
- 6 Мониторинг файлов журналов
6 Мониторинг файлов журналов
Обзор
Zabbix можно использовать для централизованного мониторинга и анализа файлов журналов с/без поддержки ротации журналов.
Можно использовать оповещения для предупреждения пользователей, когда файл журнала содержит конкретные строки или шаблоны строк.
Для наблюдения за файлом журнала у вас должно быть:
- Работающий Zabbix агент на узле сети
- Настроенный элемент данных для мониторинга журнала
Максимальный размер наблюдаемого файла журнала зависит от поддержки файлов большого объема.
Настройка
Проверка параметров агента
Убедитесь, что в файле конфигурации агента:
- Параметр 'Hostname' совпадает с именем узла сети в веб-интерфейсе
- Указаны сервера в параметре 'ServerActive' для обработки активных проверок
Настройка элемента данных
Настройте элемент данных для мониторинга журнала.
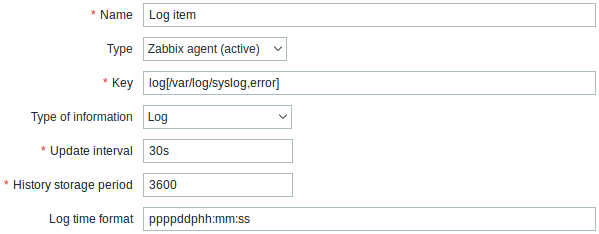
Все обязательные поля ввода отмечены красной звёздочкой.
Специально для элементов данных наблюдения за журналами вы должны указать:
| Тип | Здесь выберите Zabbix агент (активный). |
| Ключ | Укажите: log[/путь/к/файлу/имя_файла,<регулярное выражение>,<кодировка>,<макс. кол-во строк>,<режим>,<вывод>,<максзадержка>] или logrt[/путь/к/файлу/регулярное_выражение_описывающее_шаблон_имени_файла,<регулярное выражение>,<кодировка>,<макс. кол-во строк>,<режим>,<вывод>,<максзадержка>] Zabbix агент фильтрует записи из файла журнала по регулярному выражению, если оно указано. Если требуется только количество совпадающих строк укажите: log.count[/путь/к/файлу/имя_файла,<регулярное выражение>,<кодировка>,<макс. кол-во строк>,<режим>,< максзадержка >] или logrt.count[/путь/к/файлу/регулярное_выражение_описывающее_шаблон_имени_файла,<регулярное выражение>,<кодировка>,<макс. кол-во строк>,<режим>,< максзадержка >]. Убедитесь, что у файла имеются права на чтение для пользователя 'zabbix', в противном случае состояние элемента данных будет 'unsupported'. Для получения более подробных сведений смотрите информацию о ключах log, log.count, logrt и logrt.count в разделе поддерживаемых ключей элементов данных Zabbix агентом. |
| Тип информации | Выберите здесь Журнал (лог) для элементов данных log и logrt или Числовой (целое положительное) для элементов данных log.count и logrt.count.Если используется опциональный параметр вывод, вы можете выбрать подходящий тип информации, отличный от "Журнал (лог)".Обратите внимание, что выбор не журнального типа информации приведет к потере локального штампа времени. |
| Интервал обновления (в сек) | Этот параметр задает как часто Zabbix агент будет проверять наличие любых изменений в файле журнала. Указав этот параметр равным 1 секунде, вы можете быть уверенными, что получите новые записи как можно скорее. |
| Формат времени журнала | В этом поле вы можете опционально задать шаблон для анализа штампа времени строки журнала. Если оставить пустым, штамп времени не будет анализироваться. Поддерживаемые значения: * y: Год (0001-9999) * M: Месяц (01-12) * d: День (01-31) * h: Час (00-23) * m: Минута (00-59) * s: Секунда (00-59) Например, рассмотрим следующую строку из файла журнала Zabbix агента: " 23480:20100328:154718.045 Zabbix agent started. Zabbix 1.8.2 (revision 11211)." Она начинается шестью символами обозначающими PID, далее следует дата, время, и остальная часть строки. Форматом времени журнала для этой строки является "pppppp:yyyyMMdd:hhmmss". Обратите внимание, что символы "p" и ":" являются лишь заменителями и могут быть чем угодно, за исключением "yMdhms". |
Важные замечания
- Сервер и агент следят за размером наблюдаемого журнала и временем
последней модификации (для logrt) двумя счетчиками. Дополнительно:
- Также агент использует номера inode (на UNIX/GNU/Linux), индексы файлов (на Microsoft Windows) и MD5 суммы первых 512 байт файла журнала для улучшения выбора в случае когда файлы журнала усекаются и ротируются.
