
5 Escalations
Overview
With escalations you can create custom scenarios for sending notifications or executing remote commands.
In practical terms it means that:
- Users can be informed about new problems immediately.
- Notifications can be repeated until the problem is resolved.
- Sending a notification can be delayed.
- Notifications can be escalated to another "higher" user group.
- Remote commands can be executed immediately or when a problem is not resolved for a lengthy period.
Actions are escalated based on the escalation step. Each step has a duration in time.
You can define both the default duration and a custom duration of an individual step. The minimum duration of one escalation step is 60 seconds.
You can start actions, such as sending notifications or executing commands, from any step. Step one is for immediate actions. If you want to delay an action, you can assign it to a later step. For each step, several actions can be defined.
The number of escalation steps is not limited.
Escalations are defined when configuring an operation. Escalations are supported for problem operations only, not recovery.
Miscellaneous aspects of escalation behavior
Let's consider what happens in different circumstances if an action contains several escalation steps.
| Situation | Behavior |
|---|---|
| The host in question goes into maintenance after the initial problem notification is sent | Depending on the Pause operations for suppressed problems setting in action configuration, all remaining escalation steps are executed either with a delay caused by the maintenance period or without delay. A maintenance period does not cancel operations. |
| The time period defined in the Time period action condition ends after the initial notification is sent | All remaining escalation steps are executed. The Time period condition cannot stop operations; it has effect with regard to when actions are started/not started, not operations. |
| A problem starts during maintenance and continues (is not resolved) after maintenance ends | Depending on the Pause operations for suppressed problems setting in action configuration, all escalation steps are executed either from the moment maintenance ends or immediately. |
| A problem starts during a no-data maintenance and continues (is not resolved) after maintenance ends | It must wait for the trigger to fire, before all escalation steps are executed. |
| Different escalations follow in close succession and overlap | The execution of each new escalation supersedes the previous escalation, but for at least one escalation step that is always executed on the previous escalation. This behavior is relevant in actions upon events that are created with EVERY problem evaluation of the trigger. |
| During an escalation in progress (like a message being sent), based on any type of event: - the action is disabled Based on trigger event: - the trigger is disabled - the host or item is disabled Based on internal event about triggers: - the trigger is disabled Based on internal event about items/low-level discovery rules: - the item is disabled - the host is disabled |
The message in progress is sent and then one more message on the escalation is sent. The follow-up message will have the cancellation text at the beginning of the message body (NOTE: Escalation canceled) naming the reason (for example, NOTE: Escalation canceled: action '<Action name>' disabled). This way the recipient is informed that the escalation is canceled and no more steps will be executed. This message is sent to all who received the notifications before. The reason of cancellation is also logged to the server log file (starting from Debug Level 3=Warning). Note that the Escalation canceled message is also sent if operations are finished, but recovery operations are configured and are not executed yet. |
| During an escalation in progress (like a message being sent) the action is deleted | No more messages are sent. The information is logged to the server log file (starting from Debug Level 3=Warning), for example: escalation canceled: action id:334 deleted |
Escalation examples
Example 1
Sending a repeated notification once every 30 minutes (5 times in total) to a "MySQL Administrators" group. To configure:
- In Operations tab, set the Default operation step duration to "30m" (30 minutes).
- Set the escalation Steps to be from "1" to "5".
- Select the "MySQL Administrators" group as the recipients of the message.
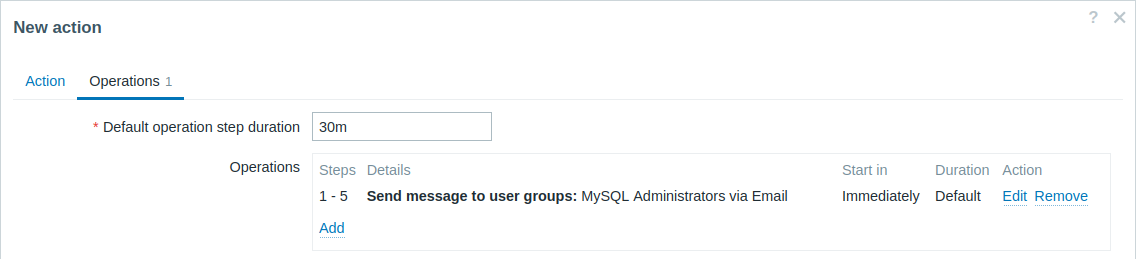
Notifications will be sent at 0:00, 0:30, 1:00, 1:30, 2:00 hours after the problem starts (unless, of course, the problem is resolved sooner).
