
2. Дополнительные сведения о предобработке
Обзор
В этом разделе приведены сведения о предварительной обработке значений элементов данных. Предварительная обработка значений элементов данных позволяет определять и выполнять правила преобразования для полученных значений элементов данных.
Предварительная обработка управляется процессом менеджера предварительной обработки вместе с рабочими процессами предварительной обработки, которые выполняют этапы предварительной обработки. Все значения с предварительной обработкой (до Zabbix 7.4.1 — все значения), полученные от разных сборщиков данных, проходят через менеджер предварительной обработки перед добавлением в кэш истории. Для связи между сборщиками данных (опросчиками, ловушками и т. д.) и процессом предварительной обработки используется IPC-связь на основе сокетов. Этапы предварительной обработки выполняет либо сервер Zabbix, либо прокси Zabbix (для элементов данных, контролируемых прокси).
Обработка значений элементов данных
Для визуализации потока данных от источника данных к базе данных Zabbix мы можем использовать следующую упрощённую диаграмму:
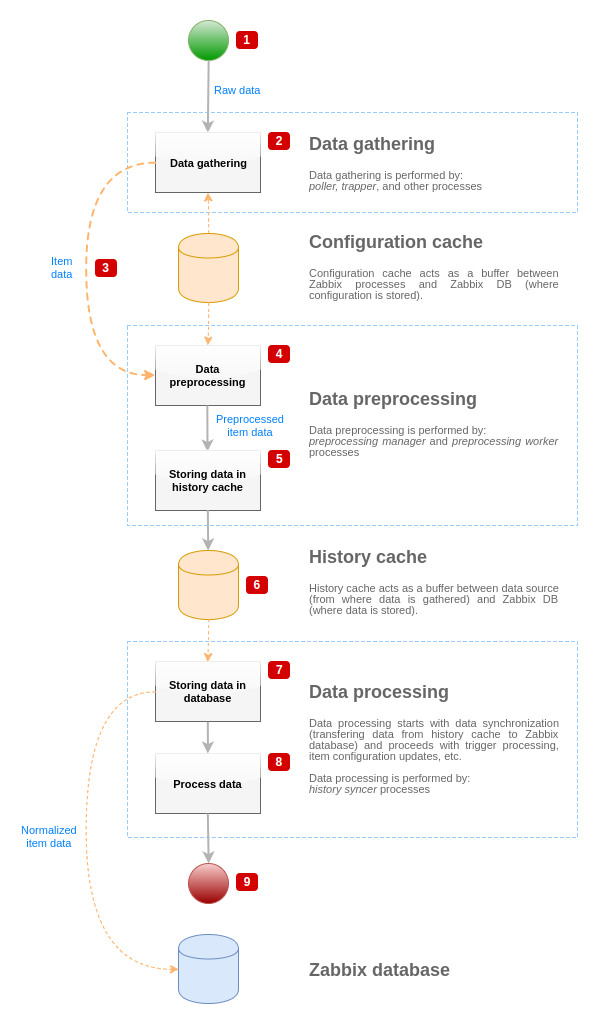
Диаграмма выше в упрощённой форме показывает только процессы, объекты и действия, которые связаны с предварительной обработкой значений элементов данных. Диаграмма не отображает изменения направлений при различных условиях, обработку ошибок или циклы. Локальный кэш данных в менеджере предобработки тоже не показан, так как он не влияет напрямую на поток данных. Цель этой диаграммы — показать процессы, вовлечённые в обработку значений элементов данных, а также способ их взаимодействия.
- Сбор данных начинается с сырых данных от источника данных. В этот момент данные содержат только ID, штамп времени и значение (также может быть несколько значений).
- Не важно, какой используется тип сборщика данных, идея одинакова для активных, пассивных проверок, для траппер элементов данных и т.д., поскольку меняется только формат данных и инициатор передачи (либо сборщик данных ожидает соединение и данные, либо сборщик данных инициирует соединение и запрашивает данные). Сырые данные проверяются, конфигурация элемента данных извлекается из кэша конфигурации (в данные добавляются конфигурационные данные).
- Механизм IPC на основе сокета используется для передачи данных от сборщиков данных к менеджеру предобработки. В этот момент сборщик данных продолжает сбор данных без ожидания ответа от менеджера предварительной обработки.
