
5 Eskalacje
Przegląd
Za pomocą eskalacji można tworzyć niestandardowe scenariusze wysyłania powiadomień lub wykonywania zdalnych poleceń.
W praktyce oznacza to, że:
- Użytkownicy mogą być natychmiast informowani o nowych problemach.
- Powiadomienia mogą być powtarzane do momentu rozwiązania problemu.
- Wysłanie powiadomienia może zostać opóźnione.
- Powiadomienia mogą być eskalowane do innej, „wyższej” grupy użytkowników.
- Zdalne polecenia mogą być wykonywane natychmiast lub wtedy, gdy problem nie zostanie rozwiązany przez dłuższy czas.
Akcje są eskalowane na podstawie kroku eskalacji. Każdy krok ma określony czas trwania.
Można zdefiniować zarówno domyślny czas trwania, jak i niestandardowy czas trwania poszczególnego kroku. Minimalny czas trwania jednego kroku eskalacji wynosi 60 sekund.
Można uruchamiać akcje, takie jak wysyłanie powiadomień lub wykonywanie poleceń, od dowolnego kroku. Krok pierwszy służy do działań natychmiastowych. Jeśli chcesz opóźnić akcję, możesz przypisać ją do późniejszego kroku. Dla każdego kroku można zdefiniować kilka akcji.
Liczba kroków eskalacji nie jest ograniczona.
Eskalacje są definiowane podczas konfigurowania operacji. Eskalacje są obsługiwane tylko dla operacji problemowych, a nie dla odzyskiwania.
Różne aspekty zachowania eskalacji
Rozważmy, co dzieje się w różnych okolicznościach, jeśli działanie zawiera kilka kroków eskalacji.
| Situation | Behavior |
|---|---|
| The host in question goes into maintenance after the initial problem notification is sent | Depending on the Pause operations for suppressed problems setting in action configuration, all remaining escalation steps are executed either with a delay caused by the maintenance period or without delay. A maintenance period does not cancel operations. |
| The time period defined in the Time period action condition ends after the initial notification is sent | All remaining escalation steps are executed. The Time period condition cannot stop operations; it has effect with regard to when actions are started/not started, not operations. |
| A problem starts during maintenance and continues (is not resolved) after maintenance ends | Depending on the Pause operations for suppressed problems setting in action configuration, all escalation steps are executed either from the moment maintenance ends or immediately. |
| A problem starts during a no-data maintenance and continues (is not resolved) after maintenance ends | It must wait for the trigger to fire, before all escalation steps are executed. |
| Different escalations follow in close succession and overlap | The execution of each new escalation supersedes the previous escalation, but for at least one escalation step that is always executed on the previous escalation. This behavior is relevant in actions upon events that are created with EVERY problem evaluation of the trigger. |
| During an escalation in progress (like a message being sent), based on any type of event: - the action is disabled Based on trigger event: - the trigger is disabled - the host or item is disabled Based on internal event about triggers: - the trigger is disabled Based on internal event about items/low-level discovery rules: - the item is disabled - the host is disabled |
The message in progress is sent and then one more message on the escalation is sent. The follow-up message will have the cancellation text at the beginning of the message body (NOTE: Escalation canceled) naming the reason (for example, NOTE: Escalation canceled: action '<Action name>' disabled). This way the recipient is informed that the escalation is canceled and no more steps will be executed. This message is sent to all who received the notifications before. The reason of cancellation is also logged to the server log file (starting from Debug Level 3=Warning). Note that the Escalation canceled message is also sent if operations are finished, but recovery operations are configured and are not executed yet. |
| During an escalation in progress (like a message being sent) the action is deleted | No more messages are sent. The information is logged to the server log file (starting from Debug Level 3=Warning), for example: escalation canceled: action id:334 deleted |
Przykłady eskalacji
Przykład 1
Wysyłanie powtarzanego powiadomienia co 30 minut (łącznie 5 razy) do grupy „MySQL Administrators”. Aby to skonfigurować:
- Na karcie Operations ustaw Default operation step duration na „30m” (30 minut).
- Ustaw Steps eskalacji od „1” do „5”.
- Wybierz grupę „MySQL Administrators” jako odbiorców wiadomości.
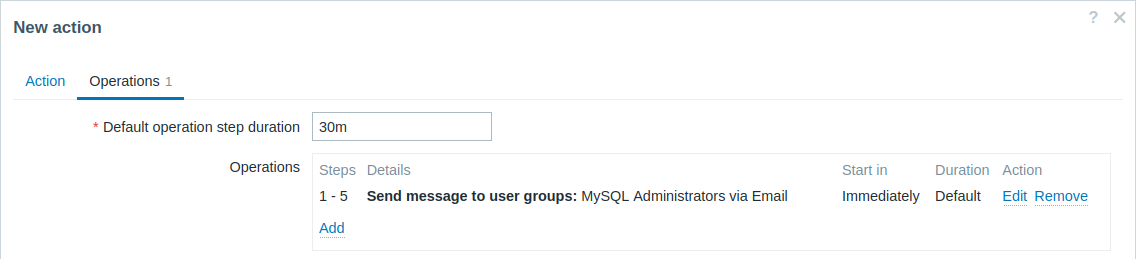
Powiadomienia będą wysyłane po 0:00, 0:30, 1:00, 1:30 i 2:00 godziny od wystąpienia problemu (chyba że problem zostanie oczywiście rozwiązany wcześniej).
