
5 Escalaties
Overzicht
Met escalaties kun je aangepaste scenario's maken voor het verzenden van meldingen of het uitvoeren van externe opdrachten.
In praktische termen betekent dit dat:
- Gebruikers direct op de hoogte kunnen worden gebracht van nieuwe problemen
- Meldingen kunnen worden herhaald totdat het probleem is opgelost
- Het verzenden van een melding kan worden vertraagd
- Meldingen kunnen worden geëscaleerd naar een andere "hogere" gebruikersgroep
- Externe opdrachten kunnen direct worden uitgevoerd of wanneer een probleem gedurende een langere periode niet is opgelost
Acties worden geëscaleerd op basis van de escalatiestap. Elke stap heeft een tijdsduur.
Je kunt zowel de standaardduur als een aangepaste duur van een individuele stap definiëren. De minimale duur van één escalatiestap is 60 seconden.
Je kunt acties starten, zoals het verzenden van meldingen of het uitvoeren van opdrachten, vanuit elke stap. Stap één is voor directe acties. Als je een actie wilt vertragen, kun je deze toewijzen aan een latere stap. Voor elke stap kunnen meerdere acties worden gedefinieerd.
Het aantal escalatiestappen is niet beperkt.
Escalaties worden gedefinieerd bij het configureren van een operatie. Escalaties worden alleen ondersteund voor probleemoperaties, niet voor hersteloperaties.
Diverse aspecten van het gedrag van escalatie
Laten we bekijken wat er gebeurt in verschillende omstandigheden als een actie meerdere escalatiestappen bevat.
| Situatie | Gedrag |
|---|---|
| Het betreffende host gaat in onderhoud nadat de eerste probleemmelding is verzonden | Afhankelijk van de instelling Operaties pauzeren voor onderdrukte problemen in de actie configuratie, worden alle resterende escalatiestappen uitgevoerd met vertraging als gevolg van de onderhoudsperiode of zonder vertraging. Een onderhoudsperiode annuleert geen operaties. |
| De in het actie ingestelde tijdperiode eindigt nadat de initiële melding is verzonden | Alle resterende escalatiestappen worden uitgevoerd. De Tijdperiode voorwaarde kan geen operaties stoppen; het heeft invloed op wanneer acties worden gestart/niet gestart, niet op operaties. |
| Een probleem begint tijdens onderhoud en gaat door (wordt niet opgelost) nadat het onderhoud is beëindigd | Afhankelijk van de instelling Operaties pauzeren voor onderdrukte problemen in de actie configuratie, worden alle escalatiestappen uitgevoerd vanaf het moment dat het onderhoud eindigt of onmiddellijk. |
| Een probleem begint tijdens een onderhoud zonder gegevens en gaat door (wordt niet opgelost) nadat het onderhoud is beëindigd | Het moet wachten tot de trigger wordt geactiveerd, voordat alle escalatiestappen worden uitgevoerd. |
| Verschillende escalaties volgen elkaar snel op en overlappen | De uitvoering van elke nieuwe escalatie vervangt de vorige escalatie, maar voor ten minste één escalatiestap die altijd wordt uitgevoerd op de vorige escalatie. Dit gedrag is relevant bij acties bij gebeurtenissen die zijn gemaakt met ELKE probleemevaluatie van de trigger. |
