
5 Escalações
Visão geral
Com os escalonamentos, você pode criar cenários personalizados para envio notificações ou execução de comandos remotos.
Em termos práticos significa que:
- Os usuários podem ser informados sobre novos problemas imediatamente
- As notificações podem ser repetidas até que o problema seja resolvido
- O envio de uma notificação pode ser atrasado
- As notificações podem ser escaladas para outro grupo de usuários "superior"
- Comandos remotos podem ser executados imediatamente ou quando um problema não é resolvido por um longo período
As ações são escalonadas com base na etapa de escalonamento. Cada passo tem um duração no tempo.
Você pode definir a duração padrão e uma duração personalizada de um passo individual. A duração mínima de uma etapa de escalonamento é de 60 segundos.
Você pode iniciar ações, como enviar notificações ou executar comandos, a partir de qualquer etapa. O primeiro passo é para ações imediatas. Se você quiser para atrasar uma ação, você pode atribuí-la a uma etapa posterior. Para cada passo, várias ações podem ser definidas.
O número de etapas de escalonamento não é limitado.
Os escalonamentos são definidos ao configurar um operação. As escalações são suportado apenas para operações problemáticas, não para recuperação.
Aspectos diversos do comportamento de escalação
Vamos considerar o que acontece em diferentes circunstâncias se uma ação contém várias etapas de escalonamento.
| Situação | Comportamento |
|---|---|
| O host em questão entra em manutenção após o envio da notificação inicial do problema | Dependendo da configuração Pausar operações para problemas suprimidos na ação configuração, todos as etapas de escalonamento restantes são executadas com um atraso causado pelo período de manutenção ou sem atraso. Um período de manutenção não cancela as operações. |
| O período de tempo definido na condição de ação Período de tempo termina após o envio da notificação inicial | Todas as etapas de escalonamento restantes são executadas. A condição Período de tempo não pode interromper as operações; tem efeito em relação a quando as ações são iniciadas/não iniciadas, não as operações. |
| Um problema começa durante a manutenção e continua (não é resolvido) após o término da manutenção | Dependendo da configuração Pausar operações para problemas suprimidos na ação configuração, todas as etapas de escalonamento são executadas a partir do momento em que a manutenção termina ou imediatamente. |
| Um problema começa durante uma manutenção sem dados e continua (não é resolvido) após o término da manutenção | Ele deve aguardar o disparo do gatilho, antes que todas as etapas de escalonamento sejam executadas. |
| Diferentes escalações seguem em sucessão e sobreposição | A execução de cada nova escalação substitui a escalação anterior, mas para pelo menos uma etapa de escalação que é sempre executada na escalação anterior. Esse comportamento é relevante em ações em eventos que são criados com TODA avaliação de problema do gatilho. |
