
5 エスカレーション
概要
エスカレーションを使用すると、通知を送信したり、リモート コマンドを実行したりするためのカスタム シナリオを作成できます。
具体的には、次のようなことです。
- ユーザーは新しい問題をすぐに通知できます
- 問題が解決するまで通知を繰り返すことができます
- 通知の送信を遅らせることができます
- 通知は、別の"より権限が上の"ユーザー グループにエスカレートできます
- リモートコマンドは、障害発生時すぐに、または障害が長期間解決されない場合に実行できます
アクションは、エスカレーション ステップに基づいてエスカレートされます。 各ステップには期間があります。
個々のステップのデフォルト期間とカスタム期間の両方を定義できます。 1 つのエスカレーション ステップの最小所要時間は 60 秒です。
通知の送信やコマンドの実行などのアクションは、どのステップからでも開始できます。 ステップ 1 は即時のアクションです。 アクションを遅らせたい場合は、後のステップに割り当てることができます。 ステップごとに、いくつかのアクションを定義できます。
エスカレーションのステップ数に制限はありません。
エスカレーションは、オペレーションの設定時に定義されます。 エスカレーションは障害のある操作に対してのみサポートされており、復旧はサポートされていません。
エスカレーション動作その他の例
アクションに複数のエスカレーション手順が含まれている場合、さまざまな状況で何が起こるかを考えてみましょう。
| 状況 | 動作 |
|---|---|
| 障害が発生したホストは、最初の障害通知が送信された後にメンテナンスに入る場合 | アクション設定 の メンテナンス中の場合に実行を保留 の設定に応じて、残りのエスカレーション手順はすべて、メンテナンス期間中遅延するか、遅延なしで即時実行されます。 メンテナンス期間によって操作がキャンセルされることはありません。 |
| 期間アクション条件で定義された期間は、最初の通知が送信された後、即時終了する場合 | 残りのすべてのエスカレーション手順が実行されます。 期間条件では操作を停止できません。 操作ではなく、アクションが開始されるかされないかに関して効果があります。 |
| メンテナンス中に不具合が発生し、メンテナンス終了後も継続する(解消されない)場合 | アクション 設定 の メンテナンス中の場合に実行を保留 の設定に応じて、すべてのエスカレーション手順は、メンテナンスが終了した瞬間、または即時実行されます。 |
| データなしのメンテナンス中に障害が発生し、メンテナンス終了後も継続する (解決されない)場合 | すべてのエスカレーション手順が実行される前に、トリガーが起動するのを待つ必要があります。 |
| さまざまなエスカレーションが連続して続き、重なる場合 | 新しい各エスカレーションの実行は前のエスカレーションに取って代わりますが、前のエスカレーションで常に実行されるエスカレーション手順が少なくとも 1 つ必要です。 この動作は、トリガーのすべての障害評価で作成されたイベントに対するアクションに関連しています。 |