- На системах UNIX/GNU/Linux предполагается, что файловые системы где хранятся файлы журналов, сообщают числа inode, которые могут быть использованы для слежения за состоянием файлов.
- На системах Microsoft Windows Zabbix агент определяет тип
файловой системе на которой находятся файлы журналов:
- На файловой системе NTFS 64-битные файловые индексы.
- На файловых системах ReFS (только Microsoft Windows Server 2012) 128-битные файловые ID.
- На файловых системах где файловые индексы меняются (т.е. FAT32, exFAT) используется запасной алгоритм для получения разумного подхода в неопределенных условиях, когда сжатие файла журнала приводит в результате к множеству файлов журналов с одинаковым временем изменения.
- Номера inode, индексы файлов и суммы MD5 собираются Zabbix агентом. Они не передаются Zabbix серверу и теряются в случае остановки Zabbix агента.
- Не меняйте время последней модификации файлов журналов, используя утилиту 'touch', не копируйте файл журнала с последующим восстановлением его имени (это изменит идентификатор иноды файла). В обоих случаях файл будет рассматриваться как другой и будет проанализирован с самого начала, что может привести к дубликатам оповещений.
- Если есть несколько совпадающих файлов журналов для элемента
данных
logrt[]и Zabbix агент следит за наиболее новым из них и этот более новый файл журнал удаляется, предупрежающиее сообщение будет записано"there are no files matching "<regexp mask>" in "<directory>". Zabbix агент игнорирует файлы журналы с временем изменения меньше чем последнее время модификации полученное агентом во время проверки элемента данныхlogrt[].
- Агент начинает читать файл журнала с той позиции, на которой он остановился последний раз.
- Количество байт уже проанализированное (счётчик размера) и время последней модификации (счетчик времени) хранятся в базе данных Zabbix и отправляются агенту, для уверенности, что агент начнет читать файл журнала с этой позиции в случаях, когда агент только что был запущен или агент получил элементы данных, которые были ранее деактивированы или не поддерживались. Однако, если агент получает ненулевой размер счётчика от сервера, но элементы данных logrt[] или logrt.count[] не найдены и не удается найти соответствующие файлы, счётчик размера сбрасывается в 0, чтобы начать анализ сначала, если файлы появятся позже.
- Всякий раз, когда файл журнала становится меньше, чем значение счетчика размера известное агенту, счетчик обнуляется и агент начинает читать файл журнала с самого начала, принимая во внимание счетчик времени.
- Eсли есть несколько файлов журналов, с одинаковым последним временем модификации файла в соответствующей папке, агент пытается корректно проанализировать все файлы журналы с одинаковым временем модификации и избежать пропущенных данных или проанализировать данные дважны, несмотря на это невозможно охватить все возможные ситуации. Агент не предполагает какую либо определенную схему ротации файлов журналов, либо определяет ее. Когда есть несколько фалов журналов с одинаковым последним временем изменения, агент будет обрабатывать их лексикографически в порядке убывания. Таким образом, для некоторых схем ротации файлы журналы будут проанализированы в их оригинальном порядке. Для других же схем ротации журналов первоначальный порядок файла журнала не будет соблюдаться, что может привести к получению найденных по шаблону строк файла журнала в измененном порядке (проблема не случится, если файлы журнала имеют разное время последнего изменения).
- Zabbix агент обрабатывает новые записи файла журнала один раз за Период обновления секунд.
- Zabbix агент отправляет не более чем макс. кол-во строк записей из файла журнала за секунду. Это ограничение предотвращает перегрузку сети и ресурсов процессора и переопределяет значение по умолчанию предусмотренное параметром MaxLinesPerSecond в файле конфигурации агента.