| Tijdens een lopende escalatie (zoals het verzenden van een bericht), gebaseerd op elk type gebeurtenis: - de actie is uitgeschakeld Gebaseerd op triggergebeurtenis: - de trigger is uitgeschakeld - de host of het item is uitgeschakeld Gebaseerd op interne gebeurtenis over triggers: - de trigger is uitgeschakeld Gebaseerd op interne gebeurtenis over items/ontdekkingsregels op laag niveau: - het item is uitgeschakeld - de host is uitgeschakeld |
Het bericht in uitvoering wordt verzonden en vervolgens wordt nog één bericht over de escalatie verzonden. Het vervolgbericht bevat de annuleringstekst aan het begin van het bericht (OPMERKING: Escalatie geannuleerd) met de reden (bijvoorbeeld OPMERKING: Escalatie geannuleerd: actie '<Actienaam>' uitgeschakeld). Op deze manier wordt de ontvanger geïnformeerd dat de escalatie is geannuleerd en dat er geen verdere stappen worden uitgevoerd. Dit bericht wordt verzonden naar iedereen die de meldingen eerder heeft ontvangen. De annuleringsreden wordt ook gelogd in het serverlogboekbestand (vanaf Debugniveau 3=Waarschuwing). Merk op dat het bericht Escalatie geannuleerd ook wordt verzonden als operaties zijn voltooid, maar hersteloperaties zijn geconfigureerd en nog niet zijn uitgevoerd. |
| Tijdens een lopende escalatie (zoals het verzenden van een bericht) wordt de actie verwijderd | Er worden geen verdere berichten verzonden. De informatie wordt gelogd in het serverlogboek (vanaf Debugniveau 3=Waarschuwing), bijvoorbeeld: escalatie geannuleerd: actie-id:334 verwijderd |
Escalatievoorbeelden
Voorbeeld 1
Het herhaaldelijk verzenden van een melding om de 30 minuten (in totaal 5 keer) naar de groep 'MySQL-beheerders'. Om te configureren:
- In het tabblad Operaties, stel de Standaard duur van de operatiestap in op '30m' (30 minuten)
- Stel de escalatiestappen in van Van '1' Tot '5'
- Selecteer de groep 'MySQL-beheerders' als ontvangers van het bericht
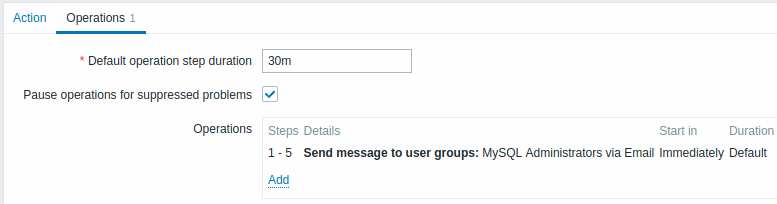
Meldingen worden verzonden om 0:00, 0:30, 1:00, 1:30, 2:00 uur nadat het probleem is gestart (tenzij het probleem natuurlijk eerder wordt opgelost).
Als het probleem wordt opgelost en er een herstelmelding is geconfigureerd, wordt deze verzonden naar degenen die minstens één probleemmelding hebben ontvangen binnen dit escalatiescenario.
Als de trigger die een actieve escalatie heeft gegenereerd, wordt uitgeschakeld, stuurt Zabbix een informatief bericht hierover naar iedereen die al meldingen heeft ontvangen.
Voorbeeld 2
Het verzenden van een vertraagde melding over een langdurig probleem. Om te configureren:
- In het tabblad Operaties, stel de Standaard duur van de operatiestap in op '10h' (10 uur)
- Stel de escalatiestappen in van Van '2' Tot '2'
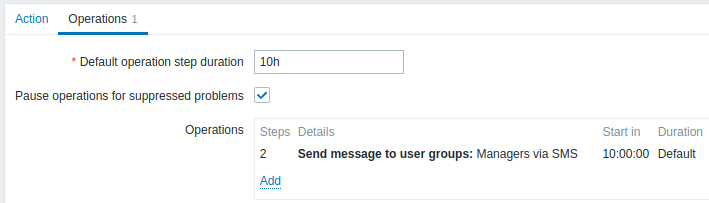
Een melding wordt alleen verzonden in Stap 2 van het escalatiescenario, of 10 uur nadat het probleem is gestart.
U kunt de tekst van het bericht aanpassen naar iets als 'Het probleem bestaat al meer dan 10 uur'.
Voorbeeld 3
Het escaleren van het probleem naar de baas.
In het eerste voorbeeld hierboven hebben we periodieke verzending van berichten naar MySQL-beheerders geconfigureerd. In dit geval zullen de beheerders vier berichten ontvangen voordat het probleem wordt geëscaleerd naar de databasebeheerder. Merk op dat de beheerder alleen een bericht zal ontvangen als het probleem nog niet is bevestigd, vermoedelijk werkt niemand er nog aan.
