
3 Descubrimiento de bajo nivel
Descripción general
La detección de bajo nivel (LLD) descubre automáticamente entidades (por ejemplo, sistemas de archivos, interfaces de red) en un host y crea los items, triggers y gráficos correspondientes sin necesidad de configuración manual para cada una.
Para usar LLD, se crea una regla de descubrimiento que recopila datos JSON que describen entidades, y prototipos (item, trigger y gráfico) para cada entidad.
El JSON devuelto por la regla debe ser un array de objetos, donde cada objeto representa una entidad descubierta mediante pares clave-valor. Por ejemplo, una regla de descubrimiento con net.if.discovery podría devolver:
[
{"{#IFNAME}": "lo"},
{"{#IFNAME}": "eth0"}
]A continuación, se crea un conjunto correspondiente de items, triggers y gráficos a partir de los prototipos: uno por cada interfaz (lo y eth0).
Si los objetos contienen claves en el formato {#MACRO}, esas macros se usan directamente en los prototipos. Si no es así, o si se requieren macros adicionales/personalizadas, las macros pueden definirse manualmente y asignarse a campos JSON mediante JSONPath.
LLD también puede crear hosts (por ejemplo, para máquinas virtuales descubiertas en un hipervisor) y admite reglas de descubrimiento anidadas para el descubrimiento multinivel.
Las entidades que ya no se descubren pueden deshabilitarse o eliminarse automáticamente.
Configuración del descubrimiento de bajo nivel
Ilustraremos el descubrimiento de bajo nivel con un ejemplo de descubrimiento del sistema de archivos.
Para configurar el descubrimiento, haga lo siguiente:
- Vaya a Data collection > Templates o Hosts.
- Haga clic en Discovery en la fila de la template o host correspondiente.

- Haga clic en Create discovery rule en la esquina superior derecha de la pantalla.
- Complete el formulario de la regla de descubrimiento con los detalles requeridos.
Regla de descubrimiento
El formulario de la regla de descubrimiento contiene cinco pestañas que representan, de izquierda a derecha, el flujo de datos durante el descubrimiento:
- Regla de descubrimiento - especifica, principalmente, el item integrado o script personalizado para recuperar los datos de descubrimiento.
- Preprocesamiento - aplica cierto preprocesamiento a los datos descubiertos.
- Macros LLD - permite extraer algunos valores de macros para usarlos en items, triggers, etc. descubiertos.
- Filtros - permite filtrar los valores descubiertos.
- Sobrescrituras - permite modificar items, triggers, gráficos o prototipos de host al aplicarse a objetos descubiertos específicos.
La pestaña Regla de descubrimiento contiene la clave del item que se utilizará para el descubrimiento (así como algunos atributos generales de la regla de descubrimiento):
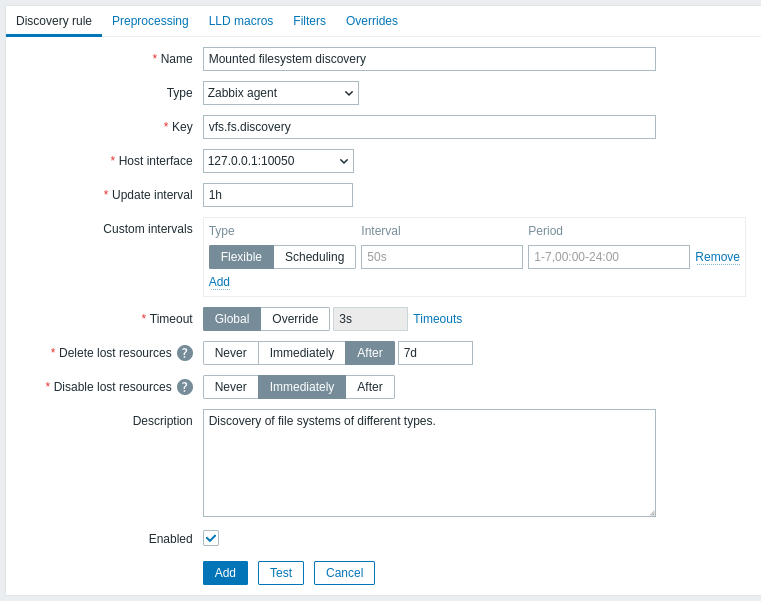
Todos los campos de entrada obligatorios están marcados con un asterisco rojo.