- Для поиска необходимой строки Zabbix обрабатывает в 10 раза больше
строк, чем указано в параметре MaxLinesPerSecond. Таким образом,
например, если элемент данных
log[]илиlogrt[]имеет Интервал обновления 1 секунда, по умолчанию агент будет анализировать не более чем 400 строк файла журнала и будет отправлять не более чем 200 совпавших записей Zabbix серверу за одну проверку. Увеличением параметра MaxLinesPerSecond в файле конфигурации агента или указанием параметра макс. кол-во строк в ключе элемента данных, лимит можно увеличить вплоть до 10000 проанализированных записей в журнале и 1000 совпадающих записей для отправки Zabbix серверу за одну проверку. Если Интервал обновления указан значением в 2 секунды, лимиты для одной проверки могут быть увеличены в два раза больше, чем для Интервала обновления в 1 секунду. - Кроме того, данные из файлов журналов всегда ограничены 50% размера буфера отправки у агента, даже если в буфере нет значений не связанных с данными из файлов журналов. Таким образом, значения макс. кол-во строк будут отправлены за одно соединение (а не в нескольких соединений), параметр BufferSize агента должен быть по крайней мере равен макс. кол-во строк x 2.
- При отсутствии данных для элементов данных журналов весь размер буфера используется для значений не связанных с данными из журналов. Когда появляются значения от файлов журналов они заменяют устаревшие данные не связанные с файлами журналов, если требуется, до максимального уровня 50%.
- Для записей в файле журнала длиннее 256КБ, только первые 256КБ сопоставляются с регулярным выражением, остальная часть игнорируется. Однако, если Zabbix агент был остановлен в процессе обработки длинной строчки, внутреннее состояние агента теряется и длинная строчка может быть проанализирована иначе после запуск агента.
- Специальное примечание для разделителей пути "\": если формат файла представлен как "file\.log", тогда там не должно быть папки "file", поскольку невозможно однозначно определить, экранируется ли это символ "." или это первый символ в имени файла.
- Регулярные выражения для logrt поддерживаются только в именах файлов, совпадение регулярного выражения с папкой не поддерживается.
- В UNIX элементы данных
logrt[]становится НЕПОДДЕРЖИВАЕМЫМ, в случае если папка не существует где файл журнала должен был бы находиться. - В Microsoft Windows, если папка не существует элемент данных не переводится в состояние НЕПОДДЕРЖИВАЕТСЯ (например, если в ключе элемента данных папка указана с ошибкой)
- Отсутствие файла журнала для элемента данных
logrt[]не переводит его в состояние НЕПОДДЕРЖИВАЕТСЯ. - Ошибки чтения файлов журналов для элемента данных
logrt[]записываются в журнал агента как предупреждения, но не переводят элемент данных в состояние НЕПОДДЕРЖИВАЕТСЯ. - Журнал Zabbix агента может быть очень полезен для поиска причин
почему элементы данных
log[]илиlogrt[]становятся НЕПОДДЕРЖИВАЕМЫМИ. Zabbix может мониторить свой файл журнала, за исключением случая когда он в режиме DebugLevel=4.
Извлечение совпадающей части регулярного выражения
Иногда мы можем захотеть извлечь только интересующие значения из требуемого файла вместо того, чтобы получать всю строку, в случае когда найдено совпадение с регулярным выражением.
Начиная с Zabbix 2.2.0, элементы данных файлов журналов расширены
возможностью получения извлечения требуемых значений из строк файла.
Добавился дополнительный параметр вывод у элементов данных log и
logrt.
Использование параметра 'вывод' позволяет обозначить подгруппу совпадения в которой мы можем быть заинтересованы.
И так, например
log[/path/to/the/file,"large result buffer allocation.*Entries: ([0-9]+)",,,,\1]должно позволить получить количество записей со следующего содержания:
Fr Feb 07 2014 11:07:36.6690 */ Thread Id 1400 (GLEWF) large result
buffer allocation - /Length: 437136/Entries: 5948/Client Ver: >=10/RPC
ID: 41726453/User: AUser/Form: CFG:ServiceLevelAgreementПричина, почему Zabbix вернет только одно число, потому что параметр 'вывод' здесь определен как \1 ссылка только на первую интересующую подгруппу: ([0-9]+)
Вместе с возможностью извлечения и получения числа, значение можно использовать в определениях триггеров.