- Выполняется предварительная обработка данных. Это включает в себя выполнение шагов предварительной обработки и обработку зависимых элементов данных.
В процессе выполнения предварительной обработки элемент данных может изменить свое состояние на НЕ ПОДДЕРЖИВАЕТСЯ, если какой-либо шаг предварительной обработки завершается с ошибкой.
- Данные истории из локального кэша данных менеджера предобработки сбрасываются в кэш истории.
- Тут поток данных останавливается до следующей синхронизации кэша истории (когда процесс history syncer выполняет синхронизацию данных).
- Процесс синхронизации начинается с нормализации данных перед сохранением в базу данных Zabbix. Нормализация данных выполняет преобразования в желаемый тип элемента данных (тип, заданный в конфигурации элемента данных), включая обрезку текстовых данных на основе предопределённых размеров для этих типов (HISTORY_STR_VALUE_LEN для строк, HISTORY_TEXT_VALUE_LEN для текста и HISTORY_LOG_VALUE_LEN для журнал (лог) значений). Данные будут отправлены в базу данных Zabbix после завершения нормализации.
Элемент данных может изменить своё состояние на НЕ ПОДДЕРЖИВАЕТСЯ, если процесс нормализации завершится с ошибкой (например, когда текстовое значение не удалось преобразовать в число).
- Выполняется обработка собранных данных — проверяются триггеры, обновляется конфигурация элементов данных, если элемент данных становится НЕПОДДЕРЖИВАЕМЫМ, и тому подобное.
- Этот момент считается завершением потока данных с точки зрения обработки значений элементов данных.
Предобработка значения элемента данных
Предобработка данных выполняется в следующих шагах:
- Если у элемента данных нет ни предобработки, ни зависимых элементов, его значение либо добавляется в кэш истории, либо отправляется менеджеру LLD. В противном случае значение элемента данных передается менеджеру предобработки с использованием механизма IPC на основе UNIX socket (до Zabbix 7.4.1 все значения проходили через менеджер предобработки до добавления в кэш истории или отправки менеджеру LLD).
- Создается задача предобработки, она добавляется в очередь, и рабочие процессы предобработки уведомляются о новой задаче.
- На этом этапе поток данных останавливается, пока не появится хотя бы один свободный (то есть не выполняющий никаких задач) рабочий процесс предобработки.
- Когда рабочий процесс предобработки становится доступен, он берет следующую задачу из очереди.
- После завершения предобработки (как при неудачном, так и при успешном выполнении шагов предобработки) предварительно обработанное значение добавляется в очередь завершенных задач, и менеджер уведомляется о новой завершенной задаче.
- Менеджер предобработки преобразует результат в нужный формат (определяемый типом значения элемента данных) и либо добавляет его в кэш истории, либо отправляет менеджеру LLD.
- Если для обрабатываемого элемента данных есть зависимые элементы, то они добавляются в очередь предобработки с предварительно обработанным значением основного элемента данных. Зависимые элементы помещаются в очередь в обход обычных запросов на предобработку значений, но только для основных элементов данных, у которых значение задано и которые не находятся в состоянии NOT SUPPORTED.

Обратите внимание, что на диаграмме предобработка основного элемента данных немного упрощена за счет пропуска кэширования предобработки.
Очередь предварительной обработки
Очередь предварительной обработки организована следующим образом:
-
список ожидающих задач:
- задачи, созданные непосредственно из запросов предварительной обработки значений в порядке их получения
-
список немедленных задач (обрабатываемых до ожидающих задач):
- задачи тестирования (созданы в ответ на запросы тестирования элементов данных/предварительной обработки веб-интерфейсом)
- задачи зависимых элементов данных
- последовательные задачи (задачи, которые должны выполняться в строгом порядке):
- имеющие шаги предварительной обработки с использованием последнего значения:
- изменение
- троттлинг
- JavaScript (кэширование байт-кода)
- кэширование предварительной обработки зависимых элементов данных
-
список завершённых задач
Кэширование предварительной обработки
Кэширование предварительной обработки было введено для повышения производительности предварительной обработки для нескольких зависимых элементов данных, имеющих схожие шаги предварительной обработки (что является распространённым результатом LLD).
