
2 保存前処理の詳細
概要
このセクションでは、アイテム値の前処理の詳細について説明します。アイテム値の前処理では、受信したアイテム値に対して 変換ルール を定義し、実行できます。
前処理は、前処理マネージャープロセスと、前処理ステップを実行する前処理ワーカーによって管理されます。さまざまなデータ収集元から受信した前処理付きのすべての値(Zabbix 7.4.1 より前は、すべての値)は、history cache に追加される前に前処理マネージャーを通過します。データ収集元(ポーラー、トラッパーなど)と前処理プロセスの間では、ソケットベースの IPC 通信が使用されます。前処理ステップは、Zabbix サーバーまたは Zabbix プロキシ(プロキシで監視されるアイテムの場合)が実行します。
アイテム値の処理
データソースから Zabbix データベースまでのデータフローを可視化するために、次の簡略化した図を使用できます。
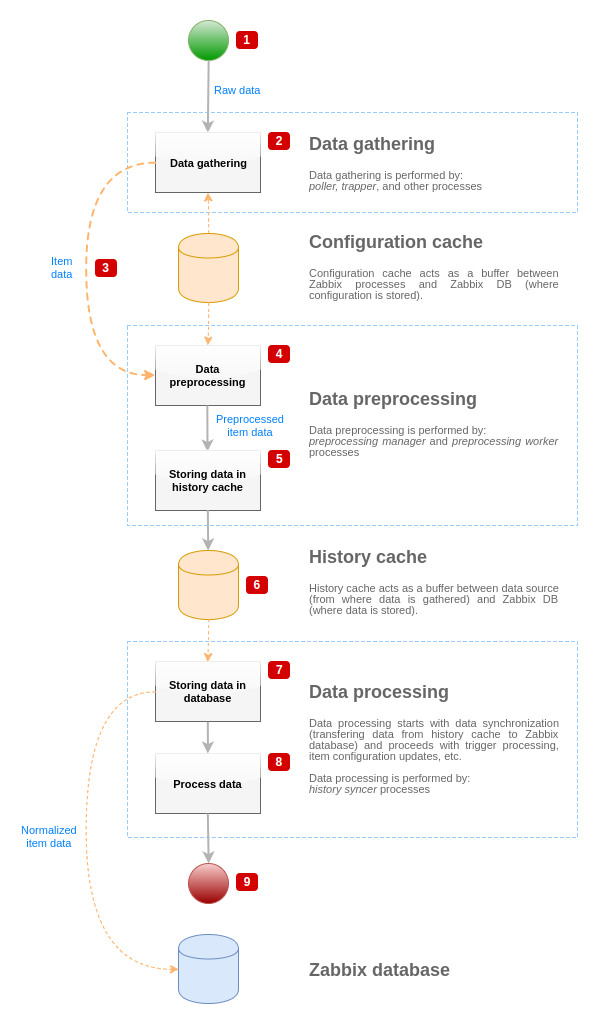
上の図は、アイテム値の処理に関連するプロセス、オブジェクト、およびアクションのみを 簡略化 した形で示しています。図には、条件による方向の変更、エラー処理、ループは含まれていません。また、前処理マネージャーのローカルデータキャッシュも、データフローに直接影響しないため表示していません。この図の目的は、アイテム値の処理に関与するプロセスと、それらがどのように相互作用するかを示すことです。
- データ収集は、データソースからの生データから始まります。この時点では、データには ID、タイムスタンプ、値のみが含まれます(複数の値を含む場合もあります)。
- 使用するデータ収集方式が何であっても、アクティブチェックでもパッシブチェックでも、トラッパーアイテムでも、考え方は同じです。違いはデータ形式と通信の開始側だけです(データ収集側が接続とデータを待機するか、データ収集側が通信を開始してデータを要求するか)。生データは検証され、アイテム設定は設定キャッシュから取得されます(データは設定データで拡張されます)。
- ソケットベースの IPC メカニズムを使用して、データ収集側から前処理マネージャーへデータを渡します。この時点で、データ収集側は前処理マネージャーからの応答を待たずに、データ収集を継続します。
- データの前処理が実行されます。これには、前処理ステップの実行と依存アイテムの処理が含まれます。
前処理の実行中に、いずれかの前処理ステップが失敗すると、アイテムの状態は NOT SUPPORTED に変わることがあります。
- 前処理マネージャーのローカルデータキャッシュにある履歴データが、history cache にフラッシュされます。
- この時点で、history cache の次回同期までデータフローは停止します(history syncer プロセスがデータ同期を実行する際)。
- 同期処理は、Zabbix データベースにデータを保存する前に、データの正規化から始まります。データの正規化では、アイテム設定で定義された目的のアイテムタイプへの変換が行われます。これには、各タイプで許可される 事前定義サイズ に基づくテキストデータの切り詰めも含まれます(string では HISTORY_STR_VALUE_LEN、text では HISTORY_TEXT_VALUE_LEN、log 値では HISTORY_LOG_VALUE_LEN)。正規化が完了すると、データは Zabbix データベースへ送信されます。
データの正規化に失敗すると、アイテムの状態は NOT SUPPORTED に変わることがあります (たとえば、テキスト値を数値に変換できない場合など)。