Использование параметра максзадержка
Параметр 'максзадержка' в элементах данных журналов позволяет игнорировать более старые строки с целью получения наиболее новых строк проанализированных в течении “максзадержка” секунд.
Параметр 'maxdelay' > 0, может привести к игнорированию важных записей в файлах журналов и пропуску оповещений. Используйте этот параметр осторожно и на свой страх и риск, только в случае необходимости.
По умолчанию элементы данных мониторинга журналов забирают все новые
строки появляющиеся в файлах журналов. Однако, имеются приложения,
которые в некоторых ситуациях начинают записывать огромное количество
сообщений в свои файлы журналов. Например, если база данных или DNS
сервер недоступны, то такие приложения могут флудить файлы журналов
тысячами практически идентичных сообщений об ошибке до тех пор пока не
восстановится нормальный режим работы. По умолчанию, все эти сообщения
добросовестно анализируются и совпадающие строки оправляются на сервер,
как настроено в элементах данных log и logrt.
Встроенная защита от перегрузов состоит из настраиваемого параметра 'макс. кол-во строк' (защищающий сервер от слишком большого количества приходящих совпадающих строк в журнале) и ограничения в 4*'макс. кол-во строк' (защищает CPU и I/O хоста от перегрузки агентам одной проверкой). Тем не менее имеется 2 проблемы со встроенным механизмом защиты. Первая, на сервер будет отправлено большое количество потенциально не так информативных сообщений, которые займут место в базе данных. Вторая, по причине ограниченного количества строк анализируемых в секунду агент может отставать на часы от самых новых записей в журнале. Вполне вероятно, что вы захотите как можно быстрее быть информированным о текущей ситуации в файлах журналов вместо ковыряния часами старых записей.
Решение этих двух проблем является использование параметра 'максзадержка'. Если параметр 'maxdelay' > 0, во время каждой проверки измеряются количество обработанных байт, количество оставшихся байт и время обработки. Отталкиваясь от этих значений, агент вычисляет оценочную задержку - как много секунд может потребоваться, чтобы проанализировать все оставшиеся записи в файле журнала.
Если задержка не превышает 'максзадержка', тогда агент поступает с анализом файла журнала как обычно.
Если задержка больше чем 'максзадержка', тогда агент игнорирует часть файла журнала, "перепрыгивая" эту часть к новой оценочной позиции таким образом, чтобы оставшиеся строки можно было проанализировать за 'максзадержка' секунд.
Обратите внимание, что агент даже не читает проигнорированные строки в буфер, но вычисляет приблизительную позицию для прыжка в файле.
Сам факт пропуска строк в файле журнала записывается в файл журнала агента, примерно следующим образом:
14287:20160602:174344.206 item:"logrt["/home/zabbix32/test[0-9].log",ERROR,,1000,,,120.0]"
logfile:"/home/zabbix32/test1.log" skipping 679858 bytes
(from byte 75653115 to byte 76332973) to meet maxdelayКоличество "to byte" является оценочным, потому что после "прыжка" агент скорректирует позицию в файл к началу строки в журнале, которая может быть в файле чуть дальше или раньше.
В зависимости от того как скорость роста соотносится к скорости анализа файла журнала, вы можете не увидеть "прыжков", а можете увидеть редкие или частые "прыжки", большие или маленькие "прыжки", или даже маленькие "прыжки" каждую проверку. Колебания загрузки системы и сетевые задержки также влияют на вычисления задержки и, следовательно, "прыжки" вперед чтобы не отставать от параметра "максзадержка".
Не рекомендуется указывать 'максзадержка' < 'интервал обновления' (это может привести к частым маленьким "прыжкам").
Заметки по обработке ротации 'copytruncate' файлов журналов
logrt с опцией copytruncate подразумевает, что разные файлы журналов
имеют разные записи (по крайней мере штампы времени в них отличаются),
поэтому MD5 суммы начальных блоков (до первых 512 байт) будут
отличаться. Два файла с одинаковыми MD5 суммами начальных блоков
означают, что один из них оригинал, а второй - копия.
logrt с опцией copytruncate делает попытку правильной обработки
копий файлов журналов без дублирующих сообщений. Тем не менее, такие
варианты как создание нескольких копий файлов журналов с одинаковыми
штампами времени, ротация файлов журналов чаще чем интервал обновления
logrt[] элемента данных, частый перезапуск агента не рекомендуются.