| 進行中のエスカレーション中 (メッセージの送信など)、あらゆるタイプのイベントに基づいて: - アクションは無効 トリガー イベントに基づいて: - トリガーは無効 - ホストまたはアイテムは無効 トリガーに関する内部イベントに基づいて: - トリガーは無効 アイテム/ローレベルディスカバリルールに関する内部イベントに基づいて: - アイテムは無効 - ホストは無効 |
進行中のメッセージが送信され、エスカレーションに関するメッセージがもう 1 つ送信されます。 フォローアップ メッセージには、メッセージ本文の先頭にキャンセル テキスト (注: エスカレーションがキャンセルされました) があり、理由が示されます (例: 注: エスカレーションがキャンセルされました: アクション '<アクション名>' が無効化されました)。 このように、エスカレーションがキャンセルされ、それ以上の手順が実行されないことが受信者に通知されます。 このメッセージは、以前に通知を受け取ったすべての人に送信されます。 キャンセルの理由は、サーバーのログ ファイルにも記録されます (デバッグ レベル 3=Warning以上)。 エスカレーションがキャンセルされました メッセージも オペレーションが終了したが、リカバリ オペレーションが設定されていて、まだ実行されていない場合に送信されます。 |
| エスカレーションの進行中 (メッセージの送信など) にアクションが削除される | これ以上メッセージは送信されません。 情報はサーバー ログ ファイルに記録されます (デバッグ レベル 3=警告 以上) |
エスカレーション例
例 1
"MySQL 管理者"グループへ30 分ごとに 1 回 (合計 5 回) 繰り返し通知を送信します。 設定するには:
- [実行内容]タブで、デフォルトのアクション実行ステップの間隔 を '30m' (30 分) に設定します。
- エスカレーション ステップを From '1' To '5' に設定します。
- メッセージ受信者として"MySQL 管理者"グループを選択します。
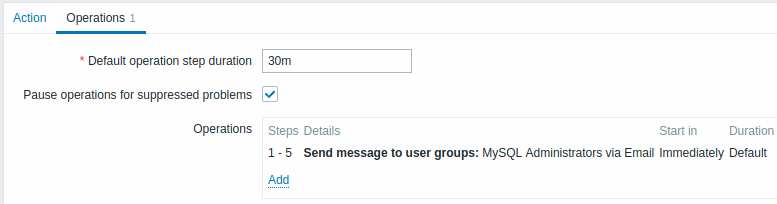
通知は、障害が発生してから 0:00,0:30,1:00,1:30,2:00 時に送信されます (もちろん問題がより早く解決されない限り)。
障害が解決され、回復メッセージが設定されている場合、このエスカレーション シナリオ内で少なくとも 1 つの障害メッセージを受信したユーザーに送信されます。
アクティブなエスカレーションを生成したトリガーが無効になっている場合、Zabbix はそれに関するメッセージを、既に通知を受け取っているすべての人に送信します。
例 2
長期障害について遅延通知を送信する。 設定するには:
- [実行内容] タブで、デフォルトのアクション実行ステップの間隔 を '10h' (10 時間) に設定します。
- エスカレーション手順を From '2' To '2' に設定します
