
5 Escalades
Aperçu
Avec les escalades, vous pouvez créer des scénarios personnalisés pour envoyer des notifications ou exécuter des commandes à distance.
Concrètement cela signifie que :
- Les utilisateurs peuvent être informés immédiatement des nouveaux problèmes
- Les notifications peuvent être répétées jusqu'à ce que le problème soit résolu
- L'envoi d'une notification peut être retardé
- Les notifications peuvent être transmises à un autre groupe d'utilisateurs "supérieur"
- Les commandes à distance peuvent être exécutées immédiatement ou lorsqu'un problème n'est pas résolu pendant une longue période
Les actions sont escaladées en fonction de l'étape d'escalade. Chaque étape a une durée dans le temps.
Vous pouvez définir à la fois la durée par défaut et une durée personnalisée d'une étape individuelle. La durée minimale d'une étape d'escalade est de 60 secondes.
Vous pouvez démarrer des actions, telles que l'envoi de notifications ou l'exécution de commandes, à partir de n'importe quelle étape. La première étape concerne les actions immédiates. Si vous souhaitez retarder une action, vous pouvez l'affecter à une étape ultérieure. Pour chaque étape, plusieurs actions peuvent être définies.
Le nombre d'étapes d'escalade n'est pas limité.
Les escalades sont définies lors de la configuration d'une opération. Les escalades sont prises en charge uniquement pour les opérations problématiques, pas pour la récupération.
Aspects divers du comportement d'escalade
Considérons ce qui se passe dans différentes circonstances si une action contient plusieurs étapes d'escalade.
| Situation | Comportement |
|---|---|
| L'hôte en question passe en maintenance après l'envoi de la notification de problème initiale | Selon le paramètre Suspendre les opérations pour les problèmes supprimés dans la configuration de l'action, tout les étapes d'escalade restantes sont exécutées soit avec un retard causé par la période de maintenance, soit sans retard. Une période de maintenance n'annule pas les opérations. |
| La période de temps définie dans la condition d'action Période de temps se termine après l'envoi de la notification initiale | Toutes les étapes d'escalade restantes sont exécutées. La condition Période ne peut pas arrêter les opérations ; il a un effet sur le moment où les actions sont démarrées/non démarrées, pas sur les opérations. |
| Un problème commence pendant la maintenance et continue (n'est pas résolu) après la fin de la maintenance | Selon le paramètre Suspendre les opérations pour les problèmes supprimés dans la configuration de l'action, toutes les étapes d'escalade sont exécutées dès la fin de la maintenance ou immédiatement. |
| Un problème commence pendant une maintenance sans donnée et continue (n'est pas résolu) après la fin de la maintenance | Il doit attendre que le déclencheur se déclenche, avant que toutes les étapes d'escalade ne soient exécutées. |
| Différentes escalades se succèdent et se chevauchent | L'exécution de chaque nouvelle escalade remplace l'escalade précédente, mais pour au moins une étape d'escalade qui est toujours exécutée sur l'escalade précédente. Ce comportement est pertinent dans les actions sur les événements qui sont créés avec CHAQUE évaluation de problème du déclencheur. |