Агент пытается справиться со всеми этими ситуациями, но хорошие
результаты не гарантируются при всех обстоятельствах.
Действия, если произошла ошибка связи между агентом и сервером
Каждая совпадающая строка с элементов данных log[] и logrt[] и
результат проверки каждого элемента данных log.count[] и
logrt.count[] требует свободный слот в выделенной 50% области буфера
отправки в агенте. Элементы буфера регулярно отправляются серверу (или
прокси) и слоты буфера становятся снова пустыми.
Пока имеются свободные слоты в выделенной области для журналов в буфере отправки в агенте и связь между агентом и сервером (или прокси) нарушена, результаты мониторинга журналов накапливаются в буфере отправки. Такое поведение позволяет смягчить кратковременные нарушения связи.
Во время длительных нарушений свящи все слоты журналов становятся занятыми и выполняются следующие действия:
- Проверки элементов данных
log[]иlogrt[]останавливаются. Когда связь восстановится и появятся свободные слоты, проверки вернутся к предыдущей позиции. Не совпадающие строки потеряются. Совпадающие строки не будут потеряны, они просто отправятся позже. - Проверки
log.count[]иlogrt.count[]останавливаются, еслиmaxdelay = 0(по умолчанию). Поведение похоже на элементы данныхlog[]иlogrt[], описанное выше. Обратите внимание, что потеря связи может повлиять на результатыlog.count[]иlogrt.count[]: например, одна проверка насчитает 100 совпадающих строк в файле журнала, но по причине отсутствия свободных слотом в буфере проверка будет остановлена. Когда связь восстановится агент насчитает те же 100 совпадающих строк, а также 70 новых совпадающих строк. После чего агент отправит количество = 170, так как они найдены за одну проверку. - Проверки
log.count[]иlogrt.count[]приmaxdelay > 0: если не было "прыжка" во время проверки, тогда поведение аналогично описанному выше. Если всё же был "прыжок" через строки файла журнала, тогда позиция после "прыжка" сохранится и подсчитанный результат будет отброшен. Таким образом, агент пытается не отставать от увеличивающегося файла журнала, даже в случае проблем со связью.
Purpose of persistent files
When Zabbix agent is started it receives a list of active checks from Zabbix server or proxy. For log*[] metrics it receives the processed log size and the modification time for finding where to start log file monitoring from. Depending on the actual log file size and modification time reported by file system the agent decides either to continue log file monitoring from the processed log size or re-analyze the log file from the beginning.
A running agent maintains a larger set of atributes for tracking all monitored log files between checks. This in-memory state is lost when the agent is stopped.
The new optional parameter persistent_dir specifies a directory for storing this state of log[], log.count[], logrt[] or logrt.count[] item in a file. The state of log item is restored from the persistent file after the Zabbix agent is restarted.
The primary use-case is monitoring of log file located on a mirrored file system. Until some moment in time the log file is written to both mirrors. Then mirrors are split. On the active copy the log file is still growing, getting new records. Zabbix agent analyzes it and sends processed logs size and modification time to server. On the passive copy the log file stays the same, well behind the active copy. Later the operating system and Zabbix agent are rebooted from the passive copy. The processed log size and modification time the Zabbix agent receives from server may not be valid for situation on the passive copy. To continue log file monitoring from the place the agent left off at the moment of file system mirror split the agent restores its state from the persistent file.
Agent operation with persistent file
On startup Zabbix agent knows nothing about persistent files. Only after receiving a list of active checks from Zabbix server (proxy) the agent sees that some log items should be backed by persistent files under specified directories.
During agent operation the persistent files are opened for writing (with fopen(filename, "w")) and overwritten with the latest data. The chance of losing persistent file data if the overwriting and file system mirror split happen at the same time is very small, no special handling for it. Writing into persistent file is NOT followed by enforced synchronization to storage media (fsync() is not called).
Overwriting with the latest data is done after successful reporting of matching log file record or metadata (processed log size and modification time) to Zabbix server. That may happen as often as every item check if log file keeps changing.
