
12 项目值预处理细节
概述
项目值预处理允许 define ,并对接收的项值执行转换规则。
预处理由预处理管理器进程管理,该进程已在Zabbix 3.4中添加,以及执行预处理步骤的预处理工作程序。 在添加到历史缓存之前,来自不同数据收集器的所有值(有或没有预处理)都会通过预处理管理器。 基于套接字的IPC通信用于数据收集器(轮询器,捕获器等)和预处理过程之间。 只有Zabbix服务器正在执行预处理步骤。
项目值预处理
为了可视化从数据源到Zabbix数据库的数据流,我们可以使用以下简化图:
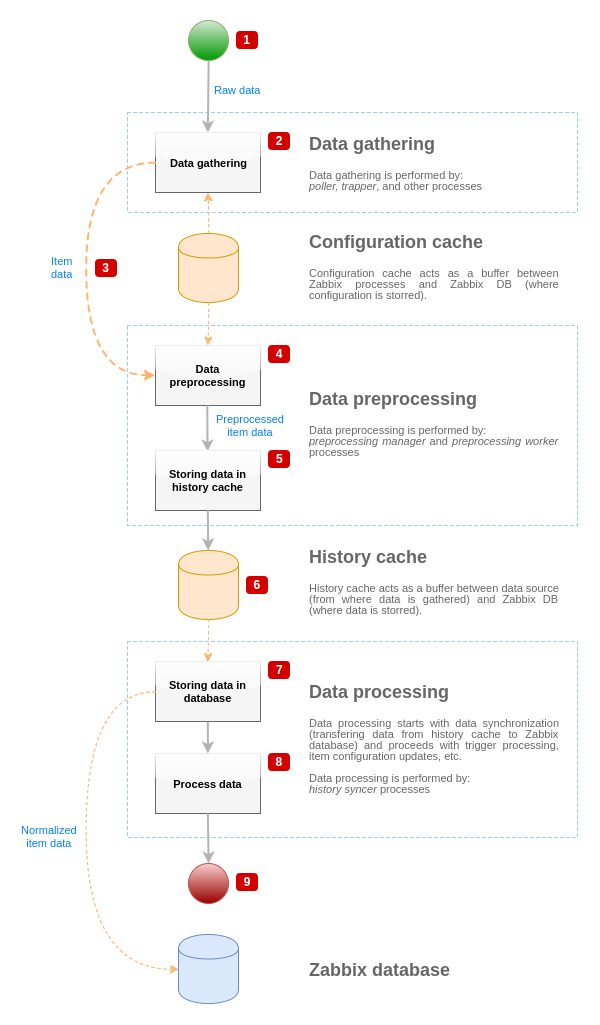
上图仅以简化形式显示与项目值处理相关的流程,对象和操作。 该图未显示条件方向更改,错误处理或循环。 未显示预处理管理器的本地数据高速缓存,因为它不会直接影响数据流。 此图的目的是显示项目值处理中涉及的过程及其交互方式。
- 数据收集从数据源的原始数据开始。 此时,数据仅包含ID,时间戳和值(也可以是多个值)
- 无论使用何种类型的数据收集器,对于主动或被动检查,捕获器项目等都是一样的,因为它只会改变数据格式和通信启动器(数据收集器正在等待连接和数据, 或数据收集器启动通信并请求数据)。 验证原始数据,从配置缓存中检索项目配置(数据通过配置数据进行丰富)。
- 基于套接字的IPC机制用于将数据从数据收集器传递到预处理管理器。 此时,数据收集器继续收集数据,而不等待预处理管理器的响应。
- 执行数据预处理。 这包括执行预处理步骤和依赖项处理。
如果任何预处理步骤失败,则在执行预处理时,项目可以将其状态更改为NOT SUPPORTED。
- 来自预处理管理器的本地数据高速缓存的历史数据正被刷新到历史高速缓存中。
- 此时,数据流将停止,直到下一次同步历史记录高速缓存(当历史同步器进程执行数据同步时)。
- 同步过程从数据规范化开始,在Zabbix数据库中存储数据。 数据规范化执行转换为所需项目类型(项目配置中定义的类型),包括基于这些类型允许的预定义大小截断文本数据(字符串为HISTORY_STR_VALUE_LEN,文本为HISTORY_TEXT_VALUE_LEN,日志值为HISTORY_LOG_VALUE_LEN)。 标准化完成后,数据将被发送到Zabbix数据库。
如果数据规范化失败(例如,当文本值无法转换为数字时),项可以将其状态更改为NOT SUPPORTED。
- 正在处理收集的数据 - 检查触发器,如果项目变得不受支持则更新项目配置等。
- 从项目值处理的角度来看,这被认为是数据流的结束。
项目值预处理
为了可视化数据预处理过程,我们可以使用以下简化图:
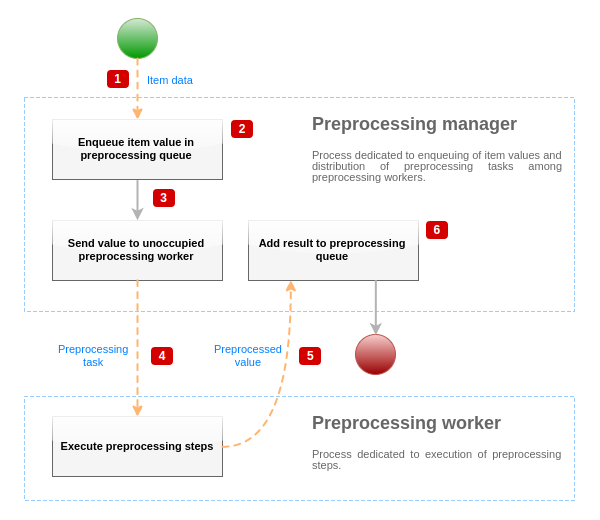
上图仅以简化形式显示了与项值预处理相关的流程,对象和主要操作。 该图未显示条件方向更改,错误处理或循环。 此图中只显示了一个预处理工作程序(多个预处理工作程序可以在实际场景中使用),只处理一个项目值,我们假设此项目需要执行至少一个预处理步骤。 该图的目的是展示项目值预处理管道背后的想法。
- 使用基于套接字的IPC机制将项数据和项值传递给预处理管理器。
- 项目放在预处理队列中。
项可以放在预处理队列的末尾或开头。 Zabbix内部项总是放在预处理队列的开头,而其他项类型最后排队。
- 此时,数据流停止,直到至少有一个未占用(即未执行任何任务)预处理工作程序。
- 当预处理工作器可用时,正在向其发送预处理任务。
- 在完成预处理(失败并成功执行预处理步骤)之后,预处理的值将被传递回预处理管理器。
- 预处理管理器将结果转换为所需格式(由项值类型定义),并将结果放入预处理队列。 如果当前项有依赖项,则依赖项也会添加到预处理队列中。 依赖项目在主项目之后的预处理队列中排队,但仅适用于具有值设置且未处于NOT SUPPORTED状态的主项目。
价值处理管道
通过多个处理以多个步骤(或阶段)执行项目值处理。 这可能导致:
- 从属项可以接收值,而主值不能。 这可以通过使用以下用例来实现:
<!-- --> * 主项具有值类型''UINT'',(可以使用捕获项),依赖项具有值类型''TEXT''。
* 主项和从属项都不需要预处理步骤。
* 应将文本值(例如“abc”)传递给主项目。
* 由于没有要执行的预处理步骤,预处理管理器检查主项目是否处于NOT SUPPORTED状态并且是否设置了值(两者都为真)并且将依赖项目排入与主项目具有相同值(因为没有预处理步骤)。
* 当主项和从属项都达到历史同步阶段时,由于值converSion错误(文本数据无法转换为无符号整数),主项变为NOT SUPPORTED。因此,依赖项接收值,而主项将其状态更改为NOT SUPPORTED。