| Lors d'une escalade en cours (comme l'envoi d'un message), en fonction de tout type d'événement : - l'action est désactivée En fonction de l'événement déclencheur : - le déclencheur est désactivé - l'hôte ou l'élément est désactivé Selon un événement interne concernant les déclencheurs : - le déclencheur est désactivé Selon un événement interne concernant les éléments/règles de découverte de bas niveau : - l'élément est désactivé<br >- l'hébergeur est désactivé |
Le message en cours est envoyé puis un autre message sur l'escalade est envoyé. Le message de suivi contiendra le texte d'annulation au début du corps du message (NOTE: Escalation canceled) indiquant la raison (par exemple, *NOTE: Escalation canceled: action '<Action name>' disabled). De cette façon, le destinataire est informé que l'escalade est annulée et qu'aucune autre étape ne sera exécutée. Ce message est envoyé à tous ceux qui ont reçu les notifications auparavant. La raison de l'annulation est également consignée dans le fichier journal du serveur (à partir du Niveau de débogage 3=Avertissement). Notez que le message Escalation canceled est également envoyé si les opérations sont terminées, mais les opérations de récupération sont configurées et ne sont pas encore exécutées. |
| Lors d'une escalade en cours (comme l'envoi d'un message) l'action est supprimée | Plus aucun message n'est envoyé. Les informations sont consignées dans le fichier journal du serveur (à partir du Niveau de débogage 3=Avertissement), par exemple : escalation canceled: action id:334 deleted |
Exemples d'escalade
Exemple 1
Envoi d'une notification répétée une fois toutes les 30 minutes (5 fois au total) à un groupe 'MySQL Administrators'. Pour le configurer :
- Dans l'onglet Opérations, définissez la durée de l'étape d'opération par défaut à '30m' (30 minutes)
- Définissez les étapes d'escalade sur De '1' À '5'
- Sélectionnez le groupe 'MySQL Administrators' comme destinataires du message
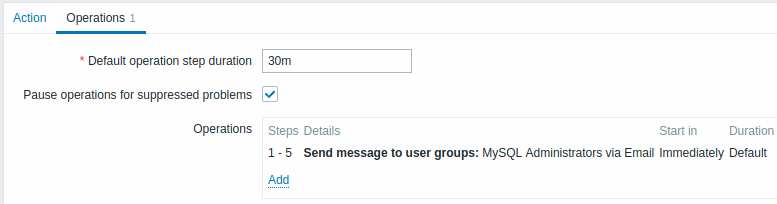
Les notifications seront envoyées 0:00, 0:30, 1:00, 1:30, 2:00 heures après le début du problème (à moins, bien sûr, que le problème ne soit résolu plus tôt).
Si le problème est résolu et qu'un message de récupération est configuré, il sera envoyé à ceux qui ont reçu au moins un message de problème dans ce scénario d'escalade.
Si le déclencheur qui a généré une escalade active est désactivé, Zabbix envoie un message informatif à ce sujet à tous ceux qui ont déjà reçu des notifications.
Exemple 2
Envoi d'une notification différée concernant un problème de longue date. Configurer :
- Dans l'onglet Opérations, définissez la durée de l'étape d'opération par défaut sur '10h' (10 heures)
- Définissez les étapes d'escalade sur De '2' À '2'
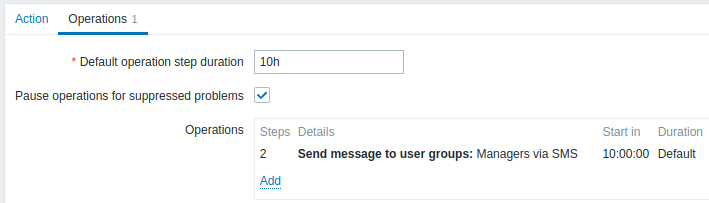
Une notification ne sera envoyée qu'à l'étape 2 du scénario d'escalade, ou 10 heures après le début du problème.
Vous pouvez personnaliser le texte du message avec quelque chose comme "Le problème date de plus de 10 heures".
Exemple 3
Faire remonter le problème au Boss.
Dans le premier exemple ci-dessus, nous avons configuré l'envoi périodique de messages aux administrateurs MySQL. Dans ce cas, les administrateurs recevront quatre messages avant que le problème ne soit transmis au gestionnaire de base de données. Notez que le responsable ne recevra un message que si le problème n'est pas encore acquitté, c'est-à-dire que personne n'y travaille.
