
- 6 Supervision des fichiers journaux
6 Supervision des fichiers journaux
Aperçu
Zabbix peut être utilisé pour la surveillance centralisée et l'analyse des fichiers journaux avec/sans support de rotation des fichiers journaux.
Les notifications peuvent être utilisées pour avertir les utilisateurs lorsqu'un fichier journal contient certaines chaînes ou certains modèles de chaîne.
Pour superviser un fichier journal, vous devez avoir :
- Un agent Zabbix en cours d'exécution sur l'hôte
- Un paramètre de supervision de fichier journal mis en place
La taille limite d'un fichier de logs supervisé dépend du support des fichiers volumineux.
Configuration
Vérifier les paramètres de l'agent
Assurez-vous que dans le fichier de configuration de l'agent :
- Le paramètre 'Hostname' correspond au nom d'hôte dans l’interface Web
- Les serveurs dans le paramètre 'ServerActive' sont spécifiés pour le traitement des vérifications actives
Configuration d'un élément
Configurer un élément de supervision de fichier journal :
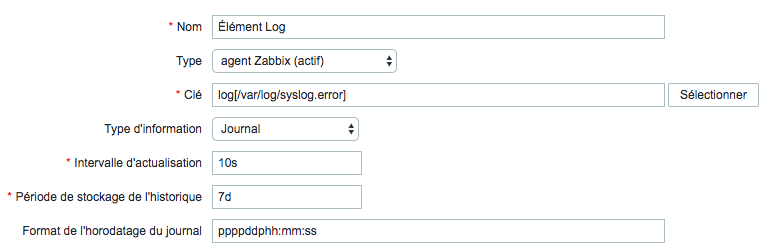
Tous les champs de saisie obligatoires sont marqués d'un astérisque rouge.
Spécifiquement pour les éléments de supervision de fichiers journaux vous devez entrer :
| Type | Sélectionnez agent Zabbix (actif) ici. |
| Clé | Utilise l'une des clés suivantes : log[] ou logrt[] : Ces deux clés d'élément permettent de surveiller les fichiers journaux et filtre le contenu des entrées des journaux via une expression régulière, si présente. Par exemple : log[/var/log/syslog,error]. Assurez-vous que le fichier dispose des autorisations de lecture pour l'utilisateur 'zabbix', sinon le statut de l'élément sera défini sur 'non supporté'.log.count[] ou logrt.count[] : Ces deux clés d'élément permettent de retourner uniquement un nombre de lignes qui correspondent. Voir la section concernant les clés d'éléments d'agent Zabbix supportées pour plus de détails sur l'utilisation des clés d'éléments et leurs paramètres. |
| Type d'information | Sélectionnez : Pour les éléments log[] ou logrt[] - Journal ; pour les éléments log.count[] ou logrt.count[] - Numérique (non signé).Si vous utilisez éventuellement le paramètre output, vous pouvez sélectionner le type d'information approprié autre que "Journal".Notez que le choix d'un type d'information autre que Journal entraînera la perte de l'horodatage local. |
| Intervalle d’actualisation | Le paramètre définit la fréquence (en seconde) à laquelle l'agent Zabbix vérifie les modifications dans le fichier journal. Le réglage à 1 seconde fera en sorte que vous obtiendrez de nouveaux enregistrements dès que possible. |
| Format de l'horodatage du journal | Dans ce champ, vous pouvez éventuellement spécifier le modèle pour l'analyse de l'horodatage de la ligne de journal. Si elle est vide, l'horodatage ne sera pas analysé. Espaces réservés pris en charge : * y: Année (0001-9999) * M: Mois (01-12) * d: Jour (01-31) * h: Heure (00-23) * m: Minute (00-59) * s: Seconde (00-59) Par exemple, considérez la ligne suivante du fichier journal de l'agent Zabbix : " 23480:20100328:154718.045 Zabbix agent started. Zabbix 1.8.2 (revision 11211)." Il commence par six positions de caractères pour le PID, suivies de la date, de l'heure et du reste de la ligne. Le format de l'heure du journal pour cette ligne serait “pppppp:yyyyMMdd:hhmmss”. Notez que les caractères "p" et ":" ne sont que des espaces réservés et peuvent être tout sauf "yMdhms". |
Notes importantes
- Le serveur et l'agent conservent la trace de la taille d'un journal surveillé et l'heure de la dernière modification (pour logrt) dans deux compteurs. Aditionellement :
<!-- --> * L'agent utilise également en interne des numéros d'inode (sous UNIX/GNU/Linux), des index de fichiers (sur Microsoft Windows) et des sommes MD5 des 512 premiers octets de fichier journal pour améliorer les décisions lorsque les fichiers de logs sont tronqués et pivotés.
