica visa evitar sobrecarga de CPU e rede e tem prioridade sobre o definido no parâmetro **MaxLinesPerSecond** do [[pt:manual:appendix:config:zabbix_agentd|arquivo de configuração do agente]].
* Para localizar o texto desejado o Zabbix irá processar 4 vezes mais linhas do que o definido em MaxLinesPerSecond. Assim, por exemplo, se um item de ''log[]'' ou ''logrt[]'' possui um //Intervalo de Atualização// de 1 segundo, por padrão o Agente analisará não mais que 80 linhas no log e enviará não mais que 20 linhas compatíveis para o Zabbix Server por verificação. Ao incrementar o parâmetro **MaxLinesPerSecond** no lado do agente ou definindo o parâmetro **maxlines** na chave do agente, o limite poderá ser incrementado em até 4000 linhas analisadas e 1000 linhas enviadas para o Zabbix Server por verificação.
* Adicionalmente, os valores analisados sempre estarão limitados a 50% do tamanho do buffer do agente, mesmo se o espaço estiver ocupado por valores não relacionados a log. Então, para os valores definidos em **maxlines** serem enviados em apenas uma conexão (e não em várias), o parâmetro [[pt:manual:appendix:config:zabbix_agentd|BufferSize]] do agente deverá ser no mínimo duas vezes superior à quantidade de linhas.
* Na ausência de itens de log, todo o buffer do agente estará disponível para itens não relacionados à log. Quando vierem novos valores de log os mesmos substituirão os demais valores no buffer até o liite de 50%.
* Para registros de log superiores a 256kB, apenas os primeiros 256kB serão analisados pela expressão regular e o restante será ignorado. Contudo, se o Zabbix Agent parar enquanto está tratando um registro muito grande o estado interno do agente será perdido e o registro terá que ser analisado novamente quando o agente for iniciado.
* Observação especial os separadores de caminho "\": se o formato de arquivo for "arquivo\.log", então o "arquivo" não poderá ser um diretório, uma vez que não é possível distinguir quando o "." está escapado ou se é o primeiro caracter do arquivo.
* As expressões regulares para a chave ''logrt'' são suportadas apenas no nome do arquivo, expressões regulares no nome de diretório não são suportadas.
* Em plataformas UNIX um item com a chave ''logrt[]'' passa a ser 'não suportado' se diretório dos arquivos de log não existir.
* Ao contrário do que ocorre no UNIX, nas plataformas Microsoft Windows, se o diretório não existir o item não irá passar para o estado de 'não suportado' (por exemplo, se o diretório for escrito errado na chave).
* A ausência de arquivos de log para a análise não irá fazer que um item que utiliza a chave ''logrt[]'' passe para o estado 'não suportado'. Erros de leitura em arquivos de log serão registrados como alerta nos logs do Zabbix Agent apenas.
* O arquivo de log do Zabbix Agent pode ser muito útil para descobrir o motivo pelo qual um item de ''log[]'' ou ''logrt[]'' passou para o estado 'não suportado'.O Zabbix Agent pode monitorar o seu próprio log, exceto se o nível de debug estiver como 'DebugLevel=4'.Extraindo a parte compatível de uma expressão regular
Algumas vezes você precisa extrair apenas uma parte de uma linha do log, ao invés de obter a linha toda.
Desde o Zabbix 2.2.0, os itens de log tem a capacidade de extrair apenas
a parte relevante das linhas compatíveis. Isso pode ser feito ao
utilizar o parâmetro opcional output nos itens log e logrt.
output permite indicar um subgrupo da parte compatível que pode ser de
interesse.
Então, por exemplo
log[/path/to/the/file,"large result buffer allocation.*Entries: ([0-9]+)",,,,\1]irá retornar apenas o contador encontrado em:
Fr Feb 07 2014 11:07:36.6690 */ Thread Id 1400 (GLEWF) large result
buffer allocation - /Length: 437136/Entries: 5948/Client Ver: >=10/RPC
ID: 41726453/User: AUser/Form: CFG:ServiceLevelAgreementO motivo pelo qual o Zabbix retorna somente o número é por que o
parâmetro output está definido como \1, se referenciando o
primeiro e único grupo de interesse: ([0-9]+)
E, com a habilidade de extrair e retornar um número, o valor pode ser utilizado para definir triggers.
Using maxdelay parameter
The 'maxdelay' parameter in log items allows ignoring some older lines from log files in order to get the most recent lines analyzed within the 'maxdelay' seconds.
Specifying 'maxdelay' > 0 may lead to ignoring important log file records and missed alerts. Use it carefully at your own risk only when necessary.