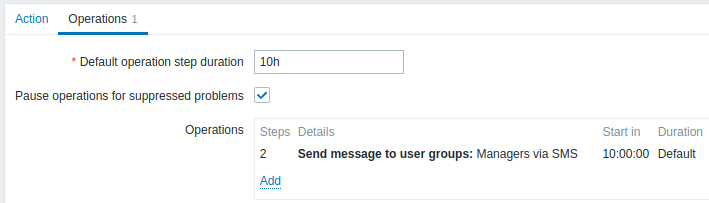
通知は、エスカレーション シナリオのステップ 2、または障害が発生してから 10 時間後にのみ送信されます。
メッセージ テキストは'障害が 発生して10 時間以上経過しています'などにカスタマイズできます。
例 3
上司に障害をエスカレーションします。
上記の最初の例では、MySQL 管理者に定期的にメッセージを送信するように設定しました。上記設定では管理者は障害がデータベース マネージャーにエスカレーションされる前に 4 回メッセージを受け取ります。マネージャーは障害が管理者に確認されていない場合にのみメッセージを受け取ることに注意してください。この時点ではおそらく誰も障害に対応していません。
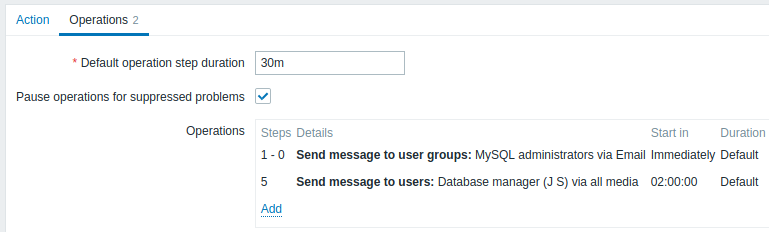
操作の詳細2:
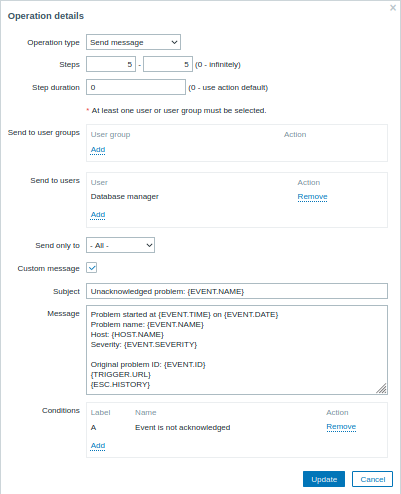
カスタマイズされたメッセージで {ESC.HISTORY} マクロが使用されていることに注意してください。 マクロには、送信された通知や実行されたコマンドなど、このエスカレーションで以前に実行されたすべてのステップに関する情報が含まれます。
例 4
より複雑なシナリオ。 MySQL 管理者への複数のメッセージとマネージャーへのエスカレーションの後、Zabbix は MySQL データベースの再起動を試みます。 障害が 2:30 時間存在し、確認されていない場合に発生します。
それでも障害が解決しない場合は、さらに 30 分後に Zabbix がすべてのゲスト ユーザーにメッセージを送信します。
これで障害が解決しない場合は、さらに 1 時間後に、Zabbix は IPMI コマンドを使用して MySQL データベース (2 番目のリモート コマンド) でサーバーを再起動します。
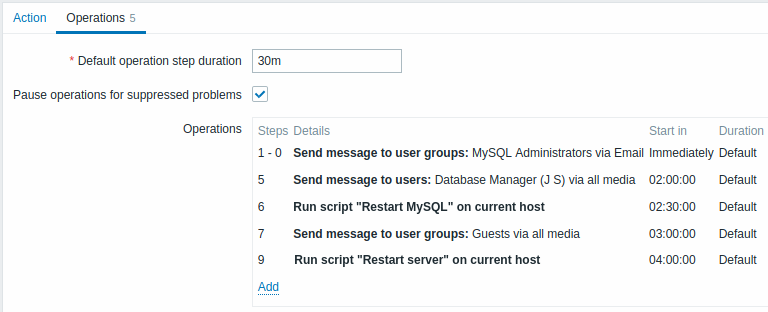
例 5
複数の操作が 1 つのステップに割り当てられ、カスタム間隔が使用されるエスカレーション。 デフォルトの操作ステップの所要時間は 30 分です。
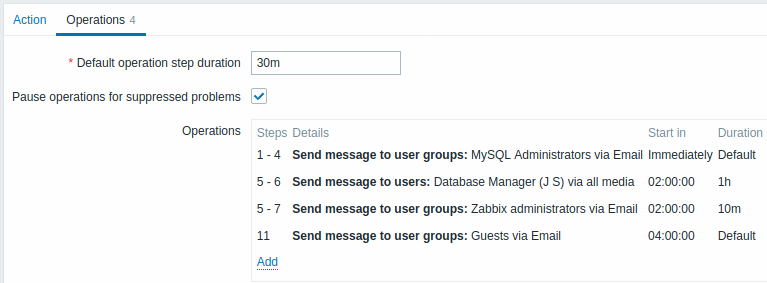
通知は次のように送信されます:
- 問題が発生してから 0:00、0:30、1:00、1:30 に MySQL 管理者に
- 2:00 と 2:10 にデータベース マネージャーに (3:00 ではありません。ステップ 5 と 6 が次の操作と重複しているため、次の操作の 10 分の短いカスタム ステップ期間は、ここで設定しようとした 1 時間の長いステップ期間をオーバーライドします)
- 問題が発生した後の 2:00、2:10、2:20 に Zabbix 管理者に (10 分間のカスタム ステップ継続時間)
- 問題が発生してから 4:00 時間後にゲスト ユーザーに (ステップ 8 と 11 の間に戻る 30 分のデフォルトのステップ継続時間)