- 収集されたデータが処理されます。トリガーがチェックされ、アイテムが NOT SUPPORTED になった場合はアイテム設定が更新される、などが行われます。
- これは、アイテム値の処理という観点から見たデータフローの終点と見なされます。
アイテム値の前処理
データの前処理は、次の手順で実行されます。
- アイテムに前処理も依存アイテムもない場合、その値は history cache に追加されるか、LLD manager に送信されます。そうでない場合、アイテム値は UNIX ソケットベースの IPC メカニズムを使用して preprocessing manager に渡されます(Zabbix 7.4.1 より前では、すべての値は history cache に追加されるか LLD manager に送信される前に preprocessing manager を通過していました)。
- 前処理タスクが作成され、キューに追加され、preprocessing worker に新しいタスクが通知されます。
- この時点で、少なくとも 1 つの未使用の(つまり、いずれのタスクも実行していない)preprocessing worker が存在するまで、データフローは停止します。
- preprocessing worker が利用可能になると、キューから次のタスクを取得します。
- 前処理が完了すると(前処理ステップの実行が失敗した場合も成功した場合も含む)、前処理済みの値は完了済みタスクキューに追加され、manager に新しい完了済みタスクが通知されます。
- preprocessing manager は結果を目的の形式(アイテム値の型で定義)に変換し、history cache に追加するか、LLD manager に送信します。
- 処理対象のアイテムに依存アイテムがある場合、依存アイテムは前処理済みのマスターアイテム値とともに前処理キューに追加されます。依存アイテムは通常の値の前処理リクエストをバイパスしてキューに入れられますが、これは値が設定されており、かつ NOT SUPPORTED 状態ではないマスターアイテムに限られます。

図では、マスターアイテムの前処理は、前処理キャッシュ処理を省略しているため、やや簡略化されています。
前処理キュー
前処理キューは次のように構成されています:
-
保留中タスクのリスト:
- 受信順に値の前処理リクエストから直接作成されたタスク
-
即時タスクのリスト (保留中タスクより先に処理される):
- テストタスク (フロントエンドからのアイテム/前処理テストリクエストに応じて作成)
- 従属アイテムのタスク
- シーケンスタスク (厳密な順序で実行する必要があるタスク):
- 最終値を使用する前処理ステップを持つもの:
- 差分
- スロットリング
- JavaScript (バイトコードキャッシュ)
- 従属アイテムの前処理キャッシュ
- 最終値を使用する前処理ステップを持つもの:
-
完了したタスクのリスト
前処理キャッシュ
前処理キャッシュは、同様の前処理ステップを持つ複数の依存アイテム(これは一般的なLLDの結果です)の前処理パフォーマンスを向上させるために導入されました。
キャッシュは、1つの依存アイテムを前処理し、内部の前処理データの一部を残りの依存アイテムで再利用することで行われます。前処理キャッシュは、以下のタイプの最初の前処理ステップのみサポートされています:
- Prometheusパターン(メトリクスで入力をインデックス化)
- JSONPath(データをオブジェクトツリーに解析し、最初の式
[?(@.path == "value")]をインデックス化)
前処理ワーカー