| Parameter | Description |
|---|---|
| Name | Nombre de la regla de descubrimiento. |
| Type | El tipo de comprobación para realizar el descubrimiento. En este ejemplo estamos usando un tipo de item Zabbix agent. La regla de descubrimiento también puede ser un item dependiente, dependiendo de un item normal. No puede depender de otra regla de descubrimiento. Para un item dependiente, seleccione el tipo correspondiente (Item dependiente) y especifique el item maestro en el campo 'Master item'. El item maestro debe existir. |
| Key | Introduzca la clave del item de descubrimiento (hasta 2048 caracteres). Por ejemplo, puede usar la clave de item integrada "vfs.fs.discovery" para devolver una cadena JSON con la lista de sistemas de archivos presentes en el equipo, sus tipos y opciones de montaje. Tenga en cuenta que otra opción para el descubrimiento de sistemas de archivos es usar resultados de descubrimiento mediante la clave de agent "vfs.fs.get" (consulte el ejemplo). |
| Update interval | Este campo especifica con qué frecuencia Zabbix realiza el descubrimiento. Al principio, cuando solo está configurando el descubrimiento de sistemas de archivos, puede que desee establecer un intervalo pequeño, pero una vez que sepa que funciona puede configurarlo en 30 minutos o más, porque los sistemas de archivos normalmente no cambian con mucha frecuencia. Se admiten sufijos de tiempo, por ejemplo, 30s, 1m, 2h, 1d. Se admiten macros de usuario. Nota: El intervalo de actualización solo puede establecerse en '0' si existen intervalos personalizados con un valor distinto de cero. Si se establece en '0' y existe un intervalo personalizado (flexible o programado) con un valor distinto de cero, el item será consultado durante la duración del intervalo personalizado. Las nuevas reglas de descubrimiento se comprobarán dentro de los 60 segundos posteriores a su creación, a menos que tengan Programación o Intervalo de actualización flexible y el Update interval esté establecido en 0. Tenga en cuenta que, para una regla de descubrimiento existente, el descubrimiento puede realizarse inmediatamente pulsando el botón Execute now. |
| Custom intervals | Puede crear reglas personalizadas para comprobar el item: Flexible - crea una excepción al Update interval (intervalo con una frecuencia diferente) Scheduling - crea una programación de sondeo personalizada. Para obtener información detallada, consulte Intervalos personalizados. |
| Timeout | Establezca el tiempo de espera de la comprobación de descubrimiento. Seleccione la opción de tiempo de espera: Global - se utiliza el tiempo de espera global/del proxy (mostrado en gris en el campo Timeout); Override - se utiliza un tiempo de espera personalizado (establecido en el campo Timeout; rango permitido: 1 - 600s). Se admiten sufijos de tiempo, por ejemplo, 30s, 1m, y macros de usuario. Al hacer clic en el enlace Timeouts puede configurar los tiempos de espera del proxy o los tiempos de espera globales (si no se utiliza un proxy). Tenga en cuenta que el enlace Timeouts solo es visible para usuarios del tipo Super admin con permisos para las secciones del frontend Administration > General o Administration > Proxies. |
| Delete lost resources | Especifique cuánto tiempo debe pasar para que la entidad descubierta se elimine una vez que su estado de descubrimiento pase a ser "Not discovered anymore": Never - no se eliminará; Immediately - se eliminará inmediatamente; After - se eliminará después del período de tiempo especificado. El valor debe ser mayor que el valor de Disable lost resources. Se admiten sufijos de tiempo, por ejemplo, 2h, 1d. Se admiten macros de usuario. Nota: No se recomienda usar "Immediately", ya que una edición incorrecta del filtro podría provocar que la entidad se elimine junto con todos los datos históricos. Tenga en cuenta que los recursos deshabilitados manualmente no serán eliminados por el descubrimiento de bajo nivel. |
| Disable lost resources | Especifique cuánto tiempo debe pasar para que la entidad descubierta se deshabilite una vez que su estado de descubrimiento pase a ser "Not discovered anymore": Never - no se deshabilitará; Immediately - se deshabilitará inmediatamente; After - se deshabilitará después del período de tiempo especificado. El valor debe ser mayor que el intervalo de actualización de la regla de descubrimiento. Tenga en cuenta que los recursos deshabilitados automáticamente volverán a habilitarse si son redescubiertos por el descubrimiento de bajo nivel. Los recursos deshabilitados manualmente no volverán a habilitarse si son redescubiertos. Este campo no se muestra si Delete lost resources está establecido en "Immediately". Se admiten sufijos de tiempo, por ejemplo, 2h, 1d. Se admiten macros de usuario. |
| Description | Introduzca una descripción. |
| Enabled | Si está marcado, la regla se procesará. |
No se conserva el historial de la regla de descubrimiento.
Preprocesamiento
La pestaña Preprocesamiento permite definir reglas de transformación para aplicar al resultado del descubrimiento. En este paso son posibles una o varias transformaciones. Las transformaciones se ejecutan en el orden en que se definen. Todo el preprocesamiento lo realiza el server de Zabbix.
