
2 Dettagli di preelaborazione
Panoramica
Questa sezione fornisce i dettagli sul preprocessing del valore dell'item. Il preprocessing del valore dell'item consente di definire ed eseguire regole di trasformazione per i valori dell'item ricevuti.
Il preprocessing è gestito dal processo preprocessing manager insieme ai worker di preprocessing che eseguono i passaggi di preprocessing. Tutti i valori con preprocessing (prima di Zabbix 7.4.1, tutti i valori), ricevuti da diversi data gatherer, passano attraverso il preprocessing manager prima di essere aggiunti alla cache della history. La comunicazione IPC basata su socket viene utilizzata tra i data gatherer (poller, trapper, ecc.) e il processo di preprocessing. Il preprocessing viene eseguito da Zabbix server o da Zabbix proxy (per gli item monitorati dal proxy).
Elaborazione del valore dell'item
Per visualizzare il flusso dei dati dalla sorgente dati al database Zabbix, possiamo usare il seguente diagramma semplificato:
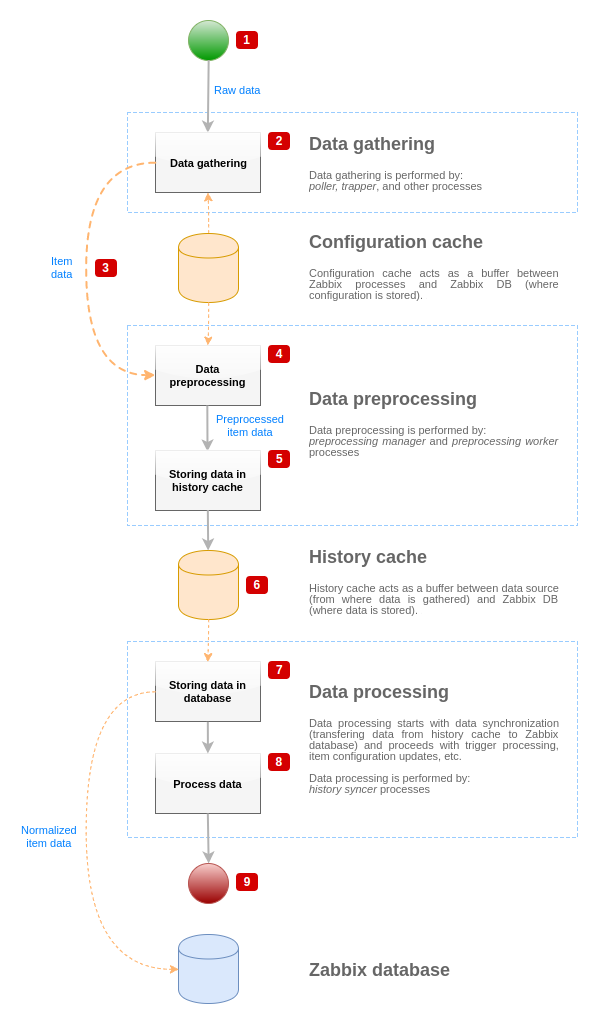
Il diagramma sopra mostra solo processi, oggetti e azioni relativi all'elaborazione del valore dell'item in forma semplificata. Il diagramma non mostra i cambiamenti condizionali di direzione, la gestione degli errori o i cicli. Anche la cache locale dei dati del manager di preprocessing non è mostrata, perché non influisce direttamente sul flusso dei dati. L'obiettivo di questo diagramma è mostrare i processi coinvolti nell'elaborazione del valore dell'item e il modo in cui interagiscono.
- La raccolta dei dati inizia con dati grezzi provenienti da una sorgente dati. In questa fase, i dati contengono solo ID, timestamp e valore (possono essere presenti anche più valori).
- Indipendentemente dal tipo di data gatherer utilizzato, il principio è lo stesso per i controlli attivi o passivi, per gli item trapper, ecc., poiché cambia solo il formato dei dati e l'iniziatore della comunicazione (o il data gatherer è in attesa di una connessione e dei dati, oppure il data gatherer avvia la comunicazione e richiede i dati). I dati grezzi vengono validati, la configurazione dell'item viene recuperata dalla cache di configurazione (i dati vengono arricchiti con i dati di configurazione).
- Viene utilizzato un meccanismo IPC basato su socket per passare i dati dai data gatherer al manager di preprocessing. In questa fase il data gatherer continua a raccogliere dati senza attendere la risposta dal manager di preprocessing.