- 从属项接收主项目历史记录中不存在的值。
除主项类型外,用例与前一个用例非常相似。
例如,如果
CHAR类型用于主项目,则主项目值将在历史同步阶段被截断,而依赖项目将从主项目的初始(未截断)值接收它们的值。
预处理队列
预处理队列是一种FIFO数据结构,它存储保留预处理管理器恢复值的顺序的值。 FIFO逻辑有多个例外:
- 内部项目在队列的开头排队
- 依赖项始终在主项后排队
为了可视化数据预处理过程,我们可以使用以下简化图:
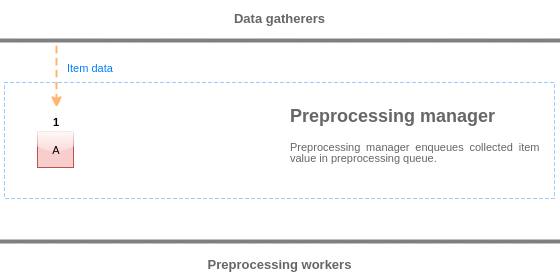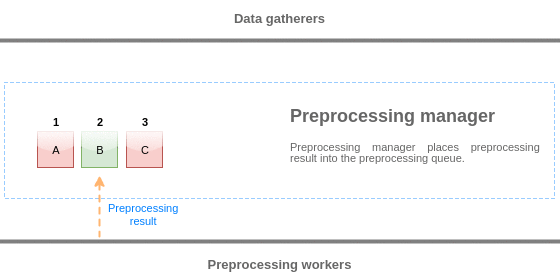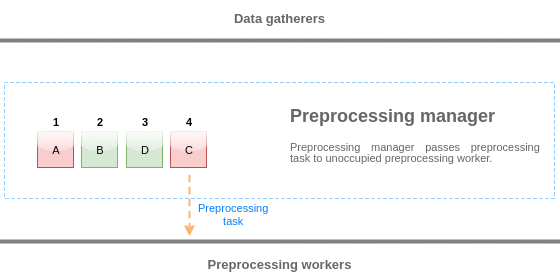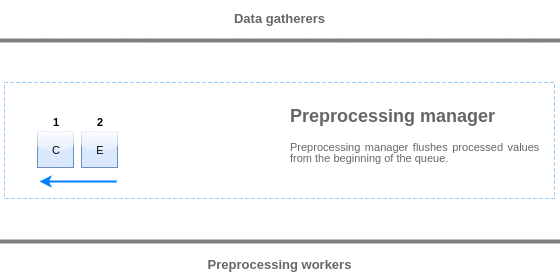
预处理队列中的值从队列的开头刷新到第一个未处理的值。 因此,例如,预处理管理器将刷新值1,2和3,但不会刷新值5,因为值4尚未处理:

刷新后,队列(4和5)中只剩下两个值,将值添加到预处理管理器的本地数据高速缓存中,然后将值从本地高速缓存传输到历史记录高速缓存中。 预处理管理器可以在单项模式或批量模式下从本地数据高速缓存刷新值(用于依赖项和批量接收的值)。
Preprocessing workers
Zabbix服务器配置文件允许用户设置预处理工作进程的计数。 应使用StartPreprocessors配置参数来设置预处理工作程序的预分叉实例数。 预处理工作者的最佳数量可以由许多因素决定,包括“可预处理”项目的计数(需要执行任何预处理步骤的项目),数据收集过程的计数,项目预处理的平均步数等。
但是假设没有像解析大型XML / JSON块那样繁重的预处理操作,预处理工作者的数量可以匹配数据收集器的总数。 这样,大多数(除了来自收集器的数据大量出现的情况除外)至少是一个未占用的预处理工作者用于收集数据。
<note warning>太多的数据收集进程(轮询器,无法访问的轮询器,HTTP轮询器,Java轮询器,pinper,捕获器,代理程序控制器)以及IPMI管理器,SNMP捕获器和预处理工作程序可能会耗尽预处理管理器的每进程文件描述符限制。 这将导致Zabbix服务器停止(通常在启动后不久,但有时可能需要更多时间)。 应修改配置文件或应提高限制以避免这种情况。 :::
12 Item value preprocessing details
Overview
Item value preprocessing allows to define and execute transformation rules for the received item values.
Preprocessing is managed by a preprocessing manager process, which has been added in Zabbix 3.4, along with preprocessing workers that perform the preprocessing steps. All values (with or without preprocessing) from different data gatherers pass through the preprocessing manager before being added to the history cache. Socket-based IPC communication is used between data gatherers (pollers, trappers, etc) and the preprocessing process. Only Zabbix server is performing preprocessing steps.
Item value processing
To visualize the data flow from data source to the Zabbix database, we can use the following simplified diagram:
The diagram above shows only processes, objects and actions related to item value processing in a simplified form. The diagram does not show conditional direction changes, error handling or loops. Local data cache of preprocessing manager is not shown either because it doesn't affect data flow directly. The aim of this diagram is to show processes involved in item value processing and the way they interact.
- Data gathering starts with raw data from a data source. At this point, data contains only ID, timestamp and value (can be multiple values as well)
- No matter what type of data gatherer is used, the idea is the same for active or passive checks, for trapper items and etc, as it only changes the data format and the communication starter (either data gatherer is waiting for a connection and data, or data gatherer initiates the communication and requests the data). Raw data is validated, item configuration is retrieved from configuration cache (data is enriched with the configuration data).
- Socket-based IPC mechanism is used to pass data from data gatherers to preprocessing manager. At this point data gatherer continue to gather data without waiting for the response from preprocessing manager.
- Data preprocessing is performed. This includes execution of preprocessing steps and dependent item processing.
Item can change its state to NOT SUPPORTED while preprocessing is performed if any of preprocessing steps fail.
- History data from local data cache of preprocessing manager is being flushed into history cache.
- At this point data flow stops until the next synchronization of history cache (when history syncer process performs data synchronization).
- Synchronization process starts with data normalization storing data in Zabbix database. Data normalization performs convertions to desired item type (type defined in item configuration), including truncation of textual data based on predefined sizes allowed for those types (HISTORY_STR_VALUE_LEN for string, HISTORY_TEXT_VALUE_LEN for text and HISTORY_LOG_VALUE_LEN for log values). Data is being sent to Zabbix database after normalization is done.