Véase también:
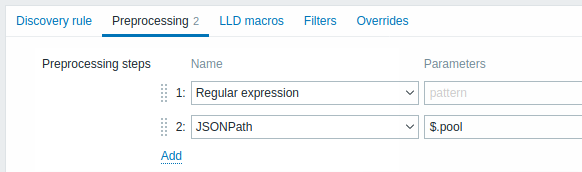
| Type | ||
|---|---|---|
| Transformation | Description | |
| Text | ||
| Regular expression | Coincide el valor recibido con la expresión regular <pattern> y reemplaza el valor con el <output> extraído. La expresión regular admite la extracción de un máximo de 10 grupos capturados con la secuencia \N. Parameters: pattern - expresión regular output - plantilla de formato de salida. Una secuencia de escape \N (donde N=1…9) se reemplaza por el grupo coincidente N. Una secuencia de escape \0 se reemplaza por el texto coincidente. Si marca la casilla Custom on fail, es posible especificar opciones personalizadas de manejo de errores: descartar el valor, establecer un valor especificado o establecer un mensaje de error especificado. |
|
| Replace | Busca la cadena de búsqueda y la reemplaza por otra (o por nada). Todas las apariciones de la cadena de búsqueda se reemplazarán. Parameters: search string - la cadena que se va a buscar y reemplazar, distingue mayúsculas y minúsculas (obligatorio) replacement - la cadena con la que se reemplazará la cadena de búsqueda. La cadena de reemplazo también puede estar vacía, lo que permite eliminar la cadena de búsqueda cuando se encuentre. Es posible usar secuencias de escape para buscar o reemplazar saltos de línea, retorno de carro, tabulaciones y espacios "\n \r \t \s"; la barra invertida puede escaparse como "\\" y las secuencias de escape pueden escaparse como "\\n". El escape de saltos de línea, retorno de carro y tabulaciones se realiza automáticamente durante el descubrimiento de bajo nivel. |
|
| Structured data | ||
| JSONPath | Extrae un valor o fragmento de datos JSON usando la funcionalidad JSONPath. Si marca la casilla Custom on fail, es posible especificar opciones personalizadas de manejo de errores: descartar el valor, establecer un valor especificado o establecer un mensaje de error especificado. |
|
| XML XPath | Extrae un valor o fragmento de datos XML usando la funcionalidad XPath. Para que esta opción funcione, el server de Zabbix debe estar compilado con soporte de libxml. Ejemplos: number(/document/item/value) extraerá 10 de <document><item><value>10</value></item></document>number(/document/item/@attribute) extraerá 10 de <document><item attribute="10"></item></document>/document/item extraerá <item><value>10</value></item> de <document><item><value>10</value></item></document>Tenga en cuenta que los espacios de nombres no son compatibles. Si marca la casilla Custom on fail, es posible especificar opciones personalizadas de manejo de errores: descartar el valor, establecer un valor especificado o establecer un mensaje de error especificado. |
|
| CSV to JSON | Convierte datos de un archivo CSV al formato JSON. Para más información, consulte: CSV to JSON preprocessing. |
|
| XML to JSON | Convierte datos en formato XML a JSON. Para más información, consulte: Serialization rules. Si marca la casilla Custom on fail, es posible especificar opciones personalizadas de manejo de errores: descartar el valor, establecer un valor especificado o establecer un mensaje de error especificado. |
|
| SNMP | ||
| SNMP walk value | Extrae el valor mediante el OID/nombre MIB especificado y aplica opciones de formato: Unchanged - devuelve Hex-STRING como cadena hexadecimal sin escape (note que los display hints siguen aplicándose); UTF-8 from Hex-STRING - convierte Hex-STRING a una cadena UTF-8; MAC from Hex-STRING - convierte Hex-STRING a una cadena de dirección MAC (en la que ' ' se reemplazará por ':');Integer from BITS - convierte los primeros 8 bytes de una cadena de bits expresada como una secuencia de caracteres hexadecimales (por ejemplo, "1A 2B 3C 4D") en un entero sin signo de 64 bits. En cadenas de bits de más de 8 bytes, los bytes siguientes se ignorarán. Si marca la casilla Custom on fail, es posible especificar opciones personalizadas de manejo de errores: descartar el valor, establecer un valor especificado o establecer un mensaje de error especificado. |
|
| SNMP walk to JSON | Convierte valores SNMP a JSON. Especifique un nombre de campo en el JSON y la ruta OID SNMP correspondiente. Los valores de los campos se rellenarán con los valores de la ruta OID SNMP especificada. Puede usar este paso de preprocesamiento para SNMP OID discovery. Están disponibles opciones de formato de valor similares a las del paso SNMP walk value. Si marca la casilla Custom on fail, es posible especificar opciones personalizadas de manejo de errores: descartar el valor, establecer un valor especificado o establecer un mensaje de error especificado. |
