
2 Detalhes de pré-processamento
Visão geral
Esta seção fornece detalhes de pré-processamento de valor de item. O pré-processamento de valor de item permite definir e executar regras de transformação para os valores de item recebidos.
O pré-processamento é gerenciado por um processo gerenciador de pré-processamento, o qual foi adicionado no Zabbix 3.4, junto com operadores de pré-processamento que executam as etapas de pré-processamento. Todos os valores (com ou sem pré-processamento) de diferentes coletores de dados passam através dos gerenciadores de pré-processamento antes de serem adicionados ao cache histórico. Comunicação IPC baseada em socket é usada entre os coletores de dados (pollers, trappers, etc.) e o processo de pré-processamento. Ou o Zabbix Server ou o Zabbix Proxy (para itens monitorados pelo proxy) está executando etapas de pré-processamento.
Processamento de valor de item
Para visualizar o fluxo de dados de sua origem para o banco de dados do Zabbix, nós podemos usar o seguinte diagrama simplificado:
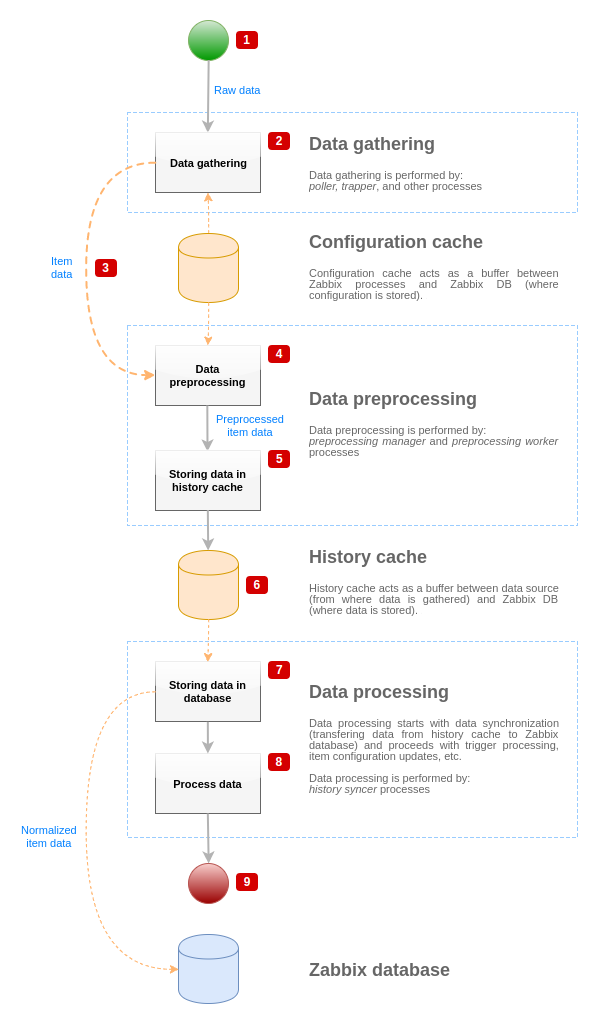
O diagrama acima mostra apenas processos, objetos e ações relacionadas ao processamento do valor do item em uma forma simplificada. O diagrama não mostra mudanças de direção condicionais, manipulação de erros ou loops. O cache de dados local do gerenciador de pré-processamento também não é mostrado devido não afetar o fluxo de dados diretamente. O objetivo deste diagrama é mostrar os processos envolvidos no processamento de valor do item e o modo como eles interagem.
- A coleta de dados começa com dados brutos de uma fonte de dados. Neste ponto, os dados contêm apenas ID, registro de data (timestamp) e valor (também pode ser múltiplos valores)
- Não importa qual o tipo de coletor de dados é usado, a ideia é a mesma para verificações ativas ou passivas, para itens trapper e etc., pois ele apenas altera o formato do dado e o iniciador de comunicação (ou o coletor de dados está aguardando por uma conexão e dados, ou o coletor de dados inicia a comunicação e requisita os dados). O dado bruto é validado, a configuração do item é recuperada do cache de configuração (o dado é enriquecido com os dados de configuração).
- O mecanismo IPC baseado em socket é usado para passar dados dos coletores de dados ao gerenciador de pré-processamento. Neste ponto o coletor de dados continua a coletar dados sem aguardar pela resposta do gerenciador de pré-processamento.
- O pré-processamento é executado. Isto inclui a execução das etapas de pré-processamento e processamento de itens dependentes.
O item pode alterar seu estado para NÃO SUPORTADO enquanto o pré-processamento é executado se quaisquer etapas do pré-processamento falhar.
- O dado histórico do cache de dados local do gerenciador de pré-processamento está sendo liberado para dentro do cache histórico.
- Neste ponto o fluxo de dados para até a próxima sincronização do cache histórico (quando o processo sincronizador de histórico executa sincronização de dados).