| Durante um escalonamento em andamento (como uma mensagem sendo enviada), com base em qualquer tipo de evento: - a ação é desativada Com base no evento acionador: - o acionador é desabilitado - o host ou item está desabilitado Com base no evento interno sobre gatilhos: - o gatilho está desabilitado Com base no evento interno sobre itens/regras de descoberta de baixo nível: - o item está desabilitado >- o host está desabilitado |
A mensagem em andamento é enviada e mais uma mensagem no escalonamento é enviada. A mensagem de acompanhamento terá o texto de cancelamento no início do corpo da mensagem (NOTA: Escalação cancelada) nomeando o motivo (por exemplo, NOTA: Escalação cancelada: ação '<Nome da ação>' desabilitada). Desta forma o destinatário é informado que o escalonamento foi cancelado e não serão executadas mais etapas. Esta mensagem é enviada para todos que receberam as notificações anteriormente. O motivo do cancelamento também é registrado no arquivo de log do servidor (começando em Debug Level 3=Aviso). Observe que a mensagem Escalação cancelada também é enviado se as operações forem concluídas, mas as operações de recuperação estiverem configuradas e ainda não forem executadas. |
| Durante uma escalação em andamento (como uma mensagem sendo enviada), a ação é excluída | Não são enviadas mais mensagens. As informações são registradas no arquivo de log do servidor (começando em Debug Level 3=Aviso), por exemplo: escalação cancelada: ação id:334 excluído |
Exemplos de escalonamento
Exemplo 1
Enviando uma notificação repetida uma vez a cada 30 minutos (5 vezes no total) para um grupo de 'Administradores do MySQL'. Para configurar:
- na guia Operações, defina a Duração padrão da etapa de operação para '30m' (30 minutos)
- Defina as etapas de escalonamento como De '1' Para '5'
- Selecione o grupo 'MySQL Administrators' como destinatários da mensagem
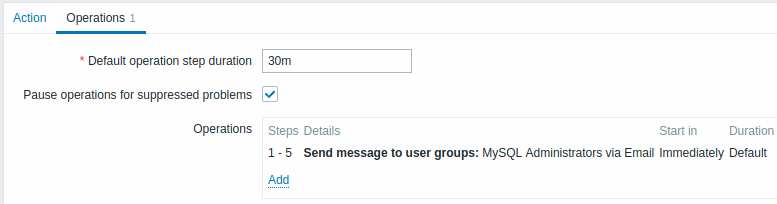
As notificações serão enviadas às 0:00, 0:30, 1:00, 1:30, 2:00 horas depois o problema começa (a menos, é claro, que o problema seja resolvido mais cedo).
Se o problema for resolvido e uma mensagem de recuperação for configurada, ela ser enviado para aqueles que receberam pelo menos uma mensagem de problema dentro deste cenário de escalada.
Se o gatilho que gerou uma escalação ativa for desabilitado, o Zabbix envia uma mensagem informativa sobre isso para todos aqueles que já receberam notificações.
Exemplo 2
Enviando uma notificação atrasada sobre um problema de longa data. Para configurar:
- Na guia Operações, defina a Duração da etapa de operação padrão para '10h' (10 horas)
- Defina as etapas de escalonamento como De '2' Para '2'
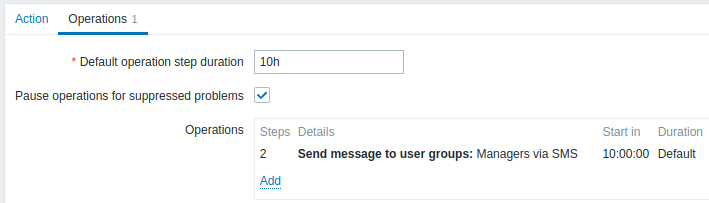
Uma notificação só será enviada na Etapa 2 do cenário de escalonamento, ou 10 horas após o início do problema.
Você pode personalizar o texto da mensagem para algo como 'O problema é mais de 10 horas'.
Exemplo 3
Escalando o problema para o chefe.
No primeiro exemplo acima configuramos o envio periódico de mensagens aos administradores do MySQL. Neste caso, os administradores receberão quatro mensagens antes que o problema seja escalado para o gerenciador de banco de dados. Observe que o gerente receberá uma mensagem apenas caso o problema não seja reconhecido ainda, supostamente ninguém está trabalhando nisso.
