
2 预处理详情
概述
本节提供监控项值预处理的详细信息。监控项值预处理允许为接收到的监控项值定义并执行转换规则。
预处理由预处理管理器进程以及执行预处理步骤的预处理 worker 共同管理。所有带有预处理的值(在 Zabbix 7.4.1 之前为所有值),从不同的数据采集器接收后,都会先经过预处理管理器,然后再添加到历史缓存中。数据采集器(poller、trapper 等)与预处理进程之间使用基于套接字的 IPC 通信。Zabbix 服务器或 Zabbix proxy(对于由 proxy 监控的监控项)会执行预处理步骤。
监控项值处理
为了直观展示从数据源到 Zabbix 数据库的数据流,我们可以使用下面这个简化图示:
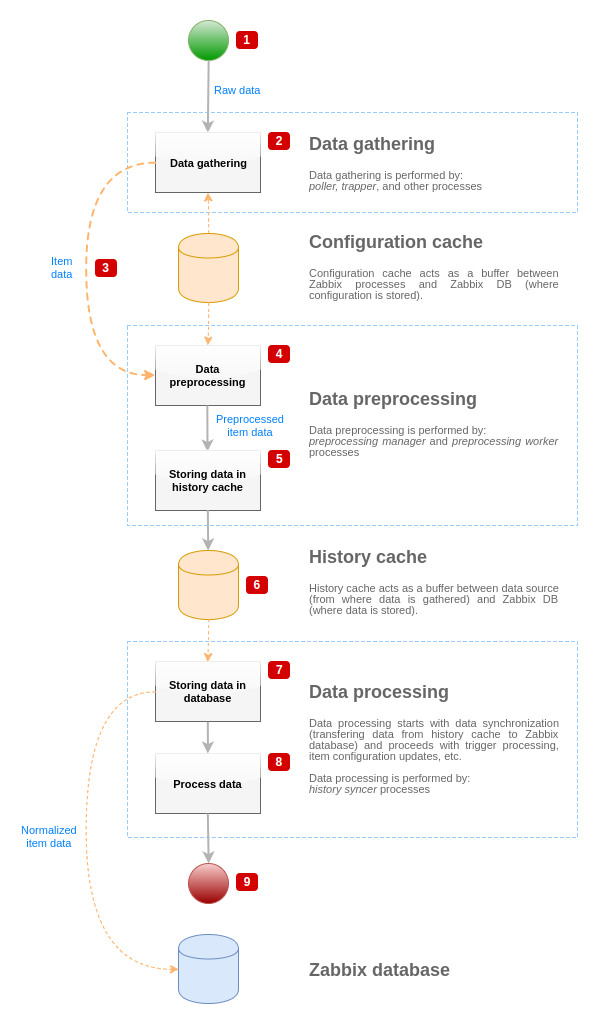
上图仅以简化形式展示了与监控项值处理相关的进程、对象和操作。图中未显示条件性方向变化、错误处理或循环。预处理 manager 的本地数据缓存也未显示,因为它不会直接影响数据流。该图的目的是展示参与监控项值处理的进程以及它们之间的交互方式。
- 数据采集从数据源中的原始数据开始。此时,数据只包含 ID、时间戳和值(也可能包含多个值)。
- 无论使用哪种类型的数据采集器,对于主动检查、被动检查、trapper 监控项等,原理都是相同的,因为它只会改变数据格式和通信发起方(要么数据采集器等待连接和数据,要么数据采集器发起通信并请求数据)。原始数据会被验证,监控项配置会从配置缓存中检索出来(数据会通过配置数据得到增强)。
- 使用基于 socket 的 IPC 机制将数据从数据采集器传递到预处理 manager。此时,数据采集器会继续采集数据,而不会等待预处理 manager 的响应。
- 执行数据预处理。这包括执行预处理步骤以及依赖监控项处理。
如果任何预处理步骤失败,监控项在预处理过程中可能会将其状态更改为 NOT SUPPORTED。
- 预处理 manager 本地数据缓存中的历史数据正在刷新到历史缓存中。
- 此时,数据流会停止,直到下一次历史缓存同步(即 history syncer 进程执行数据同步时)。
- 同步过程在将数据存储到 Zabbix 数据库之前,会先进行数据规范化。数据规范化会将数据转换为所需的监控项类型(由监控项配置中定义的类型决定),包括根据这些类型允许的预定义大小截断文本数据(string 使用 HISTORY_STR_VALUE_LEN,text 使用 HISTORY_TEXT_VALUE_LEN,log 值使用 HISTORY_LOG_VALUE_LEN)。规范化完成后,数据会被发送到 Zabbix 数据库。
如果数据规范化失败,监控项可能会将其状态更改为 NOT SUPPORTED(例如,文本值无法转换为数字时)。
- 已采集的数据正在被处理——会检查触发器,如果监控项变为 NOT SUPPORTED,则会更新监控项配置,等等。
- 从监控项值处理的角度来看,这被视为数据流的结束。
监控项值预处理
数据预处理按以下步骤执行:
- 如果监控项既没有预处理也没有依赖监控项,则其值要么添加到历史缓存,要么发送到 LLD 管理器。否则,监控项值会通过基于 UNIX socket 的 IPC 机制传递给预处理管理器(在 Zabbix 7.4.1 之前,所有值都会先经过预处理管理器,然后才会添加到历史缓存或发送到 LLD 管理器)。
- 会创建一个预处理任务,并将其加入队列,同时通知预处理 worker 有新任务。
- 此时,数据流会停止,直到至少有一个空闲的(即未执行任何任务的)预处理 worker 可用。
- 当有预处理 worker 可用时,它会从队列中取出下一个任务。
- 预处理完成后(无论预处理步骤执行成功还是失败),预处理后的值都会被添加到已完成任务队列,并通知管理器有新的已完成任务。
- 预处理管理器会将结果转换为所需格式(由监控项值类型定义),然后要么将其添加到历史缓存,要么发送给 LLD 管理器。
- 如果被处理的监控项存在依赖监控项,则会使用预处理后的主监控项值将依赖监控项加入预处理队列。依赖监控项的入队会绕过正常的值预处理请求,但仅适用于已设置值且不处于 NOT SUPPORTED 状态的主监控项。