- O processo de sincronização inicia com normalização de dados armazenando dado no banco de dados do Zabbix. A normalização de dados executa conversões para o tipo de item desejado (tipo definido na configuração do item), incluindo a truncagem de dado textual baseado nos tamanhos pré-definidos permitidos para tais tipos (HISTORY_STR_VALUE_LEN para string, HISTORY_TEXT_VALUE_LEN para texto e HISTORY_LOG_VALUE_LEN para valores de log). O dado está sendo enviado para o banco de dados do Zabbix após a normalização ser efetuada.
O item pode alterar seu estado para NÃO SUPORTADO se a normalização de dados falhar (por exemplo, quando um valor textual não pode ser convertido para número).
- O dado coletado está sendo processado - gatilhos são verificados, a configuração do item é atualizada se o item se torna NÃO SUPORTADO, etc.
- Isto é considerado o fim do fluxo de dados do ponto de vista do processamento do valor do item.
Pré-processamento de valor do item
Para visualizar o processo de pré-processamento de dados, nós podemos usar o seguinte diagrama simplificado:
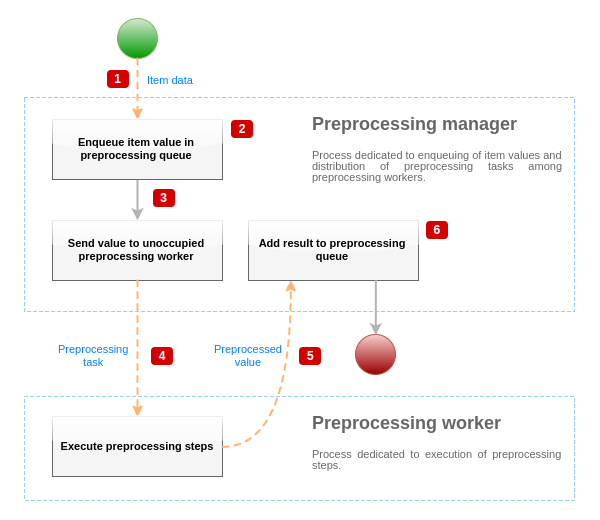
O diagrama acima mostra somente processos, objetos e ações principais relacionadas ao pré-processamento do valor do item em uma forma simplificada. O diagrama não mostra alterações de direção condicionais, manipulação de erro ou loops. Apenas um operador de pré-processamento é mostrado neste diagrama (múltiplos operadores de pré-processamento podem ser usados em cenários da vida real), apenas um valor de item está sendo processado e nós assumimos que este item requer a execução de ao menos uma etapa de pré-processamento. O objetivo deste diagrama é mostrar a ideia por detrás da diretiva de pré-processamento do valor do item.
- O dado e valor do item é passado para o gerenciador de pré-processamento usando o mecanismo IPC baseado em socket.
- O item é colocado na fila de pré-processamento.
O item pode ser colocado no fim ou no início da fila de pré-processamento. Os itens internos do Zabbix são sempre colocados no início da fila de pré-processamento, enquanto outros tipos de itens são enfileirados no fim.
- Neste ponto o fluxo de dados para até que haja ao menos um operador de pré-processamento desocupado (que não esteja executando nenhuma tarefa).
- Quando um operador de pré-processamento está disponível, a tarefa de pré-processamento é enviada para ele.
- Após o pré-processamento ser executado (ambas execuções com falha ou bem-sucedida de etapas de pré-processamento), o valor pré-processado é passado de volta para o gerenciador de pré-processamento.
- O gerenciador de pré-processamento converte o resultado para o formato desejado (definido pelo tipo de valor do item) e coloca o resultado na fila de pré-processamento. Se houver itens dependentes para o item atual, então os itens dependentes são adicionados à fila de pré-processamento também. Itens dependentes são enfileirados na fila de pré-processamento logo após o item principal, mas apenas para itens principais com valor definido e não no estado NÃO SUPORTADO.
Diretiva de processamento de valor
O processamento de valor de item é executado em múltiplas etapas (ou fases) por múltiplos processos. Isto pode causar:
- Item dependente pode receber valores, enquanto O valor principal não.
Isto pode ser alcançado pelo uso do seguinte caso de uso:
- Item principal tem tipo de valor
UINT, (item trapper pode ser usado), item dependente tem tipo de valorTEXT. - Nenhuma etapa de pré-processamento é requerida para ambos os itens principal e dependente.
- Valor textual (como, "abc") deve ser passado para o item principal.
- Como não há etapas de pré-processamento para executar, o gerenciador de pré-processamento verifica se o item principal não está no estado NÃO SUPORTADO e se o valor não está definido (ambos são verdadeiro) e enfileira o item dependente com o mesmo valor do item principal (como não há etapas de pré-processamento).
- Quando ambos os itens principal e dependente alcançam a fase de sincronização de histórico, o item principal se torna NÃO SUPORTADO, por causa de erro de conversão de valor (dado textual não pode ser convertido para inteiro - unsigned).
- Item principal tem tipo de valor
Como resultado, o item dependente recebe um valor, enquanto o item principal altera seu estado para NÃO SUPORTADO.