|
| SNMP get value | Aplica opciones de formato al valor SNMP get: UTF-8 from Hex-STRING - convierte Hex-STRING a una cadena UTF-8; MAC from Hex-STRING - convierte Hex-STRING a una cadena de dirección MAC (en la que ' ' se reemplazará por ':');Integer from BITS - convierte los primeros 8 bytes de una cadena de bits expresada como una secuencia de caracteres hexadecimales (por ejemplo, "1A 2B 3C 4D") en un entero sin signo de 64 bits. En cadenas de bits de más de 8 bytes, los bytes siguientes se ignorarán. Si marca la casilla Custom on fail, es posible especificar opciones personalizadas de manejo de errores: descartar el valor, establecer un valor especificado o establecer un mensaje de error especificado. |
|
| Custom scripts | ||
| JavaScript | Introduzca código JavaScript en el editor modal que se abre al hacer clic en el campo del parámetro o en el icono del lápiz junto a él. Tenga en cuenta que la longitud disponible de JavaScript depende de la base de datos utilizada. Para más información, consulte: Javascript preprocessing |
|
| Validation | ||
| Does not match regular expression | Especifique una expresión regular con la que un valor no debe coincidir. Por ejemplo, Error:(.*?)\.Si marca la casilla Custom on fail, es posible especificar opciones personalizadas de manejo de errores: descartar el valor, establecer un valor especificado o establecer un mensaje de error especificado. |
|
| Check for error in JSON | Comprueba si existe un mensaje de error a nivel de aplicación ubicado en JSONPath. Detiene el procesamiento si tiene éxito y el mensaje no está vacío; de lo contrario, continúa procesando con el valor que había antes de este paso de preprocesamiento. Tenga en cuenta que estos errores del servicio externo se muestran al usuario tal cual, sin añadir información del paso de preprocesamiento. Por ejemplo, $.errors. Si se recibe un JSON como {"errors":"e1"}, no se ejecutará el siguiente paso de preprocesamiento.Si marca la casilla Custom on fail, es posible especificar opciones personalizadas de manejo de errores: descartar el valor, establecer un valor especificado o establecer un mensaje de error especificado. |
|
| Check for error in XML | Comprueba si existe un mensaje de error a nivel de aplicación ubicado en Xpath. Detiene el procesamiento si tiene éxito y el mensaje no está vacío; de lo contrario, continúa procesando con el valor que había antes de este paso de preprocesamiento. Tenga en cuenta que estos errores del servicio externo se muestran al usuario tal cual, sin añadir información del paso de preprocesamiento. No se informará ningún error en caso de que falle el análisis de XML no válido. Si marca la casilla Custom on fail, es posible especificar opciones personalizadas de manejo de errores: descartar el valor, establecer un valor especificado o establecer un mensaje de error especificado. |
|
| Matches regular expression | Especifique una expresión regular con la que un valor debe coincidir. Si marca la casilla Custom on fail, es posible especificar opciones personalizadas de manejo de errores: descartar el valor, establecer un valor especificado o establecer un mensaje de error especificado. |
|
| Throttling | ||
| Discard unchanged with heartbeat | Descarta un valor si no ha cambiado dentro del período de tiempo definido (en segundos). Se admiten valores enteros positivos para especificar los segundos (mínimo - 1 segundo). En este campo se pueden usar sufijos de tiempo (por ejemplo, 30s, 1m, 2h, 1d). En este campo se pueden usar macros de usuario y macros de descubrimiento de bajo nivel. Solo se puede especificar una opción de limitación para un item de descubrimiento. Por ejemplo, 1m. Si se pasa el mismo texto a esta regla dos veces en un intervalo de 60 segundos, se descartará.Note: Cambiar prototipos de item no restablece la limitación. La limitación solo se restablece cuando se cambian los pasos de preprocesamiento. |
|
| Prometheus | ||
| Prometheus to JSON | Convierte las métricas de Prometheus requeridas a JSON. Consulte Prometheus checks para más detalles. |
|
Tenga en cuenta que si la regla de descubrimiento se ha aplicado al host mediante un template, el contenido de esta pestaña es de solo lectura.
Macros personalizadas
La pestaña Macros LLD permite especificar macros de bajo nivel de descubrimiento personalizadas.