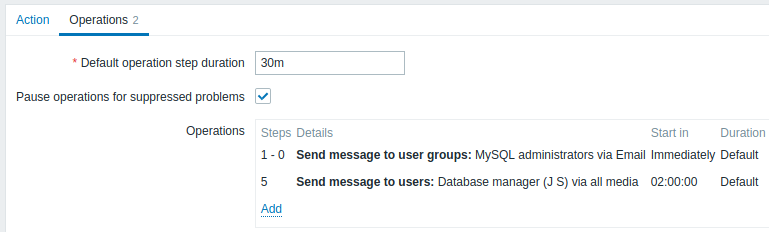
Details van Operatie 2:
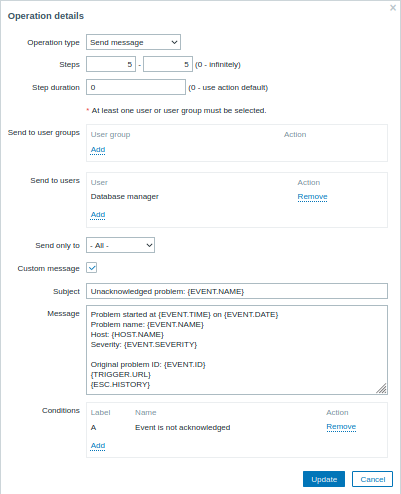
Merk het gebruik van de {ESC.HISTORY}-macro op in het aangepaste bericht. De macro bevat informatie over alle eerder uitgevoerde stappen in deze escalatie, zoals verzonden meldingen en uitgevoerde opdrachten.
Voorbeeld 4
Een complexer scenario. Na meerdere berichten naar MySQL-beheerders en escalatie naar de manager zal Zabbix proberen de MySQL-database opnieuw op te starten. Dit gebeurt als het probleem gedurende 2 uur en 30 minuten bestaat en het niet is bevestigd.
Als het probleem nog steeds bestaat, zal Zabbix na nog eens 30 minuten een bericht sturen naar alle gastgebruikers.
Als dit niet helpt, zal Zabbix na nog een uur de server opnieuw opstarten met de MySQL-database (tweede externe opdracht) met behulp van IPMI-opdrachten.
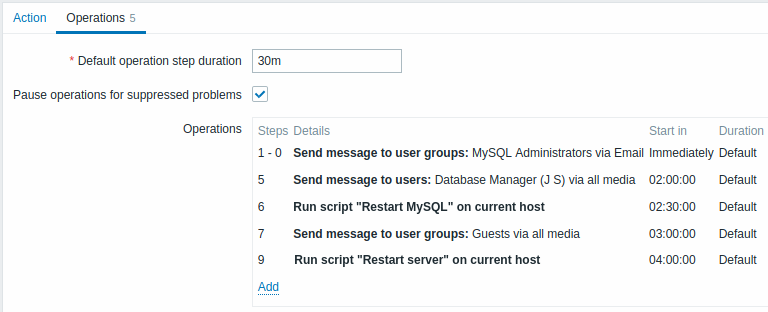
Voorbeeld 5
Een escalatie met meerdere operaties toegewezen aan één stap en aangepaste intervallen. De standaardduur van de operationele stap is 30 minuten.
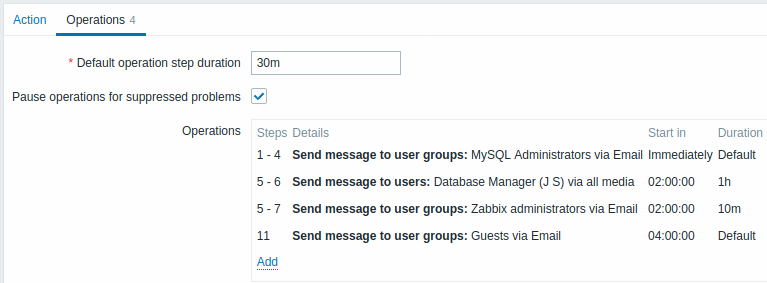
De meldingen worden als volgt verstuurd:
- naar MySQL-beheerders om 0:00, 0:30, 1:00, 1:30 nadat het probleem begint
- naar Databasebeheerder om 2:00 en 2:10 (en niet om 3:00 uur; omdat stappen 5 en 6 overlappen met de volgende operatie, overschrijft de kortere aangepaste stapduur van 10 minuten in de volgende operatie de langere stapduur van 1 uur die hier is geprobeerd in te stellen)
- naar Zabbix-beheerders om 2:00, 2:10, 2:20 nadat het probleem begint (de aangepaste stapduur van 10 minuten werkt)
- naar gastgebruikers om 4:00 uur na het begin van het probleem (de standaard stapduur van 30 minuten die terugkeert tussen stappen 8 en 11)