* Sur les systèmes UNIX/GNU/Linux, il est supposé que les systèmes de fichiers où sont stockés les fichiers journaux renvoient des numéros d'inode, qui peuvent être utilisés pour suivre les fichiers.
* Sous Microsoft Windows, l'agent Zabbix détermine le type de système de fichiers sur lequel résident les fichiers journaux et utilise :
* Sur les systèmes de fichiers NTFS index de fichiers 64 bits.
* Sur les systèmes de fichiers ReFS (uniquement à partir de Microsft Windows Server 2012) ID de fichier 128 bits.
* Sur les systèmes de fichiers où les index de fichiers changent (par exemple FAT32, exFAT) un algorithme de repli est utilisé pour adopter une approche sensée dans des conditions incertaines lorsque la rotation du fichier journal entraîne plusieurs fichiers de logs avec la même heure de modification.
* Les numéros d'inode, les index de fichiers et les sommes MD5 sont collectés en interne par l'agent Zabbix. Ils ne sont pas transmis au serveur Zabbix et sont perdus lorsque l'agent Zabbix est arrêté.
* Ne modifiez pas l'heure de la dernière modification des fichiers de logs avec l'utilitaire 'touch', ne restaurez pas un fichier de logs en gardant son nom d'origine (cela changera le numéro d'inode du fichier). Dans les deux cas, le fichier sera considéré comme différent et sera analysé dès le début, ce qui peut entraîner des alertes en double.
* S'il y a plusieurs fichiers journaux correspondants pour l'élément ''logrt[]'' et que l'agent Zabbix suit le plus récent d'entre eux et que ce fichier journal le plus récent est supprimé, un message d'avertissement ''"there are no files matching ”<regexp mask>“ in ”<directory>"'' est enregistré. L'agent Zabbix ignore les fichiers de logs dont l'heure de modification est inférieure à l'heure de modification la plus récente vue par l'agent pour l’élément ''logrt[]'' en cours de vérification.
* L'agent commence à lire le fichier journal à partir du moment où il s'est arrêté la fois précédente.
* Le nombre d'octets déjà analysés (le compteur de taille) et l'heure de dernière modification (le compteur de temps) sont stockés dans la base de données Zabbix et envoyés à l'agent pour s'assurer que l'agent commence à lire le fichier journal depuis cet emplacement dans le cas où l’agent vienne juste de démarrer ou a reçu des éléments précédemment désactivés ou non supportés. Toutefois, si l'agent a reçu un compteur de taille différent de zéro du serveur, mais que l'élément logrt[] ou logrt.count[] n'a pas été trouvé et ne trouve pas de fichiers correspondants, le compteur de taille est réinitialisé à 0 si les fichiers apparaissent plus tard.
* Chaque fois que le fichier journal devient plus petit que le compteur de taille du fichier journal connu par l'agent, le compteur est remis à zéro et l'agent commence à lire le fichier journal depuis le début en tenant compte du compteur de temps.
* S'il y a plusieurs fichiers correspondants avec la même heure de modification dans le répertoire, l'agent analyse correctement tous les fichiers journaux avec la même heure de modification et évite de sauter les données ou d'analyser deux fois les mêmes données, même si cela ne peut pas être garanti. L'agent n'assume aucun schéma de rotation de fichier de logs particulier et n'en détermine aucun. Lorsque plusieurs fichiers de logs sont présentés avec la même heure de dernière modification, l'agent les traite dans un ordre décroissant lexicographique. Ainsi, pour certains schémas de rotation, les fichiers de logs seront analysés et rapportés dans leur ordre d'origine. Pour les autres schémas de rotation, l'ordre des fichiers de logs d'origine ne sera pas respecté, ce qui peut entraîner la génération de rapports dans les fichiers de logs correspondants (le problème ne se produit pas si les fichiers de logs ont des temps de modification différents).