If the problem is resolved and a recovery message is configured, it will be sent to those who received at least one problem message within this escalation scenario.
If the trigger that generated an active escalation is disabled, Zabbix sends an informative message about it to all those that have already received notifications.
Example 2
Sending a delayed notification about a long-standing problem. To configure:
- In Operations tab, set the Default operation step duration to "10h" (10 hours).
- Set the escalation Steps to be from "2" to "2".
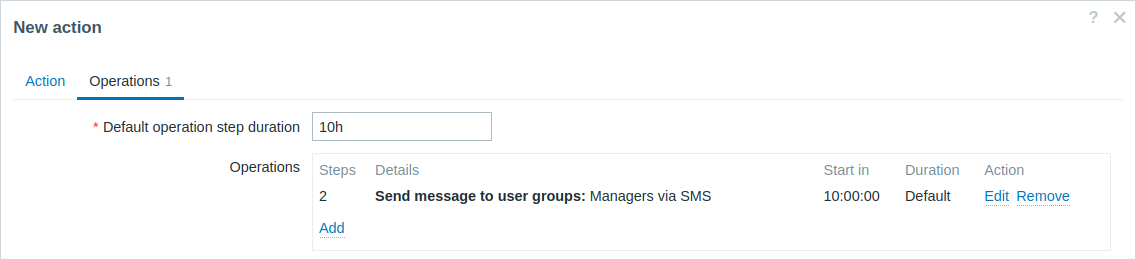
A notification will only be sent at Step 2 of the escalation scenario, or 10 hours after the problem starts.
You can customize the message text to something like "The problem is more than 10 hours old".
Example 3
Escalating the problem to the Boss.
In the first example above we configured periodical sending of messages to MySQL administrators. In this case, the administrators will get four messages before the problem will be escalated to the Database manager. Note that the manager will get a message only in case the problem is not acknowledged yet, supposedly no one is working on it.
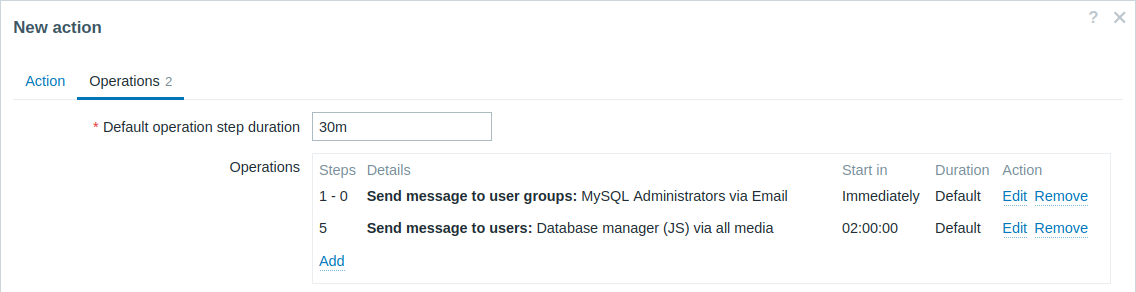
Details of Operation 2:
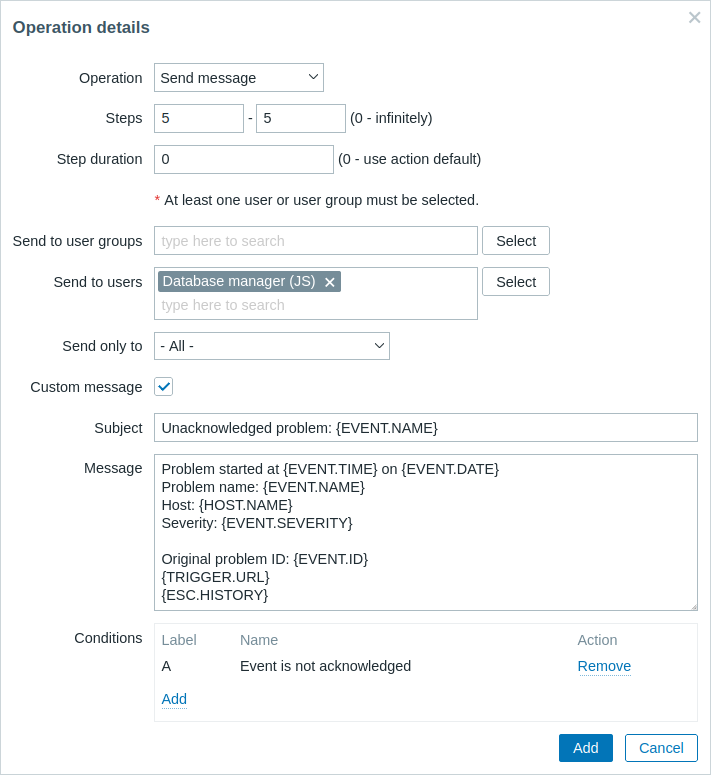
Note the use of {ESC.HISTORY} macro in the customized message. The macro will contain information about all previously executed steps on this escalation, such as notifications sent and commands executed.