Las macros personalizadas son útiles en los casos en que el JSON devuelto no tiene las macros necesarias ya definidas. Así, por ejemplo:
- La clave nativa
vfs.fs.discoverypara el descubrimiento de sistemas de archivos devuelve un JSON con algunas macros LLD predefinidas como {#FSNAME}, {#FSTYPE}. Estas macros pueden utilizarse directamente en prototipos de item, trigger (ver secciones posteriores de la página); no es necesario definir macros personalizadas; - El item de agent
vfs.fs.gettambién devuelve un JSON con datos de sistema de archivos, pero sin ninguna macro LLD predefinida. En este caso puede definir las macros usted mismo y asignarlas a los valores del JSON utilizando JSONPath:

Los valores extraídos pueden utilizarse en items, triggers, etc. descubiertos. Tenga en cuenta que los valores se extraerán del resultado del descubrimiento y de cualquier paso de preprocesamiento realizado hasta el momento.
| Parámetro | Descripción |
|---|---|
| Macro LLD | Nombre de la macro de bajo nivel de descubrimiento, utilizando la siguiente sintaxis: {#MACRO}. |
| JSONPath | Ruta que se utiliza para extraer el valor de la macro LLD de una fila LLD, utilizando la sintaxis JSONPath. Los valores extraídos del JSON devuelto se utilizan para reemplazar las macros LLD en los campos de prototipo de item, trigger, etc. JSONPath puede especificarse utilizando la notación de puntos o la notación de corchetes. La notación de corchetes debe utilizarse en caso de caracteres especiales y Unicode, como $['unicode + special chars #1']['unicode + special chars #2'].Por ejemplo, $.foo extraerá "bar" y "baz" de este JSON: [{"foo":"bar"}, {"foo":"baz"}]Tenga en cuenta que $.foo también extraerá "bar" y "baz" de este JSON: {"data":[{"foo":"bar"}, {"foo":"baz"}]} porque un único objeto "data" se procesa automáticamente (por compatibilidad con versiones anteriores con la implementación de bajo nivel de descubrimiento en Zabbix versiones anteriores a la 4.2). |
Filtro
Se puede usar un filtro para generar items, triggers y gráficos reales solo para las entidades que coincidan con los criterios. La pestaña Filters contiene definiciones de filtros de la regla de descubrimiento que permiten filtrar los valores de descubrimiento:
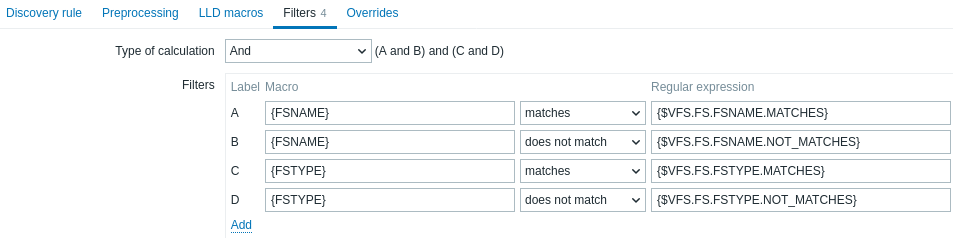
| Parameter | Description |
|---|---|
| Type of calculation | Las siguientes opciones para calcular filtros están disponibles: And - todos los filtros deben cumplirse; Or - basta con que se cumpla un filtro; And/Or - usa And con distintos nombres de macro y Or con el mismo nombre de macro; Custom expression - ofrece la posibilidad de definir un cálculo personalizado de los filtros. La fórmula debe incluir todos los filtros de la lista. Limitado a 255 símbolos. |
| Filters | Los siguientes operadores de condición de filtro están disponibles: matches, does not match, exists, does not exist. Los operadores Matches y does not match esperan una Perl Compatible Regular Expression (PCRE). Puede introducir una expresión regular o hacer referencia a una expresión regular global en el campo Regular expression. Los operadores Exists y does not exist permiten filtrar entidades según la presencia o ausencia de la macro LLD especificada en la respuesta. Tenga en cuenta que, si falta una macro del filtro en la respuesta, la entidad encontrada se ignorará, a menos que se especifique una condición "does not exist" para esta macro. Se mostrará una advertencia si la ausencia de una macro afecta al resultado de la expresión. Por ejemplo, si {#B} falta en:{#A} matches 1 and {#B} matches 2 - mostrará una advertencia{#A} matches 1 or {#B} matches 2 - no mostrará advertencia. |
Por ejemplo, si solo le interesan los sistemas de archivos C:, D: y E:, puede poner {#FSNAME} en el campo Macro y ^C|^D|^E en el campo Regular expression.
También es posible filtrar por tipos de sistema de archivos usando la macro {#FSTYPE} (por ejemplo, ^ext|^reiserfs) y por tipos de unidad (solo compatible con el agent de Windows) usando la macro {#FSDRIVETYPE} (por ejemplo, fixed).
Para probar una expresión regular puede usar grep -E, por ejemplo:
for f in ext2 nfs reiserfs smbfs;
do echo $f | grep -E '^ext|^reiserfs' || echo "SKIP: $f";
doneUn error o una errata en la expresión regular usada en la regla LLD (por ejemplo, una expresión regular incorrecta de "File systems for discovery") puede provocar la eliminación de miles de elementos de configuración, valores históricos y eventos de muchos hosts.