* L'agent Zabbix traite les nouveaux enregistrements d'un fichier journal une fois par //intervalle d’actualisation// en secondes.
* L'agent Zabbix n'envoie pas plus le **maxlines** d'un fichier journal par seconde. La limite empêche la surcharge des ressources réseau et CPU et remplace la valeur par défaut fournie par le paramètre **MaxLinesPerSecond** dans le [[fr:manual:appendix:config:zabbix_agentd|fichier de configuration de l'agent]].
* Pour trouver la chaîne requise, Zabbix traitera 10 fois plus de nouvelles lignes que dans MaxLinesPerSecond. Par exemple, si un élément ''log[]'' ou ''logrt[]'' a un //intervalle d’actualisation// de 1 seconde, l'agent analysera par défaut pas plus de 200 enregistrements de fichiers de logs et n'enverra pas plus de 20 enregistrements correspondants au serveur Zabbix en une seule vérification. En augmentant **MaxLinesPerSecond** dans le fichier de configuration de l'agent ou en définissant le paramètre maxlines dans la clé de l'élément, la limite peut être augmentée jusqu'à 10000 enregistrements de fichiers de logs analysés et 1000 enregistrements correspondants envoyés au serveur Zabbix en une seule vérification. Si l'//intervalle d’actualisation// est défini sur 2 secondes, les limites pour une vérification seront définies 2 fois plus haut qu'avec l'//intervalle d’actualisation// de 1 seconde.
* De plus, les valeurs log et log.count sont toujours limitées à 50% de la taille du buffer d'envoi de l'agent, même s'il n'y a pas de valeurs non log. Ainsi, pour que les valeurs **maxlines** soient envoyées dans une connexion (et non dans plusieurs connexions), le paramètre [[fr:manual:appendix:config:zabbix_agentd|BufferSize]] de l'agent doit être au moins maxlines x 2
* En l'absence d'éléments journaux, toute la taille du buffer d'agent est utilisée pour les valeurs non log. Lorsque les valeurs des fichiers journaux arrivent, elles remplacent les anciennes valeurs non log, selon les besoins, jusqu'à 50%.
* Pour les enregistrements de fichiers journaux de plus de 256 Ko, seuls les 256 premiers Ko correspondent à l'expression régulière et le reste de l'enregistrement est ignoré. Cependant, si l'agent Zabbix est arrêté alors qu'il traite un enregistrement long, l'état interne de l'agent est perdu et l'enregistrement long peut être analysé de nouveau et différemment après le redémarrage de l'agent.
* Remarque spéciale pour les séparateurs de chemin "\" : si file_format est "fichier\.log", il ne doit pas y avoir de répertoire "fichier" car il est impossible de définir sans ambiguïté si "." est échappé ou est le premier symbole du nom du fichier.
* Les expressions régulières pour ''logrt'' sont prises en charge dans le nom de fichier uniquement, la correspondance d'expression régulière du répertoire n'est pas prise en charge.
* Sur les plates-formes UNIX, ''logrt[]'' devient NON SUPPORTÉ si un répertoire dans lequel les fichiers journaux doivent être trouvés n'existe pas.
* Sur Microsoft Windows, si un répertoire n'existe pas, l'élément ne deviendra pas NON SUPPORTÉ (par exemple, si le répertoire est mal orthographié dans la clé de l'élément).
* Une absence de fichiers journaux pour ''logrt[]'' ne le rend pas NON SUPPORTÉ. Les erreurs de lecture des fichiers journaux pour ''logrt[]'' sont consignées comme des avertissements dans le fichier journal de l'agent Zabbix mais ne font pas apparaître l'élément NON SUPPORTÉ.
* Le fichier journal de l'agent Zabbix peut être utile pour savoir pourquoi un élément ''log[]'' ou ''logrt[]'' est devenu NON SUPPORTÉ. Zabbix peut surveiller son fichier journal de l'agent sauf au niveau DebugLevel=4.Extraction de la partie correspondante de l'expression régulière
Nous pouvons parfois vouloir extraire uniquement la valeur intéressante d'un fichier cible au lieu de renvoyer la ligne entière lorsqu'une correspondance d'expression régulière est trouvée.