After receiving a list of active checks the agent scans persistent file directory and removes obsolete persistent files. Removing is done with delay 24 hours because log files in NOTSUPPORTED state are not included in the list of active checks but they may become SUPPORTED later and their persistent files will be useful. If agent is stopped and started again before 24 hours expire, then the obsolete files will not be deleted as Zabbix agent is not getting info about their location from Zabbix server anymore.
No special actions during agent shutdown.
After receiving a list of active checks the agent marks obsolete persistent files for removal. A persistent file becomes obsolete if: 1) the corresponding log item is no longer monitored, 2) a log item is reconfigured with a different persistent_dir location than before.
Removing is done with delay 24 hours because log files in NOTSUPPORTED state are not included in the list of active checks but they may become SUPPORTED later and their persistent files will be useful.
If the agent is stopped before 24 hours expire, then the obsolete files will not be deleted as Zabbix agent is not getting info about their location from Zabbix server anymore.
Reconfiguring a log item's persistent_dir back to the old persistent_dir location while the agent is stopped, without deleting the old persistent file by user - will cause restoring the agent state from the old persistent file resulting in missed messages or false alerts.
Naming and location of persistent files
Zabbix agent distinguishes active checks by their keys. For example, logrt[/home/zabbix/test.log] and logrt[/home/zabbix/test.log,] are different items. Modifying the item logrt[/home/zabbix/test.log,,,10] in frontend to logrt[/home/zabbix/test.log,,,20] will result in deleting the item logrt[/home/zabbix/test.log,,,10] from the agent's list of active checks and creating logrt[/home/zabbix/test.log,,,20] item (some attributes are carried across modification in frontend/server, not in agent).
The file name is composed of MD5 sum of item key with item key length appended to reduce possibility of collisions. For example, the state of logrt[/home/zabbix50/test.log,,,,,,,,/home/zabbix50/agent_private] item will be kept in persistent file c963ade4008054813bbc0a650bb8e09266.
Multiple log items can use the same value of persistent_dir.
persistent_dir is specified by taking into account specific file system layouts, mount points and mount options and storage mirroring configuration - the persistent file should be on the same mirrored filesystem as the monitored log file.
If persistent_dir directory cannot be created or does not exist, or access rights for Zabbix agent does not allow to create/write/read/delete files the log item becomes NOTSUPPORTED.
If access rights to persistent storage files are removed during agent operation or other errors occur (e.g. disk full) then errors are logged into the agent log file but the log item does not become NOTSUPPORTED.
Load on I/O
Item's persistent file is updated after successful sending of every batch of data (containing item's data) to server. For example, default 'BufferSize' is 100. If a log item has found 70 matching records then the first 50 records will be sent in one batch, persistent file will be updated, then remaining 20 records will be sent (maybe with some delay when more data is accumulated) in the 2nd batch, and the persistent file will be updated again.
Actions if communication fails between agent and server
Each matching line from log[] and logrt[] item and a result of each
log.count[] and logrt.count[] item check requires a free slot in the
designated 50% area in the agent send buffer. The buffer elements are
regularly sent to server (or proxy) and the buffer slots are free again.
While there are free slots in the designated log area in the agent send buffer and communication fails between agent and server (or proxy) the log monitoring results are accumulated in the send buffer. This helps to mitigate short communication failures.
During longer communication failures all log slots get occupied and the following actions are taken:
log[]andlogrt[]item checks are stopped. When communication is restored and free slots in the buffer are available the checks are resumed from the previous position. No matching lines are lost, they are just reported later.log.count[]andlogrt.count[]checks are stopped ifmaxdelay = 0(default). Behavior is similar tolog[]andlogrt[]items as described above. Note that this can affectlog.count[]andlogrt.count[]results: for example, one check counts 100 matching lines in a log file, but as there are no free slots in the buffer the check is stopped. When communication is restored the agent counts the same 100 matching lines and also 70 new matching lines. The agent now sends count = 170 as if they were found in one check.log.count[]andlogrt.count[]checks withmaxdelay > 0: if there was no "jump" during the check, then behavior is similar to described above. If a "jump" over log file lines took place then the position after "jump" is kept and the counted result is discarded. So, the agent tries to keep up with a growing log file even in case of communication failure.