La base de datos de Zabbix en MySQL debe crearse con distinción entre mayúsculas y minúsculas si se desea descubrir correctamente nombres de sistemas de archivos que solo difieren en el uso de mayúsculas.
Anulación
La pestaña Overrides permite establecer reglas para modificar la lista de prototipos de item, trigger, gráfico, host y descubrimiento, o sus atributos, para los objetos descubiertos que cumplan los criterios dados.
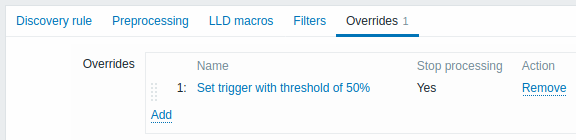
Los overrides, si los hay, se muestran en una lista reordenable mediante arrastrar y soltar y se ejecutan en el orden en que están definidos. Para configurar los detalles de un nuevo override, haga clic en  en el bloque Overrides.
Para editar un override existente, haga clic en el nombre del override.
Se abrirá una ventana emergente que permitirá editar los detalles de la regla de override.
en el bloque Overrides.
Para editar un override existente, haga clic en el nombre del override.
Se abrirá una ventana emergente que permitirá editar los detalles de la regla de override.
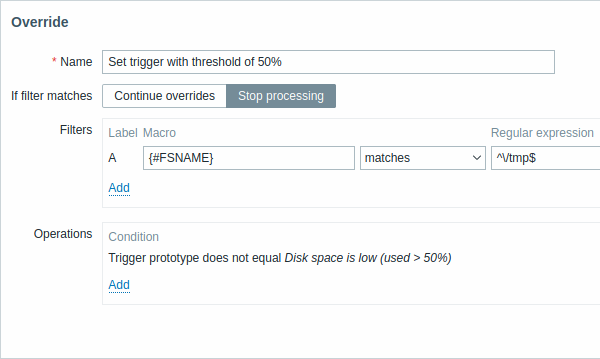
Todos los parámetros obligatorios están marcados con asteriscos rojos.
| Parameter | Description |
|---|---|
| Name | Un nombre de override único (por regla de LLD). |
| If filter matches | Define si los siguientes overrides deben procesarse cuando se cumplen las condiciones del filtro: Continue overrides - se procesarán los overrides posteriores. Stop processing - se ejecutarán las operaciones de los overrides anteriores (si las hay) y de este override, y se ignorarán los overrides posteriores para las filas de LLD coincidentes. |
| Filters | Determina a qué entidades descubiertas debe aplicarse el override. Los filtros de override se procesan después de los filtros de la regla de descubrimiento y tienen la misma funcionalidad. |
| Operations | Las operaciones de override se muestran con estos detalles: Condition - un tipo de objeto y una condición que debe cumplirse para el nombre del objeto; por ejemplo: el prototipo de trigger no es igual a Disk space is low (used > 50%). Actions - se muestran enlaces para editar y eliminar una operación. |
Configuración de una operación
Para configurar los detalles de una nueva operación, haga clic en en el bloque Operations.
Para editar una operación existente, haga clic en  junto a la operación.
Se abrirá una ventana emergente donde podrá editar los detalles de la operación.
junto a la operación.
Se abrirá una ventana emergente donde podrá editar los detalles de la operación.
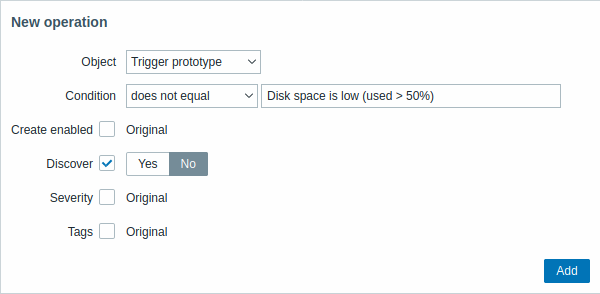
| Parameter | Description | ||
|---|---|---|---|
| Object | Hay cinco tipos de objetos disponibles: Prototipo de item Prototipo de trigger Prototipo de gráfico Prototipo de host Prototipo de descubrimiento |
||
| Condition | Permite filtrar las entidades a las que debe aplicarse la operación. | ||
| Operator | Operadores compatibles: equals - aplicar a este prototipo does not equal - aplicar a todos los prototipos, excepto a este contains - aplicar si el nombre del prototipo contiene esta cadena does not contain - aplicar si el nombre del prototipo no contiene esta cadena matches - aplicar si el nombre del prototipo coincide con una expresión regular does not match - aplicar si el nombre del prototipo no coincide con una expresión regular |
||
| Pattern | Una expresión regular o una cadena que se desea buscar. | ||
| Object: Item prototype | |||
| Create enabled | Cuando la casilla está marcada, aparecerán los botones que permiten anular la configuración original del prototipo de item: Yes - el item se añadirá en estado habilitado. No - el item se añadirá a una entidad descubierta, pero en estado deshabilitado. |
||
| Discover | Cuando la casilla está marcada, aparecerán los botones que permiten anular la configuración original del prototipo de item: Yes - el item se añadirá. No - el item no se añadirá. |
||
| Update interval | Cuando la casilla está marcada, aparecerán dos opciones que permiten establecer un intervalo diferente para el item: Delay - intervalo de actualización del item. Se admiten macros de usuario, macros de LLD y sufijos de tiempo (por ejemplo, 30s, 1m, 2h, 1d) (la compatibilidad con macros de LLD se restauró en Zabbix 7.4.11). Debe establecerse en 0 si se usa Custom interval. Custom interval - haga clic en para especificar intervalos flexibles o programados. Para obtener información detallada, consulte Custom intervals. |
||
| History | Cuando la casilla está marcada, aparecerán los botones que permiten establecer un período de almacenamiento de historial diferente para el item: Do not store - si se selecciona, el historial no se almacenará. Store up to - si se selecciona, aparecerá a la derecha un campo de entrada para especificar el período de almacenamiento. Se admiten macros de usuario y macros de LLD (la compatibilidad con macros de LLD se restauró en Zabbix 7.4.11). |