Depuis Zabbix 2.2.0, les éléments de fichiers journaux ont la
possibilité d'extraire les valeurs souhaitées des lignes
correspondantes. Ceci est accompli par le paramètre supplémentaire
output dans les éléments log et logrt.
L'utilisation du paramètre 'output' permet d'indiquer le sous-groupe correspondant qui pourrait nous intéresser.
Ainsi, par exemple :
log[/path/to/the/file,"large result buffer allocation.*Entries: ([0-9]+)",,,,\1]devrait permettre de renvoyer le nombre d'entrées tel que trouvé dans le contenu de :
Fr Feb 07 2014 11:07:36.6690 */ Thread Id 1400 (GLEWF) large result
buffer allocation - /Length: 437136/Entries: 5948/Client Ver: >=10/RPC
ID: 41726453/User: AUser/Form: CFG:ServiceLevelAgreementLa raison pour laquelle Zabbix renverra seulement le nombre est parce que 'output' ici est défini par \1 se référant au premier et seul sous-groupe d'intérêt : ([0-9]+)
Et, avec la possibilité d'extraire et de renvoyer un nombre, la valeur peut être utilisée pour définir des déclencheurs.
Utilisation du paramètre maxdelay
Le paramètre 'maxdelay' dans les éléments journaux permet d'ignorer certaines anciennes lignes des fichiers journaux afin d'obtenir les lignes les plus récentes analysées dans les secondes correspondant à 'maxdelay'.
La spécification de 'maxdelay' > 0 peut conduire à ignorer les enregistrements de fichiers journaux importants et manquer des alertes. Utilisez-le soigneusement à vos risques et périls seulement si nécessaire.
Par défaut, les éléments de type journaux suivent toutes les nouvelles
lignes apparaissant dans les fichiers journaux. Cependant, il existe des
applications qui, dans certaines situations, commencent à écrire un
nombre important de messages dans leurs fichiers journaux. Par exemple,
si une base de données ou un serveur DNS est injoignable, ces
applications inondent les fichiers journaux de milliers de messages
d'erreurs presque identiques jusqu'à ce que l'opération normale soit
restaurée. Par défaut, tous ces messages seront consciencieusement
analysés et les lignes correspondantes seront envoyées au serveur tel
que configuré dans les éléments log et logrt.
La protection intégrée contre les surcharges se compose d'un paramètre 'maxlines' configurable (protège le serveur contre trop de lignes entrantes correspondantes) et d'une limite 4*'maxlines' (protège le CPU et les E/S de la surcharge par l'agent). Pourtant, il y a 2 problèmes avec cette protection intégrée. Tout d'abord, un grand nombre de messages potentiellement non-informatifs sont rapportés au serveur et consomment de l'espace dans la base de données. Deuxièmement, en raison du nombre limité de lignes analysées par seconde, l'agent peut être à la traîne des derniers enregistrements de journaux pendant des heures. Très probablement, vous préférerez peut-être être informé plus tôt de la situation actuelle dans les fichiers journaux au lieu d'explorer les anciens enregistrements pendant des heures.
La solution aux deux problèmes utilise le paramètre 'maxdelay'. Si 'maxdelay' > 0 est spécifié, lors de chaque vérification du nombre d'octets traités, le nombre d'octets restants et le temps de traitement sont mesurés. A partir de ces nombres, l'agent calcule un délai estimé - combien de secondes il faudrait pour analyser tous les enregistrements restants dans un fichier journal.
Si le délai ne dépasse pas 'maxdelay', l'agent procède à l'analyse du fichier journal comme d'habitude.
Si le délai est supérieur à 'maxdelay', l'agent ignore un morceau d'un fichier journal en le "sautant" vers une nouvelle position estimée afin que les lignes restantes puissent être analysées dans les secondes "maxdelay".
Notez que l'agent ne lit même pas les lignes ignorées dans la mémoire tampon, mais calcule une position approximative pour accéder à un fichier.