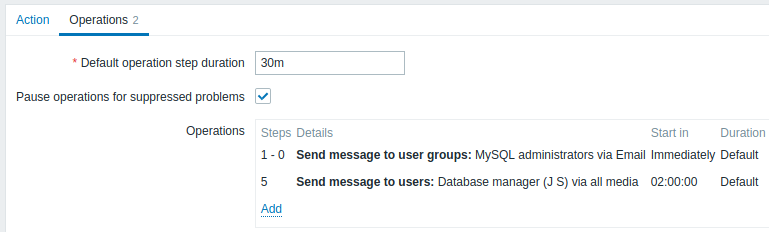
Detalhes da Operação 2:
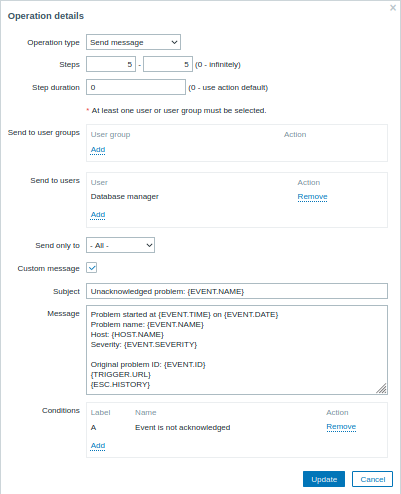
Observe o uso da macro {ESC.HISTORY} na mensagem personalizada. A macro conterá informações sobre todos os passos executados anteriormente neste escalação, como notificações enviadas e comandos executados.
Exemplo 4
Um cenário mais complexo. Após várias mensagens para administradores do MySQL e escalação para o gerente, o Zabbix tentará reiniciar o MySQL base de dados. Isso acontecerá se o problema persistir por 2:30 horas e não foi reconhecido.
Se o problema persistir, após mais 30 minutos o Zabbix enviará um mensagem para todos os usuários convidados.
Se isso não ajudar, depois de mais uma hora o Zabbix irá reiniciar o servidor com o banco de dados MySQL (segundo comando remoto) usando comandos IPMI.
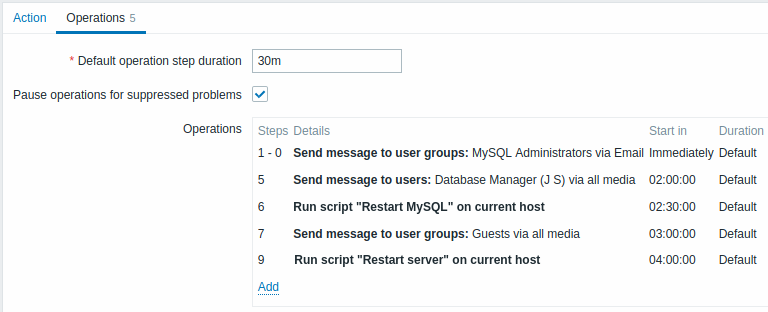
Exemplo 5
Um escalonamento com várias operações atribuídas a uma etapa e personalizado intervalos utilizados. A duração da etapa de operação padrão é de 30 minutos.
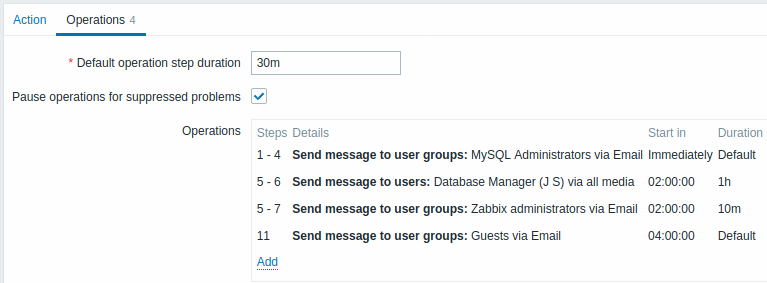
As notificações serão enviadas da seguinte forma:
- para administradores do MySQL às 0:00, 0:30, 1:00, 1:30 após o problema começa
- para o gerenciador de banco de dados às 2:00 e 2:10 (e não às 3:00; vendo que os passos 5 e 6 se sobrepõem com a próxima operação, o mais curto a duração da etapa de 10 minutos na próxima operação substitui a duração do passo mais longa de 1 hora tentou definir aqui)
- para administradores do Zabbix às 2:00, 2:10, 2:20 após o problema inicia (a duração da etapa personalizada de 10 minutos de trabalho)
- para usuários convidados às 4:00 horas após o início do problema (o padrão duração do passo de 30 minutos retornando entre os passos 8 e 11)