
2 Детаљи претходне обраде
Преглед
Овај одељак пружа детаље о вредности предобраде корака ставке. Предобрада вредности ставке омогућава да се дефинишу и изврше правила трансформације за примљене вредности ставкe.
Предобрада управља процес менаџера за претходну обраду заједно са радницима за предобрадy који обављају кораке претходне обраде. Све вредности (са или без претходне обраде) од различитих сакупљача података пролазе кроз менаџер за предобраду пре него што се додају у кеш историје. IPC комуникација заснована на сокету се користи између сакупљача података (полери, трапери, итд.) и процеса предобраде. Или Zabbix сервер или Zabbix прокси (за ставке које надгледа проки) обављају кораке предобраде.
Обрада вредности ставке
Да бисмо визуализовали ток података од извора података до Zabbix базе података, можемо користити следећи поједностављени дијаграм:
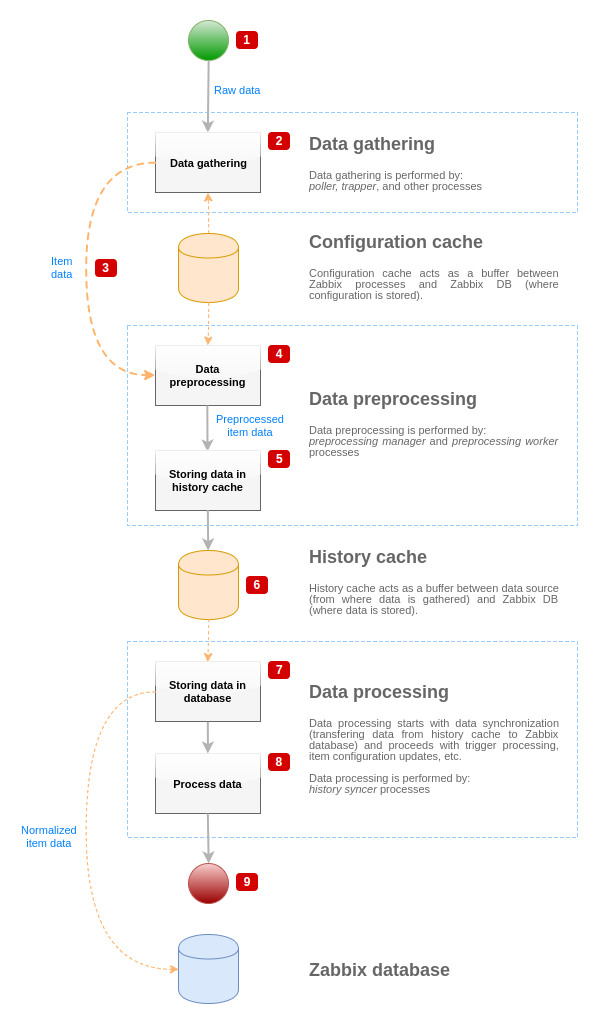
Горњи дијаграм приказује само процесе, објекте и радње везане за обраду вредности ставке у поједностављеном облику. Дијаграм не приказује условне промене смера, руковање грешкама или петље. Локални кеш података менаџера претходне обраде такође није приказан јер не утиче директно на ток података. Циљ овог дијаграма је да прикаже процесе укључене у обраду вредности ставке и начин на који они међусобно делују.
-
Прикупљање података почиње са сировим подацима из извора података. У овом тренутку, подаци садрже само ИД, временску ознаку и вредност (могу бити и вишеструке вредности).
-
Без обзира на то која врста сакупљача података се користи, идеја је иста за активне или пасивне провере, за ставке трапера итд., јер само мења формат података и покретач комуникације (или сакупљач података чека везу и податке, или сакупљач података покреће комуникацију и захтева податке). Сирови подаци се валидирају, конфигурација ставке се преузима из кеша конфигурације (подаци се обогаћују подацима конфигурације).