By default items for log monitoring follow all new lines appearing in
the log files. However, there are applications which in some situations
start writing an enormous number of messages in their log files. For
example, if a database or a DNS server is unavailable, such applications
flood log files with thousands of nearly identical error messages until
normal operation is restored. By default, all those messages will be
dutifully analyzed and matching lines sent to server as configured in
log and logrt items.
Built-in protection against overload consists of a configurable 'maxlines' parameter (protects server from too many incoming matching log lines) and a 4*'maxlines' limit (protects host CPU and I/O from overloading by agent in one check). Still, there are 2 problems with the built-in protection. First, a large number of potentially not-so-informative messages are reported to server and consume space in the database. Second, due to the limited number of lines analyzed per second the agent may lag behind the newest log records for hours. Quite likely, you might prefer to be sooner informed about the current situation in the log files instead of crawling through old records for hours.
The solution to both problems is using the 'maxdelay' parameter. If 'maxdelay' > 0 is specified, during each check the number of processed bytes, the number of remaining bytes and processing time is measured. From these numbers the agent calculates an estimated delay - how many seconds it would take to analyze all remaining records in a log file.
If the delay does not exceed 'maxdelay' then the agent proceeds with analyzing the log file as usual.
If the delay is greater than 'maxdelay' then the agent ignores a chunk of a log file by "jumping" over it to a new estimated position so that the remaining lines could be analyzed within 'maxdelay' seconds.
Note that agent does not even read ignored lines into buffer, but calculates an approximate position to jump to in a file.
The fact of skipping log file lines is logged in the agent log file like this:
14287:20160602:174344.206 item:"logrt["/home/zabbix32/test[0-9].log",ERROR,,1000,,,120.0]"
logfile:"/home/zabbix32/test1.log" skipping 679858 bytes
(from byte 75653115 to byte 76332973) to meet maxdelayThe "to byte" number is approximate because after the "jump" the agent adjusts the position in the file to the beginning of a log line which may be further in the file or earlier.
Depending on how the speed of growing compares with the speed of analyzing the log file you may see no "jumps", rare or often "jumps", large or small "jumps", or even a small "jump" in every check. Fluctuations in the system load and network latency also affect the calculation of delay and hence, "jumping" ahead to keep up with the "maxdelay" parameter.
Setting 'maxdelay' < 'update interval' is not recommended (it may result in frequent small "jumps").
Notes on handling 'copytruncate' log file rotation
logrt with the copytruncate option assumes that different log files
have different records (at least their timestamps are different),
therefore MD5 sums of initial blocks (up to the first 512 bytes) will be
different. Two files with the same MD5 sums of initial blocks means that
one of them is the original, another - a copy.
logrt with the copytruncate option makes effort to correctly process
log file copies without reporting duplicates. However, things like
producing multiple log file copies with the same timestamp, log file
rotation more often than logrt[] item update interval, frequent
restarting of agent are not recommended. The agent tries to handle all
these situations reasonably well, but good results cannot be guaranteed
in all circumstances.
Notes on persistent files for log*[] items
Purpose of persistent files
When Zabbix agent is started it receives a list of active checks from Zabbix server or proxy. For log*[] metrics it receives the processed log size and the modification time for finding where to start log file monitoring from. Depending on the actual log file size and modification time reported by file system the agent decides either to continue log file monitoring from the processed log size or re-analyze the log file from the beginning.
A running agent maintains a larger set of atributes for tracking all monitored log files between checks. This in-memory state is lost when the agent is stopped.
The new optional parameter persistent_dir specifies a directory for storing this state of log[], log.count[], logrt[] or logrt.count[] item in a file. The state of log item is restored from the persistent file after the Zabbix agent is restarted.
The primary use-case is monitoring of log file located on a mirrored file system. Until some moment in time the log file is written to both mirrors. Then mirrors are split. On the active copy the log file is still growing, getting new records. Zabbix agent analyzes it and sends processed logs size and modification time to server. On the passive copy the log file stays the same, well behind the active copy. Later the operating system and Zabbix agent are rebooted from the passive copy. The processed log size and modification time the Zabbix agent receives from server may not be valid for situation on the passive copy. To continue log file monitoring from the place the agent left off at the moment of file system mirror split the agent restores its state from the persistent file.
Agent operation with persistent file
On startup Zabbix agent knows nothing about persistent files. Only after receiving a list of active checks from Zabbix server (proxy) the agent sees that some log items should be backed by persistent files under specified directories.