Jeśli problem zostanie rozwiązany i skonfigurowano wiadomość o odzyskaniu, zostanie ona wysłana do tych, którzy otrzymali co najmniej jedną wiadomość o problemie w ramach tego scenariusza eskalacji.
Jeśli wyzwalacz, który wygenerował aktywną eskalację, zostanie wyłączony, Zabbix wyśle wszystkim osobom, które otrzymały już powiadomienia, wiadomość informacyjną na ten temat.
Przykład 2
Wysyłanie opóźnionego powiadomienia o długotrwałym problemie. Aby to skonfigurować:
- Na karcie Operations ustaw Default operation step duration na „10h” (10 godzin).
- Ustaw Steps eskalacji od „2” do „2”.
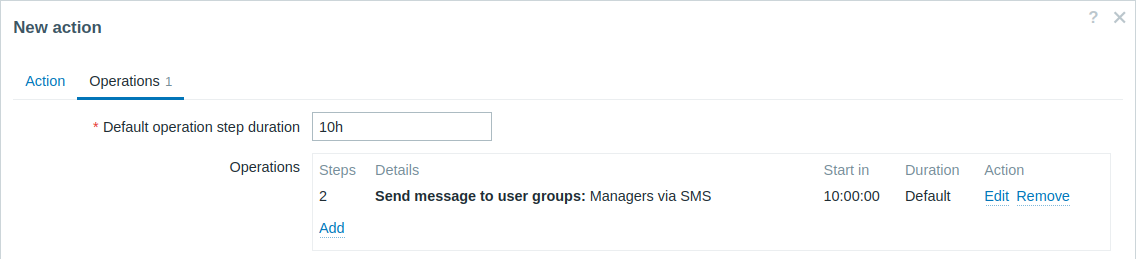
Powiadomienie zostanie wysłane dopiero w kroku 2 scenariusza eskalacji, czyli 10 godzin po wystąpieniu problemu.
Możesz dostosować treść wiadomości do czegoś w rodzaju „Problem trwa dłużej niż 10 godzin”.
Przykład 3
Eskalacja problemu do Szefa.
W pierwszym przykładzie powyżej skonfigurowaliśmy okresowe wysyłanie wiadomości do administratorów MySQL. W tym przypadku administratorzy otrzymają cztery wiadomości, zanim problem zostanie eskalowany do menedżera bazy danych. Należy pamiętać, że menedżer otrzyma wiadomość tylko wtedy, gdy problem nie został jeszcze potwierdzony, co oznacza, że prawdopodobnie nikt jeszcze nad nim nie pracuje.
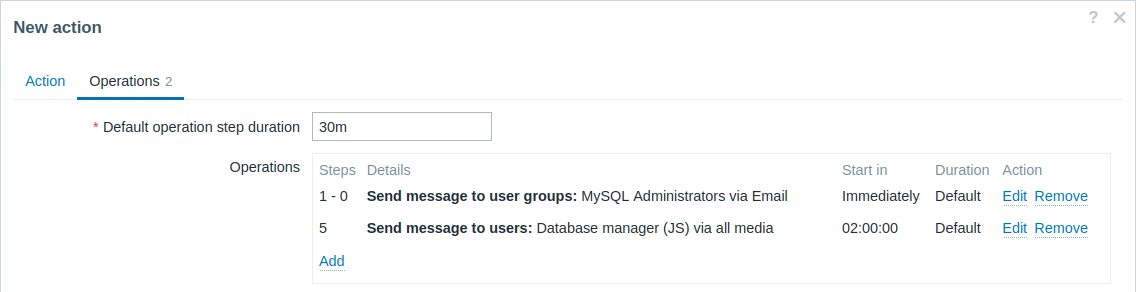
Szczegóły operacji 2:
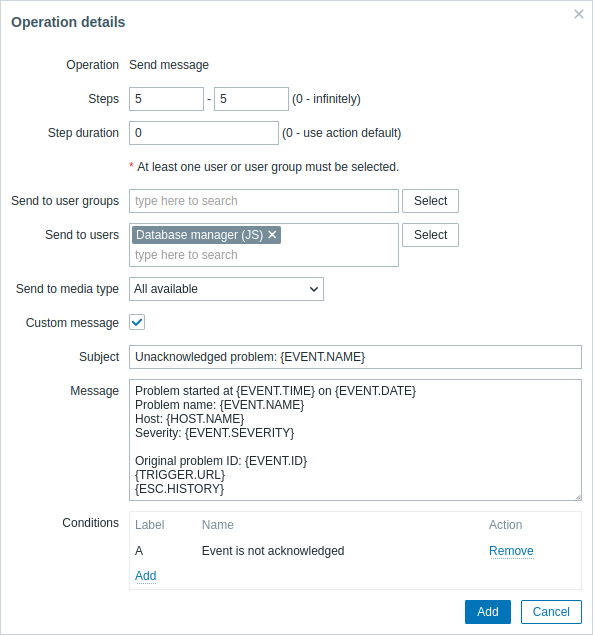
Zwróć uwagę na użycie makra {ESC.HISTORY} w dostosowanej wiadomości. Makro to będzie zawierać informacje o wszystkich wcześniej wykonanych krokach tej eskalacji, takich jak wysłane powiadomienia i wykonane polecenia.