请注意,在该图中,主监控项的预处理通过跳过预处理缓存而被略微简化了。
预处理队列
预处理队列组织如下:
-
待处理任务列表:
- 直接从值预处理请求中按接收顺序创建的任务
-
立即任务列表(在待处理任务之前处理):
- 测试任务(作为前端的监控项/预处理测试请求的响应而创建)
- 依赖监控项任务
- 顺序任务(必须按严格顺序执行的任务):
- 具有使用最后一个值的预处理步骤的任务:
- 更改
- 节流
- JavaScript(字节码缓存)
- 依赖监控项预处理缓存
- 具有使用最后一个值的预处理步骤的任务:
-
已完成任务列表
预处理缓存
预处理缓存被引入,以改善具有相似预处理步骤的多个依赖监控项(这是常见的LLD结果)的预处理性能。
通过对一个依赖监控项进行预处理,并重用一些内部预处理数据,来为其余的依赖监控项提供缓存。预处理缓存仅支持以下类型的第一个预处理步骤:
- Prometheus 模式(按度量衡输入的索引)
- JSONPath(将数据解析为对象树,并索引第一个表达式
[?(@.path == "value")])
预处理 worker
Zabbix 服务器配置文件允许用户设置预处理 worker 线程的数量。 应使用 StartPreprocessors 配置参数来设置预先启动的预处理 worker 实例数量,该数量至少应与可用的 CPU 核心数相匹配。
如果预处理任务不是 CPU 密集型的,并且涉及频繁的网络请求,建议配置更多的 worker。 预处理 worker 的最佳数量可由多种因素决定,包括“可预处理”监控项(即需要执行任意预处理步骤的监控项)的数量、数据采集进程的数量、监控项预处理的平均步骤数等。 worker 数量不足可能导致较高的内存使用量。有关排查 Zabbix 安装中过高内存使用量的方法,请参见 使用 tcmalloc 分析过高的内存使用量。
但是,假设不存在诸如解析大型 XML/JSON 数据块之类的高负载预处理操作,则预处理 worker 的数量可以与数据采集器的总数相匹配。这样一来,大多数情况下(数据由采集器批量送达的情况除外),对于已采集的数据,至少都会有一个空闲的预处理 worker 可用。
过多的数据采集进程(poller、unreachable poller、ODBC poller、HTTP poller、Java poller、pinger、trapper、proxypoller)以及 IPMI manager、SNMP trapper 和预处理 worker,可能会耗尽预处理 manager 的每进程文件描述符限制。
每进程文件描述符限制耗尽将导致 Zabbix 服务器停止运行,通常会在启动后不久发生,但有时也可能需要更长时间。
为避免此类问题,请检查 Zabbix 服务器配置文件,以优化并发检查数和进程数。
此外,如有必要,请通过检查并调整系统限制,确保文件描述符限制设置得足够高。
值处理管道
监控项值处理由多个进程分多个步骤(或阶段)执行。这可能导致:
- 依赖监控项可以接收到值,而主监控项却不能。
这可以通过以下用例实现:
- 主监控项的值类型为
UINT(可使用 trapper 监控项), 依赖监控项的值类型为TEXT。 - 主监控项和依赖监控项都不需要任何预处理步骤。
- 应将文本值(例如 "abc")传递给主监控项。
- 由于没有需要执行的预处理步骤,预处理管理器会检查主监控项是否不处于 NOT SUPPORTED 状态以及值是否已设置(两者都为真),然后将依赖监控项以与主监控项相同的值加入队列(因为没有预处理步骤)。
- 当主监控项和依赖监控项都进入历史同步阶段时,主监控项会因值转换错误而变为 NOT SUPPORTED 状态(文本数据无法转换为无符号整数)。
- 主监控项的值类型为
因此,依赖监控项会接收到一个值,而主监控项则会将其状态更改为 NOT SUPPORTED。
- 依赖监控项接收到的值在主监控项历史记录中不存在。该用例与前一个非常相似,区别仅在于主监控项类型。例如,如果主监控项使用
CHAR类型,那么主监控项的值会在历史同步阶段被截断,而依赖监控项将从主监控项的初始值(未截断的值)中接收其值。