Zabbixサーバーの設定ファイルでは、前処理ワーカースレッドの数を設定できます。 StartPreprocessors 設定パラメータを使用して、前処理ワーカーの事前起動インスタンス数を設定します。この数は、少なくとも利用可能なCPUコア数と同じである必要があります。
前処理タスクがCPUに依存せず、頻繁にネットワークリクエストを伴う場合は、追加のワーカーを設定することを推奨します。 最適な前処理ワーカー数は、「前処理可能」なアイテム数(前処理ステップの実行が必要なアイテム)、データ収集プロセス数、アイテム前処理の平均ステップ数など、多くの要因によって決まります。 ワーカーが不足すると、メモリ使用量が高くなる可能性があります。Zabbixインストールでの過剰なメモリ使用量のトラブルシューティングについては、tcmallocによる過剰なメモリ使用量のプロファイリング を参照してください。
ただし、大きなXML/JSONチャンクの解析などの重い前処理操作がない場合、前処理ワーカーの数はデータ収集プロセスの合計数と一致させることができます。これにより、(データ収集プロセスからデータが一括で送信される場合を除き)収集されたデータに対して少なくとも1つの空いている前処理ワーカーが存在することになります。
データ収集プロセス(ポーラー、到達不能ポーラー、ODBCポーラー、HTTPポーラー、Javaポーラー、ピンガー、トラッパー、プロキシポーラー)とIPMIマネージャー、SNMPトラッパー、前処理ワーカーが多すぎると、前処理マネージャーのプロセスごとのファイルディスクリプタ制限を使い果たす可能性があります。
プロセスごとのファイルディスクリプタ制限を使い果たすと、Zabbixサーバーは停止します。通常は起動直後ですが、場合によってはそれよりも長くかかることもあります。
このような問題を回避するために、Zabbixサーバーの設定ファイル を見直し、同時チェック数やプロセス数を最適化してください。
さらに必要に応じて、システムの制限を確認・調整し、ファイルディスクリプタの制限が十分に高く設定されていることを確認してください。
値処理パイプライン
アイテムの値の処理は、複数のプロセスによって複数のステップ(またはフェーズ)で実行されます。これにより、以下のようなことが発生する可能性があります。
- 従属アイテムは値を受け取ることができますが、マスター値は受け取れません。
これは、次のユースケースを使用することで実現できます。
- マスターアイテムの値の型は
UINT(トラッパーアイテムを使用可能)、従属アイテムの値の型はTEXT。 - マスターアイテムと従属アイテムの両方に前処理ステップは不要です。
- テキスト値(例: "abc")をマスターアイテムに渡す必要があります。
- 実行する前処理ステップがないため、前処理マネージャはマスターアイテムが「サポートされていない」状態でないことと値が設定されていることを確認し(両方とも真)、従属アイテムをマスターアイテムと同じ値でキューに入れます(前処理ステップがないため)。
- マスターアイテムと従属アイテムの両方が履歴同期フェーズに到達すると、マスターアイテムは値変換エラー(テキストデータを符号なし整数に変換できないため)により「サポートされていない」状態になります。
- マスターアイテムの値の型は
その結果、従属アイテムは値を受け取りますが、マスターアイテムは「サポートされていない」状態に変わります。
- 従属アイテムが、マスターアイテムの履歴に存在しない値を受け取る場合があります。ユースケースは前述のものと非常に似ていますが、マスターアイテムの型が異なります。たとえば、マスターアイテムに
CHAR型を使用した場合、マスターアイテムの値は履歴同期フェーズで切り捨てられますが、従属アイテムはマスターアイテムの初期値(切り捨てられていない値)から値を受け取ります。