During agent operation the persistent files are opened for writing (with fopen(filename, "w")) and overwritten with the latest data. The chance of losing persistent file data if the overwriting and file system mirror split happen at the same time is very small, no special handling for it. Writing into persistent file is NOT followed by enforced synchronization to storage media (fsync() is not called).
Overwriting with the latest data is done after successful reporting of matching log file record or metadata (processed log size and modification time) to Zabbix server. That may happen as often as every item check if log file keeps changing.
After receiving a list of active checks the agent scans persistent file directory and removes obsolete persistent files. Removing is done with delay 24 hours because log files in NOTSUPPORTED state are not included in the list of active checks but they may become SUPPORTED later and their persistent files will be useful. If agent is stopped and started again before 24 hours expire, then the obsolete files will not be deleted as Zabbix agent is not getting info about their location from Zabbix server anymore.
No special actions during agent shutdown.
After receiving a list of active checks the agent marks obsolete persistent files for removal. A persistent file becomes obsolete if: 1) the corresponding log item is no longer monitored, 2) a log item is reconfigured with a different persistent_dir location than before.
Removing is done with delay 24 hours because log files in NOTSUPPORTED state are not included in the list of active checks but they may become SUPPORTED later and their persistent files will be useful.
If the agent is stopped before 24 hours expire, then the obsolete files will not be deleted as Zabbix agent is not getting info about their location from Zabbix server anymore.
Reconfiguring a log item's persistent_dir back to the old persistent_dir location while the agent is stopped, without deleting the old persistent file by user - will cause restoring the agent state from the old persistent file resulting in missed messages or false alerts.
Naming and location of persistent files
Zabbix agent distinguishes active checks by their keys. For example, logrt[/home/zabbix/test.log] and logrt[/home/zabbix/test.log,] are different items. Modifying the item logrt[/home/zabbix/test.log,,,10] in frontend to logrt[/home/zabbix/test.log,,,20] will result in deleting the item logrt[/home/zabbix/test.log,,,10] from the agent's list of active checks and creating logrt[/home/zabbix/test.log,,,20] item (some attributes are carried across modification in frontend/server, not in agent).
The file name is composed of MD5 sum of item key with item key length appended to reduce possibility of collisions. For example, the state of logrt[/home/zabbix50/test.log,,,,,,,,/home/zabbix50/agent_private] item will be kept in persistent file c963ade4008054813bbc0a650bb8e09266.
Multiple log items can use the same value of persistent_dir.
persistent_dir is specified by taking into account specific file system layouts, mount points and mount options and storage mirroring configuration - the persistent file should be on the same mirrored filesystem as the monitored log file.
If persistent_dir directory cannot be created or does not exist, or access rights for Zabbix agent does not allow to create/write/read/delete files the log item becomes NOTSUPPORTED.
If access rights to persistent storage files are removed during agent operation or other errors occur (e.g. disk full) then errors are logged into the agent log file but the log item does not become NOTSUPPORTED.
Load on I/O
Item's persistent file is updated after successful sending of every batch of data (containing item's data) to server. For example, default 'BufferSize' is 100. If a log item has found 70 matching records then the first 50 records will be sent in one batch, persistent file will be updated, then remaining 20 records will be sent (maybe with some delay when more data is accumulated) in the 2nd batch, and the persistent file will be updated again.
Actions if communication fails between agent and server
Each matching line from log[] and logrt[] item and a result of each
log.count[] and logrt.count[] item check requires a free slot in the
designated 50% area in the agent send buffer. The buffer elements are
regularly sent to server (or proxy) and the buffer slots are free again.
While there are free slots in the designated log area in the agent send buffer and communication fails between agent and server (or proxy) the log monitoring results are accumulated in the send buffer. This helps to mitigate short communication failures.
During longer communication failures all log slots get occupied and the following actions are taken:
log[]andlogrt[]item checks are stopped. When communication is restored and free slots in the buffer are available the checks are resumed from the previous position. No matching lines are lost, they are just reported later.log.count[]andlogrt.count[]checks are stopped ifmaxdelay = 0(default). Behavior is similar tolog[]andlogrt[]items as described above. Note that this can affectlog.count[]andlogrt.count[]results: for example, one check counts 100 matching lines in a log file, but as there are no free slots in the buffer the check is stopped. When communication is restored the agent counts the same 100 matching lines and also 70 new matching lines. The agent now sends count = 170 as if they were found in one check.log.count[]andlogrt.count[]checks withmaxdelay > 0: if there was no "jump" during the check, then behavior is similar to described above. If a "jump" over log file lines took place then the position after "jump" is kept and the counted result is discarded. So, the agent tries to keep up with a growing log file even in case of communication failure.