||
| Trends | Cuando la casilla está marcada, aparecerán los botones que permiten establecer un período de almacenamiento de tendencias diferente para el item: Do not store - si se selecciona, las tendencias no se almacenarán. Store up to - si se selecciona, aparecerá a la derecha un campo de entrada para especificar el período de almacenamiento. Se admiten macros de usuario y macros de LLD (la compatibilidad con macros de LLD se restauró en Zabbix 7.4.11). |
||
| Tags | Cuando la casilla está marcada, aparecerá un nuevo bloque que permite especificar pares etiqueta-valor. Se admiten macros de usuario y macros de LLD. Estas etiquetas se añadirán a las etiquetas especificadas en el prototipo de item, incluso si los nombres de las etiquetas coinciden. |
||
| Object: Trigger prototype | |||
| Create enabled | Cuando la casilla está marcada, aparecerán los botones que permiten anular la configuración original del prototipo de trigger: Yes - el trigger se añadirá en estado habilitado. No - el trigger se añadirá a una entidad descubierta, pero en estado deshabilitado. |
||
| Discover | Cuando la casilla está marcada, aparecerán los botones que permiten anular la configuración original del prototipo de trigger: Yes - el trigger se añadirá. No - el trigger no se añadirá. |
||
| Severity | Cuando la casilla está marcada, aparecerán los botones de severidad del trigger, que permiten modificar la severidad del trigger. | ||
| Tags | Cuando la casilla está marcada, aparecerá un nuevo bloque que permite especificar pares etiqueta-valor. Se admiten macros de usuario y macros de LLD. Estas etiquetas se añadirán a las etiquetas especificadas en el prototipo de trigger, incluso si los nombres de las etiquetas coinciden. |
||
| Object: Graph prototype | |||
| Discover | Cuando la casilla está marcada, aparecerán los botones que permiten anular la configuración original del prototipo de gráfico: Yes - el gráfico se añadirá. No - el gráfico no se añadirá. |
||
| Object: Host prototype | |||
| Create enabled | Cuando la casilla está marcada, aparecerán los botones que permiten anular la configuración original del prototipo de host: Yes - el host se creará en estado habilitado. No - el host se creará en estado deshabilitado. |
||
| Discover | Cuando la casilla está marcada, aparecerán los botones que permiten anular la configuración original del prototipo de host: Yes - el host se descubrirá. No - el host no se descubrirá. |
||
| Link templates | Cuando la casilla está marcada, aparecerá un campo de entrada para especificar templates. Empiece a escribir el nombre del template o haga clic en Select junto al campo y seleccione templates de la lista en una ventana emergente. Los templates de este override se añaden a todos los templates ya vinculados al prototipo de host. |
||
| Tags | Cuando la casilla está marcada, aparecerá un nuevo bloque que permite especificar pares etiqueta-valor. Se admiten macros de usuario y macros de LLD. Estas etiquetas se añadirán a las etiquetas especificadas en el prototipo de host, incluso si los nombres de las etiquetas coinciden. |
||
| Host inventory | Cuando la casilla está marcada, aparecerán los botones que permiten seleccionar un modo de inventario diferente para el prototipo de host: Disabled - no rellenar el inventario del host Manual - proporcionar los detalles manualmente Automated - completar automáticamente los datos del inventario del host en función de las métricas recopiladas. |
||
| Object: Discovery prototype | |||
| Create enabled | Cuando la casilla está marcada, aparecerán los botones que permiten anular la configuración original del prototipo de descubrimiento: Yes - la regla de descubrimiento se añadirá en estado habilitado. No - la regla de descubrimiento se añadirá en estado deshabilitado. |
||
| Discover | Cuando la casilla está marcada, aparecerán los botones que permiten anular la configuración original del prototipo de descubrimiento: Yes - la regla de descubrimiento se añadirá. No - la regla de descubrimiento no se añadirá. |
||
| Update interval | Cuando la casilla está marcada, aparecerán dos opciones que permiten establecer un intervalo diferente para la regla de descubrimiento: Delay - intervalo de actualización de la regla. Se admiten macros de usuario, macros de LLD y sufijos de tiempo (por ejemplo, 30s, 1m, 2h, 1d). Debe establecerse en 0 si se usa Custom interval. Custom interval - haga clic en para especificar intervalos flexibles o programados. Para obtener información detallada, consulte Custom intervals. |
||
Botones del formulario
Los botones en la parte inferior del formulario permiten realizar varias operaciones.