- O item dependente recebe um valor que não está presente no histórico do item
principal. O caso de uso é muito similar ao anterior, exceto pelo tipo de
item principal. Por exemplo, se o tipo
CHARé usado para o item principal, então o valor do item principal será truncado na fase de sincronização do histórico, enquanto os itens dependentes receberão seu valor do valor inicial (não truncado) do item principal.
Fila de pré-processamento
A fila de pré-processamento é uma estrutura de dados FIFO (primeiro a entrar é o primeiro a sair) que armazena valores preservando a ordem na qual os valores são recebidos pelo gerenciador de pré-processamento. Há múltiplas exceções à lógica FIFO:
- Itens internos são enfileirados no início da fila
- Itens dependentes são sempre enfileirados após os item principal
Para visualizar a lógica da fila de pré-processamento, nós podemos usar o seguinte diagrama:
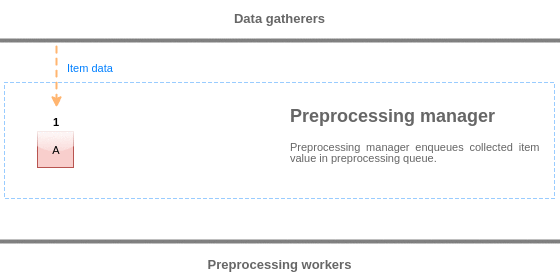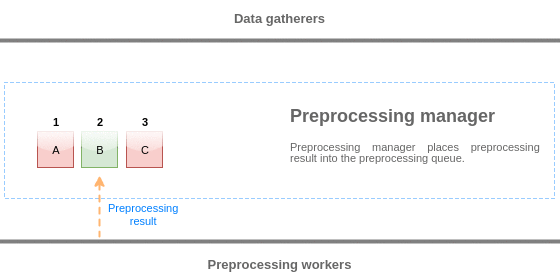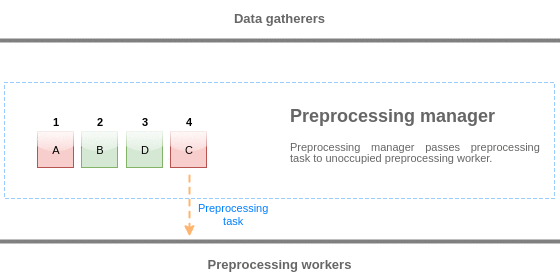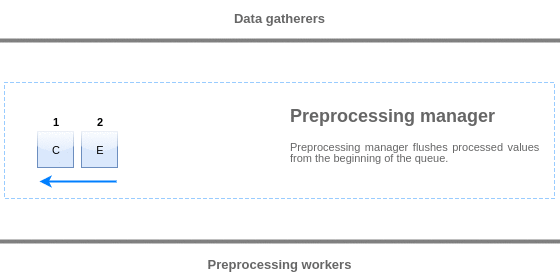
Valores da fila de pré-processamento são liberados do início da fila para o primeiro valor não processado. Então, por exemplo, o gerenciador de pré-processamento liberará os valores 1, 2 e 3, mas não liberará o valor 5 pois o valor 4 ainda não foi processado:

Apenas dois valores serão deixados na fila (4 e 5) após a liberação, os valores são adicionados ao cache de dados local do gerenciador de pré-processamento e então os valores são transferidos do cache local para dentro do cache histórico. O gerenciador de pré-processamento pode liberar valores do cache de dados local no modo de item único ou no modo volume (usado para itens dependentes e valores recebidos em volume (bulk)).
Operadores de pré-processamento
O arquivo de configuração do Zabbix Server permite aos usuários definir o número de processos de operador de pré-processamento. O parâmetro de configuração StartPreprocessors deve ser usado para definir o número de instâncias paralelas (pre-forked) de operadores de pré-processamento. O número ideal de operadores de pré-processamento pode ser determinado por vários fatores, incluindo o número de itens "pré-processáveis" (itens que requerem a execução de quaisquer etapas de pré-processamento), número de processos de coleta de dados, média do número de etapas de pré-processamento para item, etc.
Mas assumindo que não há operações de pré-processamento pesadas como análise de grandes conjuntos XML / JSON, o número de operadores de pré-processamento pode corresponder ao número de coletores de dados. Deste modo, haverá na maioria das vezes (exceto para os casos quando os dados do coletor vierem em volume) ao menos um operador de pré-processamento desocupado para os dados coletados.
O excesso de processos de coleta de dados (pollers, pollers inalcançáveis, pollers ODBC, pollers HTTP, pollers Java, operadores de ping, trappers, pollers de proxy) junto com gerenciador IPMI, trapper SNMP e operadores de pré-processamento podem exaurir o limite de descritores de arquivo por processo para o gerenciador de pré-processamento. Isto causará a parada do Zabbix server (usualmente logo após o início, mas algumas vezes isto pode levar um pouco mais de tempo). O arquivo de configuração deve ser revisado ou o limite deve ser elevado para evitar esta situação.