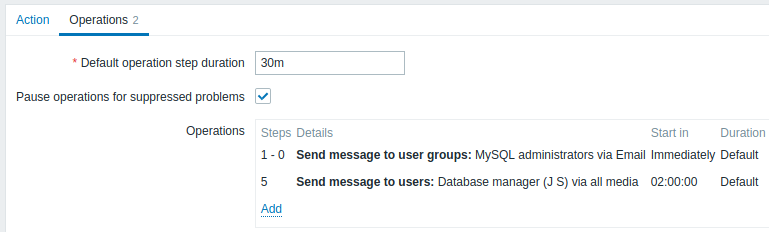
Détails de l'opération 2 :
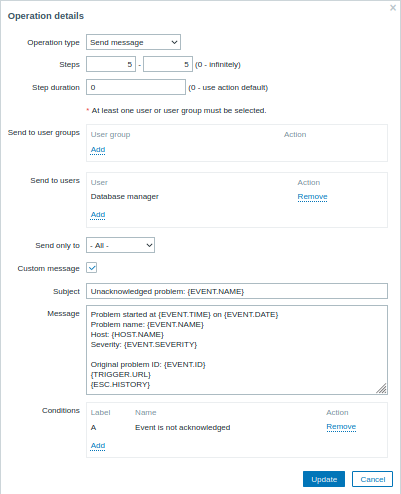
Notez l'utilisation de la macro {ESC.HISTORY} dans le message personnalisé. La macro contiendra des informations sur toutes les étapes précédemment exécutées sur cette escalade, telles que les notifications envoyées et les commandes exécutées.
Exemple 4
Un scénario plus complexe. Après plusieurs messages aux administrateurs MySQL et une escalade vers le responsable, Zabbix essaiera de redémarrer la base de données MySQL. Cela se produira si le problème existe depuis 2h30 et qu'il n'a pas été acquitté.
Si le problème persiste, après 30 minutes supplémentaires, Zabbix enverra un message à tous les utilisateurs invités.
Si cela ne résout pas le problème, après une heure supplémentaire, Zabbix redémarrera le serveur avec la base de données MySQL (deuxième commande à distance) à l'aide des commandes IPMI.
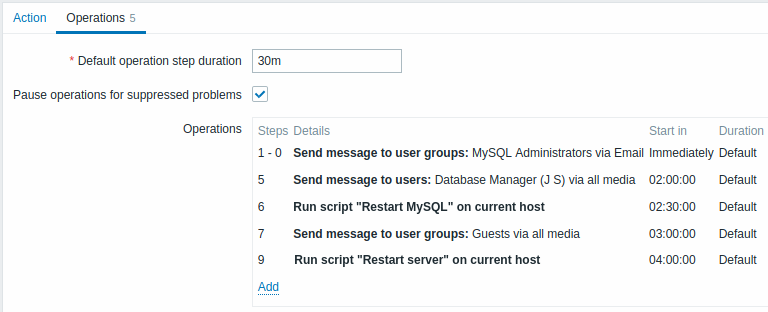
Exemple 5
Une escalade avec plusieurs opérations affectées à une étape et des intervalles personnalisés utilisés. La durée de l'étape de fonctionnement par défaut est de 30 minutes.
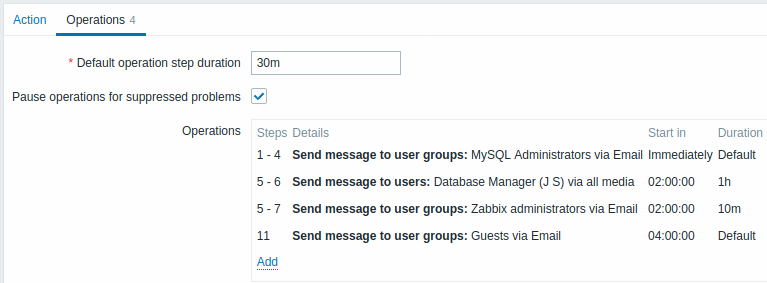
Les notifications seront envoyées comme suit :
- aux administrateurs MySQL 0:00, 0:30, 1:00, 1:30 après le début du problème
- au gestionnaire de base de données 2:00 et 2:10 après le début du problème (et non à 3:00 ; étant donné que les étapes 5 et 6 se chevauchent avec l'opération suivante, la durée d'étape personnalisée plus courte de 10 minutes dans l'opération suivante remplace la durée d'étape plus longue de 1 heure essayé de définir ici)
- aux administrateurs Zabbix 2:00, 2:10, 2:20 après le début du problème (la durée de l'étape personnalisée de 10 minutes de travail)
- aux utilisateurs invités 4:00 heures après le début du problème (la durée d'étape par défaut de 30 minutes revient entre les étapes 8 et 11)