Кэширование выполняется путём предварительной обработки одного зависимого элемента данных и повторного использования некоторых внутренних данных предварительной обработки для остальных зависимых элементов данных. Кэширование предварительной обработки поддерживается только для первого шага предварительной обработки следующих типов:
- шаблон Prometheus (индексирует входные данные по метрикам)
- JSONPath (разбирает данные в дерево объектов и индексирует первое выражение
[?(@.path == "значение")])
Рабочие процессы предварительной обработки
Файл конфигурации Zabbix сервера позволяет пользователям указать количество потоков рабочих процессов предварительной обработки («preprocessing worker»). Параметр конфигурации StartPreprocessors следует использовать, чтобы задать количество экземпляров рабочих процессов предварительной обработки, которое должно как минимум соответствовать количеству доступных ядер CPU.
Если задачи предварительной обработки не привязаны к CPU и включают частые сетевые запросы, рекомендуется настроить дополнительные рабочие процессы. Оптимальное количество рабочих процессов предварительной обработки может определяться многими факторами, включая количество «предобрабатываемых» элементов данных (элементов данных, требующих выполнения каких-либо шагов предварительной обработки), количество процессов сбора данных, среднее количество шагов для предварительной обработки элементов данных и так далее. Недостаточное количество рабочих процессов может привести к высокому потреблению памяти. Для устранения неполадок, связанных с чрезмерным использованием памяти в вашей инсталляции Zabbix, смотрите Профилирование чрезмерного использования памяти с помощью tcmalloc.
Но если предположить, что тяжелые операции предварительной обработки (вроде разбора больших кусков XML/JSON) отсутствуют, количество процессов «preprocessing worker» может совпадать с количеством сборщиков данных. Таким образом, в большинстве случаев для полученных данных будет по крайней мере один незанятый рабочий процесс предварительной обработки (за исключением случаев, когда данные от сборщиков поступают массово).
Слишком большое количество процессов сбора данных (поллеров, поллеров недоступных устройств, ODBC и HTTP поллеров, Java поллеров, пингеров, трапперов, прокси поллеров) вместе с менеджером IPMI, SNMP траппером и рабочими процессами предобработки могут исчерпать ограничение количества файловых дескрипторов на процесс для менеджера предварительной обработки.
Исчерпание лимита дескрипторов файлов на процесс приведёт к останову Zabbix сервера (обычно вскоре после запуска, но иногда это может занять более длительное время).
Чтобы избежать подобной ситуации, проанализируйте файл конфигурации Zabbix сервера, чтобы оптимизировать количество одновременных проверок и процессов.
Кроме того, при необходимости путём проверки и настройки системных ограничений убедитесь, что лимит дескрипторов файлов установлен достаточно высоким.
Поток обработки значения
Предварительная обработка значения элемента данных выполняется в несколько шагов (или фаз) несколькими процессами. Это может привести к тому, что:
- Зависимый элемент данных может получить значения, в то время как основной элемент данных — нет. Такое может произойти при следующем сценарии:
- У основного элемента данных тип значения
UINT(можно использовать элемент данных траппер), у зависимого элемента данных тип значенияTEXT. - Шаги предварительной обработки не требуются ни для основного, ни для зависимого элементов данных.
- Основному элементу данных необходимо передать текстовое значение (например, «abc»).
- Поскольку нет шагов предварительной обработки для выполнения, менеджер предварительной обработки проверяет, что основной элемент данных не находится в НЕПОДДЕРЖИВАЕМОМ состоянии и что имеется значение (оба условия выполняются), и помещает в очередь зависимый элемент данных с таким же значением, что и основной элемент данных (поскольку шаги предварительной обработки отсутствуют).
- Когда основной и зависимый элементы данных переходят в фазу синхронизации истории, основной элемент данных становится НЕПОДДЕРЖИВАЕМЫМ из-за ошибки конвертации значения (текстовые данные невозможно преобразовать в целое положительное число).
- У основного элемента данных тип значения
В результате зависимый элемент данных получает значение, тогда как основной элемент данных меняет свое состояние на НЕ ПОДДЕРЖИВАЕТСЯ.
- Зависимый элемент данных получает значение, которое отсутствует в истории основного элемента данных. Данный случай очень похож на предыдущий, за исключением типа основного элемента данных. Например, если у основного элемента данных используется тип
CHAR, то значение основного элемента данных будет усечено на стадии синхронизации истории, в то время как зависимые элементы данных получат свои значения с изначального (не усечённого) значения основного элемента данных.