Przykład 4
Bardziej złożony scenariusz. Po wysłaniu wielu wiadomości do administratorów MySQL i eskalacji do menedżera, Zabbix spróbuje ponownie uruchomić bazę danych MySQL. Stanie się to, jeśli problem będzie występował przez 2:30 godziny i nie zostanie potwierdzony.
Jeśli problem nadal będzie występował, po kolejnych 30 minutach Zabbix wyśle wiadomość do wszystkich użytkowników gościnnych.
Jeśli to nie pomoże, po kolejnej godzinie Zabbix zrestartuje serwer z bazą danych MySQL (drugie zdalne polecenie) przy użyciu poleceń IPMI.
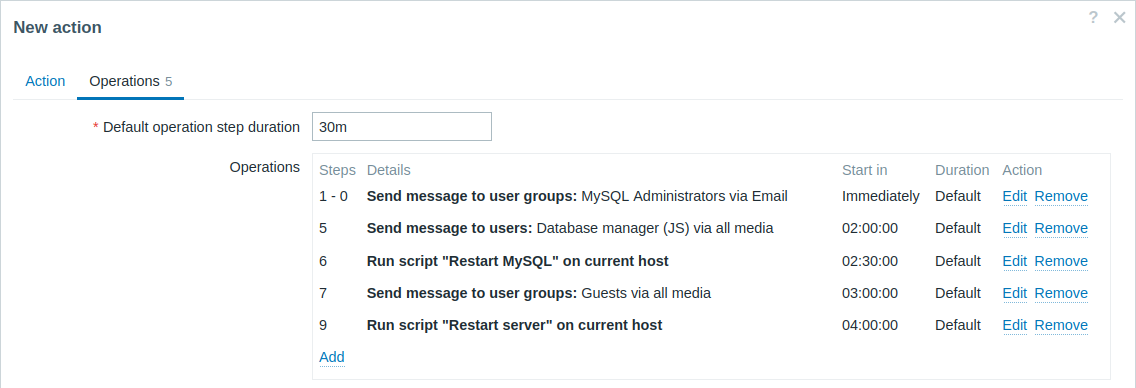
Przykład 5
Eskalacja z kilkoma operacjami, które mają nakładające się zakresy kroków i niestandardowe interwały. Domyślny czas trwania kroku operacji wynosi 30 minut.
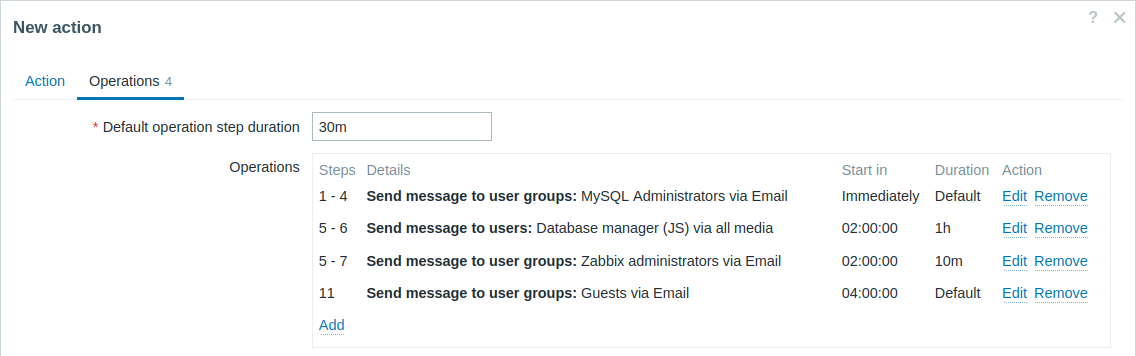
Powiadomienia będą wysyłane w następujący sposób:
- Do administratorów MySQL o 0:00, 0:30, 1:00 i 1:30 od momentu wystąpienia problemu.
- Do menedżera bazy danych o 2:00 i 2:10 (krótszy niestandardowy czas trwania kroku wynoszący 10 minut, zdefiniowany w kolejnej operacji, zastępuje dłuższy czas trwania kroku wynoszący 1 godzinę skonfigurowany tutaj, zgodnie z opisem w Szczegóły operacji dla Czas trwania kroku, gdy kroki nakładają się).
- Do administratorów Zabbix o 2:00, 2:10 i 2:20 od momentu wystąpienia problemu (zastosowany jest niestandardowy czas trwania kroku wynoszący 10 minut).
- Do użytkowników guest o 4:00 od momentu wystąpienia problemu (domyślny czas trwania kroku wynoszący 30 minut obowiązuje między krokami 8 i 11).