-
Механизам IPC заснован на сокету се користи за пренос података од сакупљача података до менаџера претходне обраде. У овом тренутку, сакупљач података наставља да прикупља податке без чекања одговора од менаџера претходне обраде.
-
Извршава се претходна обрада података. Ово укључује извршавање корака претходне обраде и зависне обраде ставке.
Ставка може променити своје стање у НИЈЕ ПОДРЖАНО док се извршава претходна обрада ако било који од корака претходне обраде не успе.
- Подаци историје из локалног кеша података менаџера претходне обраде се бришу у кеш историје.
- У овом тренутку проток података се зауставља до следеће синхронизације кеша историје (када процес синхронизације историје изврши синхронизацију података података).
- Процес синхронизације почиње нормализацијом података пре чувања података у Zabbix бази података. Нормализација података врши конверзије у жељени тип ставке (тип дефинисан у конфигурацији ставке), укључујући скраћивање текстуалних података на основу унапред дефинисаних величина дозвољених за те типове (HISTORY_STR_VALUE_LEN за стринг, HISTORY_TEXT_VALUE_LEN за текст и HISTORY_LOG_VALUE_LEN за вредности лога). Подаци се шаљу у Zabbix базу података након што је нормализација завршена.
Ставка може променити своје стање у НЕПОДРЖАНО ако нормализација података не успе (на пример, када се текстуална вредност не може конвертовати у број).
- Прикупљени подаци се обрађују - проверавају се окидачи, конфигурација ставке се ажурира ако ставка постане НЕПОДРЖАНА, итд.
- Ово се сматра крајем протока података са становишта обраде вредности ставке.
Претходна обрада вредности ставке
Претходна обрада података се врши у следећим корацима:
- Вредност ставке се прослеђује менаџеру претходне обраде користећи UNIX IPC механизам заснован на сокету.
- Ако ставка нема ни претходну обраду ни зависне ставке, њена вредност се или додаје у кеш историје или шаље LLD менаџеру. У супротном:
- Креира се задатак претходне обраде и додаје се у ред, а радници претходне обраде се обавештавају о новом задатку.
- У овом тренутку проток података се зауставља док не постоји барем један незаузет (тј. који не извршава ниједан задатак) радник претходне обраде.
- Када је радник претходне обраде доступан, он преузима следећи задатак из реда.
- Након што је претходна обрада завршена (и неуспешно и успешно извршавање корака претходне обраде), претходна вредност се додаје у ред завршених задатака, а менаџер се обавештава о новом завршеном задатку.
- Менаџер претходне обраде конвертује резултат у жељени формат (дефинисан типом вредности ставке) и или га додаје у кеш историје или га шаље LLD менаџеру.
- Ако постоје зависне ставке за обрађену ставку, онда се зависне ставке додају у ред за претходну обраду са вредношћу главне ставке која је претходно обрађена. Зависне ставке се стављају у ред за претходну обраду заобилазећи захтеве за претходну обраду нормалне вредности, али само за главне ставке са подешеном вредношћу и које нису у стању НИЈЕ ПОДРЖАНО.

Имајте на уму да је на дијаграму претходна обрада главне ставке мало поједностављена прескакањем кеширања претходне обраде.
Ред за претходну обраду
Ред за претходну обраду је организован као:
-
листа задатака на чекању:
- задаци креирани директно из захтева за претходну обраду вредности по редоследу којим су примљени
-
листа непосредних задатака (обрађених пре задатака на чекању):
- задаци за тестирање (креирани као одговор на ставку /претходна обрада захтева за тестирање од стране корисничког интерфејса)
- задаци зависне ставке
- задаци низа (задаци који се морају извршити у строгом редослед):
- са корацима за претходну обраду користећи последњу вредност:
- промена
- пригушивање
- JavaScript (кеширање бајткода)
- кеширање зависне ставке за претходну обраду
- листа завршених задатака
Кеширање предпроцесирања
Кеширање предпроцесирања је уведено да би се побољшале перформансе препроцесирања за више зависних ставки које имају сличне кораке препроцесирања (што је уобичајен LLD исход).