Item can change it's state to NOT SUPPORTED if data normalization fails (for example, when textual value cannot be converted to number).
- Gathered data is being processed - triggers are checked, item configuration is updated if item becomes NOT SUPPORTED, etc.
- This is considered the end of data flow from the point of view of item value processing.
Item value preprocessing
To visualize the data preprocessing process, we can use the following simplified diagram:
The diagram above shows only processes, objects and main actions related to item value preprocessing in a simplified form. The diagram does not show conditional direction changes, error handling or loops. Only one preprocessing worker is shown on this diagram (multiple preprocessing workers can be used in real-life scenarios), only one item value is being processed and we assume that this item requires to execute at least one preprocessing step. The aim of this diagram is to show the idea behind item value preprocessing pipeline.
- Item data and item value is passed to preprocessing manager using socket-based IPC mechanism.
- Item is placed in the preprocessing queue.
Item can be placed at the end or at the beginning of the preprocessing queue. Zabbix internal items are always placed at the beginning of preprocessing queue, while other item types are enqueued at the end.
- At this point data flow stops until there is at least one unoccupied (that is not executing any tasks) preprocessing worker.
- When preprocessing worker is available, preprocessing task is being sent to it.
- After preprocessing is done (both failed and successful execution of preprocessing steps), preprocessed value is being passed back to preprocessing manager.
- Preprocessing manager converts result to desired format (defined by item value type) and places result in preprocessing queue. If there are dependent items for current item, then dependent items are added to preprocessing queue as well. Dependent items are enqueued in preprocessing queue right after the master item, but only for master items with value set and not in NOT SUPPORTED state.
Value processing pipeline
Item value processing is executed in multiple steps (or phases) by multiple processes. This can cause:
- Dependent item can receive values, while THE master value cannot. This can be achieved by using the following use case:
<!-- --> * Master item has value type ''UINT'', (trapper item can be used), dependent item has value type ''TEXT''.
* No preprocessing steps are required for both master and dependent items.
* Textual value (like, "abc") should be passed to master item.
* As there are no preprocessing steps to execute, preprocessing manager checks if master item is not in NOT SUPPORTED state and if value is set (both are true) and enqueues dependent item with the same value as master item (as there are no preprocessing steps).
* When both master and dependent items reach history synchronization phase, master item becomes NOT SUPPORTED, because of the value converSion error (textual data cannot be converted to unsigned integer).As a result, dependent item receIves a value, while master item changes itS state to NOT SUPPORTED.
- Dependent item receives value that is not present in master item
history. The use case is very similar to the previous one, except
for the master item type. For example, if
CHARtype is used for master item, then master item value will be truncated at the history synchronization phase, while dependent items will receive their value from the initial (not truncated) value of master item.
Preprocessing queue
Preprocessing queue is a FIFO data structure that stores values preserving the order in which values are revieved by preprocessing manager. There are multiple exceptions to FIFO logic:
- Internal items are enqueued at the beginning of the queue
- Dependent items are always enqueued after the master item
To visualize the logic of preprocessing queue, we can use the following diagram:
Values from the preprocessing queue are flushed from the beginning of the queue to the first unprocessed value. So, for example, preprocessing manager will flush values 1, 2 and 3, but will not flush value 5 as value 4 is not processed yet:
Only two values will be left in queue (4 and 5) after flushing, values are added into local data cache of preprocessing manager and then values are transferred from local cache into history cache. Preprocessing manager can flush values from local data cache in single item mode or in bulk mode (used for dependent items and values received in bulk).
Preprocessing workers
Zabbix server configuration file allows users to set count of preprocessing worker processes. StartPreprocessors configuration parameter should be used to set number of pre-forked instances of preprocessing workers. Optimal number of preprocessing workers can be determined by many factors, including the count of "preprocessable" items (items that require to execute any preprocessing steps), count of data gathering processes, average step count for item preprocessing, etc.
But assuming that there is no heavy preprocessing operations like parsing of large XML / JSON chunks, number of preprocessing workers can match total number of data gatherers. This way, there will mostly (except for the cases when data from gatherer comes in bulk) be at least one unoccupied preprocessing worker for collected data.
Too many data gathering processes (pollers, unreachable pollers, HTTP pollers, Java pollers, pingers, trappers, proxypollers) together with IPMI manager, SNMP trapper and preprocessing workers can exhaust the per-process file descriptor limit for the preprocessing manager. This will cause Zabbix server to stop (usually shortly after the start, but sometimes it can take more time). The configuration file should be revised or the limit should be raised to avoid this situation.