Le fait de sauter des lignes de fichier journal est enregistré dans le fichier journal de l'agent comme ceci :
14287:20160602:174344.206 item:"logrt["/home/zabbix32/test[0-9].log",ERROR,,1000,,,120.0]"
logfile:"/home/zabbix32/test1.log" skipping 679858 bytes
(from byte 75653115 to byte 76332973) to meet maxdelayLe nombre "vers l'octet" est approximatif car après le "saut" l'agent ajuste la position dans le fichier au début d'une ligne de journal qui peut être plus loin dans le fichier ou un peu avant.
En fonction de la vitesse de croissance par rapport à la vitesse d'analyse du fichier journal, vous ne voyez pas du tout de "sauts", quelques "sauts" rares ou des "sauts" réguliers, des grands ou des petits "sauts", ou même un petit "saut" dans chaque vérification. Les fluctuations de la charge du système et de la latence du réseau affectent également le calcul du délai et, par conséquent, "sautent" en avant pour suivre le paramètre "maxdelay".
La définition de 'maxdelay' < 'intervalle d’actualisation' n'est pas recommandée (cela peut entraîner de petits "sauts" fréquents).
Remarques sur la gestion de 'copytruncate' dans la rotation des fichiers journaux
logrt avec l'option copytruncate suppose que différents fichiers
journaux ont des enregistrements différents (au moins leurs horodatages
sont différents), donc les sommes MD5 des blocs initiaux (jusqu'à 512
premiers octets) seront différentes. Deux fichiers avec les mêmes sommes
MD5 de blocs initiaux signifient que l'un d'eux est l'original, l'autre
- une copie.
logrt avec l'option copytruncate s'efforce de traiter correctement
les copies de fichiers journaux sans signaler les doublons. Cependant,
des choses telles que la production de plusieurs copies de fichiers
journaux avec le même horodatage, la rotation du fichier journal plus
souvent que l'intervalle de mise à jour de l'élément logrt[], le
redémarrage fréquent de l'agent ne sont pas recommandés. L'agent essaie
de gérer raisonnablement toutes ces situations, mais de bons résultats
ne peuvent pas être garantis en toutes circonstances.
Actions si la communication échoue entre l'agent et le serveur
Chaque ligne correspondante de l'élément log[] et logrt[] et le
résultat de chaque log.count[] et logrt.count[] requièrent un
emplacement libre dans la zone de 50% désignée dans le buffer d'envoi de
l'agent. Les éléments buffers sont régulièrement envoyés au serveur (ou
proxy) et les emplacements de mémoire tampon sont à nouveau libres.
Bien qu'il existe des emplacements libres dans la zone des fichiers journaux désignée dans le buffer d'envoi de l'agent et que la communication échoue entre l'agent et le serveur (ou le proxy), les résultats de la surveillance des fichiers journaux sont accumulés dans le buffer d'envoi. Cela aide à atténuer les échecs de communication ponctuel.
Pendant les échecs de communication plus longs, tous les emplacements de logs sont occupés et les actions suivantes sont effectuées :
- Les vérifications des éléments
log[]etlogrt[]sont arrêtées. Lorsque la communication est rétablie et que des emplacements sont libérés dans la mémoire tampon, les vérifications reprennent à partir de la position précédente. Aucune ligne correspondante n'est perdue, elles sont juste reportées plus tard. - Les vérifications
log.count[]etlogrt.count[]sont arrêtées simaxdelay = 0(par défaut). Le comportement est similaire aux élémentslog[]etlogrt[]décrits ci-dessus. Notez que cela peut affecter les résultats delog.count[]et delogrt.count[]: par exemple, une vérification compte 100 lignes correspondantes dans un fichier journal, mais comme il n'y a pas d'espace libre dans la mémoire tampon, la vérification est arrêtée. Lorsque la communication est restaurée, l'agent compte les mêmes 100 lignes correspondantes et 70 nouvelles lignes correspondantes. L'agent envoie maintenant compteur = 170 comme s'il avait été trouvé dans une vérification. - Les vérifications
log.count[]etlogrt.count[]avecmaxdelay > 0: s'il n'y a pas eu de "saut" pendant la vérification, alors le comportement est similaire à celui décrit ci-dessus. Si un "saut" sur les lignes du fichier journal a eu lieu, la position après le "saut" est conservée et le résultat compté est ignoré. Ainsi, l'agent essaie de suivre un fichier journal en expansion, même en cas d'échec de la communication