Example 4
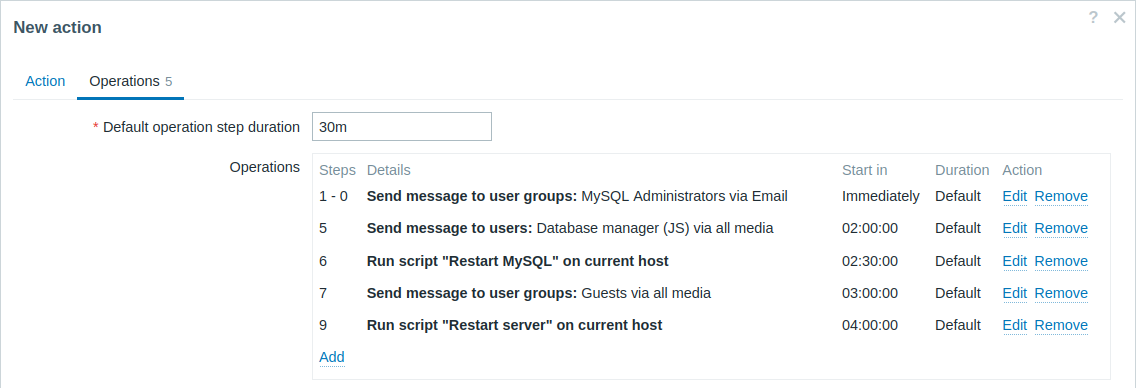
A more complex scenario. After multiple messages to MySQL administrators and escalation to the manager, Zabbix will try to restart the MySQL database. It will happen if the problem exists for 2:30 hours and it hasn't been acknowledged.
If the problem still exists, after another 30 minutes Zabbix will send a message to all guest users.
If this does not help, after another hour Zabbix will reboot server with the MySQL database (second remote command) using IPMI commands.
Example 5
An escalation with several operations that have overlapping step ranges and custom intervals. The default operation step duration is 30 minutes.
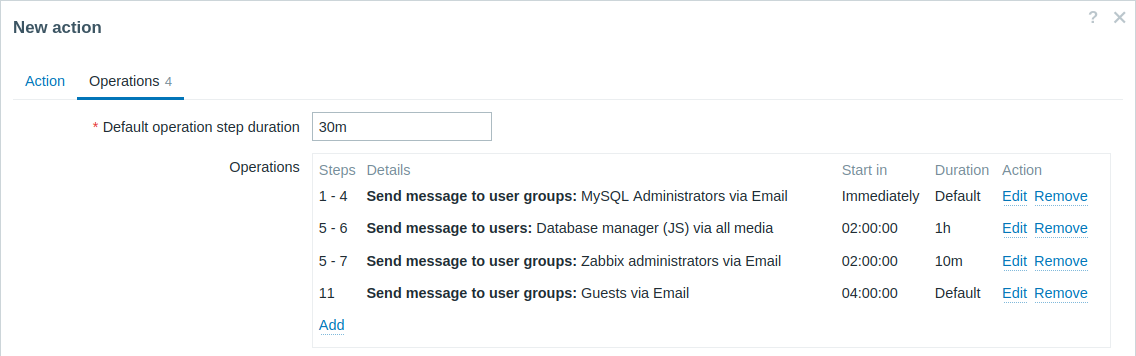
Notifications will be sent as follows:
- To MySQL administrators at 0:00, 0:30, 1:00, and 1:30 after the problem starts.
- To Database manager at 2:00 and 2:10 (the shorter custom step duration of 10 minutes defined in the subsequent operation overrides the longer step duration of 1 hour configured here, as outlined in Operation details for Step duration when steps overlap).
- To Zabbix administrators at 2:00, 2:10, and 2:20 after the problem starts (the custom step duration of 10 minutes is applied).
- To guest users at 4:00 after the problem starts (the default step duration of 30 minutes takes effect between steps 8 and 11).