Кеширање се врши претходном обрадом једне зависне ставке и поновним коришћењем неких интерних података за претпроцесирање за остале зависне ставке. Кеш за претходну обраду је подржан само за први корак претходне обраде следећих типова:
- Прометејев образац (индексира унос помоћу метрике)
- JSONPath (рашчлањава податке у стабло објеката и индексира први израз
[?(@.path == "value) ")])
Радници претходне обраде
Конфигурациони фајл Zabbix сервера омогућава корисницима да подесе број нити радника претходне обраде. Параметар конфигурације StartPreprocessors треба користити за подешавање броја претходно покренутих инстанци радника претходне обраде, који би требало да се подудара барем са бројем доступних језгара процесора.
Ако задаци претходне обраде нису ограничени на процесор и укључују честе мрежне захтеве, препоручује се конфигурисање додатних радника. Оптималан број радника претходне обраде може се одредити многим факторима, укључујући број "претходно обрадивих" ставки (ставки које захтевају извршавање било којих корака претходне обраде), број процеса прикупљања података, просечан број корака за претходну обраду ставки итд. Недовољан број радника може довести до велике употребе меморије. За решавање проблема прекомерне употребе меморије на вашој Zabbix инсталацији, погледајте Профилисање прекомерне употребе меморије помоћу tcmalloc.
Али под претпоставком да нема тешких операција претходне обраде попут парсирања великих XML/JSON делова, број радника претходне обраде може се подударати са укупним бројем сакупљача података. На овај начин, углавном ће (осим у случајевима када подаци из сакупљача долазе у великом броју) бити барем један незаузет радник претходне обраде за прикупљене податке.
Превише процеса прикупљања података (анкетирачи, недоступни анкери, ODBC анкери, HTTP анкери, Јава анкери, пингери, трапери, прокси анкери) заједно са IPMI менаџером, SNMP трапером и радницима претходне обраде могу исцрпети ограничење дескриптора датотеке по процесу за менаџер претходне обраде.
Исцрпљивање ограничења дескриптора датотеке по процесу ће довести до заустављања Zabbix сервера, обично убрзо након покретања, али понекад траје дуже. Да бисте избегли такве проблеме, прегледајте конфигурациону датотеку Zabbix сервера да бисте оптимизовали број истовремених провера и процеса.
Поред тога, ако је потребно, проверите и прилагодите системска ограничења да ли је ограничење дескриптора датотеке довољно високо.
Value processing pipeline
Обрада вредности ставке се извршава у више корака (или фаза) од стране више процеса. Ово може проузроковати:
- Зависна ставка може да прима вредности, док главна вредност не може. Ово се може постићи коришћењем следећег случаја употребе:
- Главна ставка има тип вредности
UINT(ставка за хватање се може користити), зависна ставка има тип вредностиTEXT. - Нису потребни кораци претходне обраде ни за главну ни за зависне ставке.
- Текстуална вредност (на пример, "abc") треба да се проследи главној ставци.
- Пошто нема корака претходне обраде за извршавање, менаџер претходне обраде проверава да ли је главна ставка у стању НЕ ПОДРЖАНА и ако је вредност подешена (оба су тачна) и ставља зависну ставку у ред са истом вредношћу као главна ставка (јер нема корака претходне обраде ).
- Када и главна и зависна ставка достигну фазу синхронизације историје, главна ставка постаје НЕ ПОДРЖАНА због грешке у конверзији вредности (текстуални подаци се не могу конвертовати у неозначени цео број).
Као резултат тога, зависна ставка добија вредност, док главна ставка мења своје стање у НИЈЕ ПОДРЖАНО.
- Зависна ставка добија вредност која није присутна у историји главне ставке.
Случај употребе је веома сличан претходном, осим
типа главне ставке. На пример, ако се тип
CHARкористи за главну ставку, онда ће вредност главне ставке бити скраћена у фази синхронизације историје, док ће зависне ставке добити своје вредности од почетне (не скраћене) вредности главне ставке.