- Viene eseguito il preprocessing dei dati. Questo include l'esecuzione dei passaggi di preprocessing e l'elaborazione degli item dipendenti.
Un item può cambiare il proprio stato in NOT SUPPORTED durante l'esecuzione del preprocessing se uno qualsiasi dei passaggi di preprocessing fallisce.
- I dati storici dalla cache locale dei dati del manager di preprocessing vengono svuotati nella history cache.
- A questo punto il flusso dei dati si interrompe fino alla successiva sincronizzazione della history cache (quando il processo history syncer esegue la sincronizzazione dei dati).
- Il processo di sincronizzazione inizia con la normalizzazione dei dati prima di memorizzarli nel database Zabbix. La normalizzazione dei dati esegue le conversioni al tipo di item desiderato (tipo definito nella configurazione dell'item), inclusa la troncatura dei dati testuali in base alle dimensioni predefinite consentite per tali tipi (HISTORY_STR_VALUE_LEN per string, HISTORY_TEXT_VALUE_LEN per text e HISTORY_LOG_VALUE_LEN per i valori log). I dati vengono inviati al database Zabbix dopo il completamento della normalizzazione.
Un item può cambiare il proprio stato in NOT SUPPORTED se la normalizzazione dei dati fallisce (ad esempio, quando un valore testuale non può essere convertito in numero).
- I dati raccolti vengono elaborati: vengono controllati i trigger, la configurazione dell'item viene aggiornata se l'item diventa NOT SUPPORTED, ecc.
- Questo è considerato la fine del flusso dei dati dal punto di vista dell'elaborazione del valore dell'item.
Preprocessing del valore dell'item
La pre-elaborazione dei dati viene eseguita nei seguenti passaggi:
- Se l'item non ha né pre-elaborazione né item dipendenti, il suo valore viene aggiunto alla cache della history oppure inviato al gestore LLD. In caso contrario, il valore dell'item viene passato al manager di pre-elaborazione tramite un meccanismo IPC basato su socket UNIX (prima di Zabbix 7.4.1, tutti i valori venivano passati attraverso il manager di pre-elaborazione prima di essere aggiunti alla cache della history o inviati al gestore LLD).
- Viene creato un task di pre-elaborazione, che viene aggiunto alla coda, e i worker di pre-elaborazione vengono notificati del nuovo task.
- A questo punto il flusso dei dati si interrompe finché non è disponibile almeno un worker di pre-elaborazione libero (cioè che non sta eseguendo alcun task).
- Quando un worker di pre-elaborazione è disponibile, preleva il task successivo dalla coda.
- Dopo il completamento della pre-elaborazione (sia in caso di esito negativo sia positivo dei passaggi di pre-elaborazione), il valore pre-elaborato viene aggiunto alla coda dei task completati e il manager viene notificato di un nuovo task completato.
- Il manager di pre-elaborazione converte il risultato nel formato desiderato (definito dal tipo di valore dell'item) e lo aggiunge alla cache della history oppure lo invia al gestore LLD.
- Se esistono item dipendenti per l'item elaborato, gli item dipendenti vengono aggiunti alla coda di pre-elaborazione con il valore pre-elaborato dell'item master. Gli item dipendenti vengono accodati bypassando le normali richieste di pre-elaborazione del valore, ma solo per gli item master con il valore impostato e non in stato NOT SUPPORTED.

Si noti che nel diagramma la pre-elaborazione dell'item master è leggermente semplificata omettendo la cache di pre-elaborazione.
Coda di preprocessing
La coda di preprocessing è organizzata come segue:
-
l'elenco delle attività in sospeso:
- attività create direttamente dalle richieste di preprocessing dei valori nell'ordine in cui sono state ricevute
-
l'elenco delle attività immediate (elaborate prima delle attività in sospeso):
- attività di test (create in risposta alle richieste di test di item/preprocessing dal frontend)
- attività degli item dipendenti
- attività di sequenza (attività che devono essere eseguite in un ordine rigoroso):
- con passaggi di preprocessing che utilizzano l'ultimo valore:
- modifica
- throttling
- JavaScript (cache del bytecode)
- cache del preprocessing degli item dipendenti
- con passaggi di preprocessing che utilizzano l'ultimo valore:
-
l'elenco delle attività completate
Cache di preprocessing
La cache di preprocessing è stata introdotta per migliorare le prestazioni del preprocessing per più item dipendenti che hanno passaggi di preprocessing simili (un risultato comune di LLD).