 |
Agregar una regla de descubrimiento. Este botón solo está disponible para nuevas reglas de descubrimiento. |
 |
Actualizar las propiedades de una regla de descubrimiento. Este botón solo está disponible para reglas de descubrimiento existentes. |
 |
Crear otra regla de descubrimiento basada en las propiedades de la regla de descubrimiento actual. |
 |
Realizar el descubrimiento basado en la regla de descubrimiento inmediatamente. La regla de descubrimiento ya debe existir. Vea más detalles. Nota que al realizar el descubrimiento inmediatamente, la caché de configuración no se actualiza, por lo que el resultado no reflejará los cambios más recientes en la configuración de la regla de descubrimiento. |
 |
Probar la configuración de la regla de descubrimiento. Utilice este botón para verificar la configuración (como la conectividad y la corrección de los parámetros) sin aplicar permanentemente ningún cambio. |
 |
Eliminar la regla de descubrimiento. |
 |
Cancelar la edición de las propiedades de la regla de descubrimiento. |
Entidades descubiertas
Las siguientes capturas de pantalla ilustran cómo se ven los items, triggers y gráficos descubiertos en la configuración del host. Las entidades descubiertas están precedidas por un enlace naranja a la regla de descubrimiento de la que provienen.

Tenga en cuenta que las entidades descubiertas no se crearán en caso de que ya existan entidades con los mismos criterios de unicidad, por ejemplo, un item con la misma clave o un gráfico con el mismo nombre. En este caso, se muestra un mensaje de error en el frontend indicando que la regla de descubrimiento de bajo nivel no pudo crear ciertas entidades. Sin embargo, la propia regla de descubrimiento no se volverá no soportada porque alguna entidad no pudo ser creada y tuvo que ser omitida. La regla de descubrimiento continuará creando/actualizando otras entidades.
Si una entidad descubierta (host, sistema de archivos, interfaz, etc.) deja de ser descubierta (o ya no pasa el filtro), las entidades que se crearon en base a ella pueden ser deshabilitadas automáticamente y eventualmente eliminadas.
Los recursos perdidos pueden ser deshabilitados automáticamente según el valor del parámetro Deshabilitar recursos perdidos. Esto afecta a los hosts, items y triggers perdidos.
Los recursos perdidos pueden ser eliminados automáticamente según el valor del parámetro Eliminar recursos perdidos. Esto afecta a los hosts, grupos de hosts, items, triggers y gráficos perdidos.
Cuando las entidades descubiertas pasan a estar 'Ya no descubiertas', se muestra un indicador de tiempo de vida en la lista de entidades. Mueva el puntero del ratón sobre él y se mostrará un mensaje que indica los detalles de su estado.

Si las entidades fueron marcadas para su eliminación, pero no se eliminaron en el momento esperado (regla de descubrimiento o host del item deshabilitado), se eliminarán la próxima vez que se procese la regla de descubrimiento.
Las entidades que contienen otras entidades, que están marcadas para su eliminación, no se actualizarán si se cambian a nivel de la regla de descubrimiento. Por ejemplo, los triggers basados en LLD no se actualizarán si contienen items que están marcados para su eliminación.


Otros tipos de descubrimiento
Más detalles y procedimientos sobre otros tipos de descubrimiento listos para usar están disponibles en las siguientes secciones:
- descubrimiento de interfaces de red
- descubrimiento de CPUs y núcleos de CPU
- descubrimiento de OIDs SNMP
- descubrimiento de objetos JMX;
- descubrimiento usando consultas SQL ODBC
- descubrimiento de servicios de Windows
- descubrimiento de interfaces de host en Zabbix
Para más detalles sobre el formato JSON para items de descubrimiento y un ejemplo de cómo implementar su propio descubridor de sistemas de archivos como un script Perl, consulte creación de reglas LLD personalizadas.