Il caching viene eseguito effettuando il preprocessing di un item dipendente e riutilizzando parte dei dati interni di preprocessing per il resto degli item dipendenti. La cache di preprocessing è supportata solo per il primo passaggio di preprocessing dei seguenti tipi:
- Pattern Prometheus (indicizza l'input in base alle metriche)
- JSONPath (analizza i dati in un albero di oggetti e indicizza la prima espressione
[?(@.path == "value")])
Worker di preprocessing
Il file di configurazione di Zabbix server consente agli utenti di impostare il numero di thread worker di preprocessing. Il parametro di configurazione StartPreprocessors deve essere utilizzato per impostare il numero di istanze preavviate dei worker di preprocessing, che dovrebbe almeno corrispondere al numero di core CPU disponibili.
Se le attività di preprocessing non sono limitate dalla CPU e comportano frequenti richieste di rete, si consiglia di configurare worker aggiuntivi. Il numero ottimale di worker di preprocessing può essere determinato da molti fattori, tra cui il numero di item "preprocessabili" (item che richiedono l'esecuzione di uno qualsiasi dei passaggi di preprocessing), il numero di processi di raccolta dati, il numero medio di passaggi per il preprocessing degli item, ecc. Un numero insufficiente di worker può causare un elevato utilizzo della memoria. Per la risoluzione dei problemi relativi all'utilizzo eccessivo della memoria nella propria installazione di Zabbix, vedere Profiling excessive memory usage with tcmalloc.
Tuttavia, supponendo che non vi siano operazioni di preprocessing pesanti come il parsing di grandi blocchi XML/JSON, il numero di worker di preprocessing può corrispondere al numero totale di processi di raccolta dati. In questo modo, nella maggior parte dei casi (tranne quando i dati dal processo di raccolta arrivano in blocco) ci sarà almeno un worker di preprocessing libero per i dati raccolti.
Troppi processi di raccolta dati (poller, unreachable poller, ODBC poller, HTTP poller, Java poller, pinger, trapper, proxypoller), insieme a IPMI manager, SNMP trapper e worker di preprocessing, possono esaurire il limite di file descriptor per processo del preprocessing manager.
L'esaurimento del limite di file descriptor per processo causerà l'arresto di Zabbix server, in genere poco dopo l'avvio, ma talvolta anche più tardi.
Per evitare tali problemi, rivedere il file di configurazione di Zabbix server per ottimizzare il numero di controlli e processi concorrenti.
Inoltre, se necessario, assicurarsi che il limite dei file descriptor sia impostato su un valore sufficientemente alto verificando e regolando i limiti di sistema.
Pipeline di elaborazione dei valori
L'elaborazione dei valori degli item viene eseguita in più passaggi (o fasi) da più processi. Questo può causare:
- Un item dipendente può ricevere valori, mentre il valore master NON può.
Questo può essere ottenuto utilizzando il seguente caso d'uso:
- L'item master ha il tipo di valore
UINT(può essere utilizzato un item trapper), l'item dipendente ha il tipo di valoreTEXT. - Non sono richiesti passaggi di preprocessing né per l'item master né per l'item dipendente.
- Un valore testuale (ad esempio, "abc") deve essere passato all'item master.
- Poiché non ci sono passaggi di preprocessing da eseguire, il gestore del preprocessing verifica che l'item master non sia nello stato NOT SUPPORTED e che il valore sia impostato (entrambe le condizioni sono vere) e mette in coda l'item dipendente con lo stesso valore dell'item master (poiché non ci sono passaggi di preprocessing).
- Quando sia l'item master sia l'item dipendente raggiungono la fase di sincronizzazione della history, l'item master diventa NOT SUPPORTED a causa dell'errore di conversione del valore (i dati testuali non possono essere convertiti in un intero senza segno).
- L'item master ha il tipo di valore
Di conseguenza, l'item dipendente riceve un valore, mentre l'item master cambia il proprio stato in NOT SUPPORTED.
- Un item dipendente riceve un valore che non è presente nella history dell'item master.
Il caso d'uso è molto simile al precedente, tranne
per il tipo dell'item master. Ad esempio, se per l'item master viene utilizzato
il tipo
CHAR, allora il valore dell'item master verrà troncato nella fase di sincronizzazione della history, mentre gli item dipendenti riceveranno i propri valori dal valore iniziale (non troncato) dell'item master.