
Detalhes de pré-processamento
Visão geral
Esta seção fornece detalhes sobre o pré-processamento de valores de item. O pré-processamento de valores de item permite definir e executar regras de transformação para os valores de item recebidos.
O pré-processamento é gerenciado pelo processo de gerenciador de pré-processamento juntamente com os workers de pré-processamento que executam as etapas de pré-processamento. Todos os valores com pré-processamento, recebidos de diferentes coletores de dados, passam pelo gerenciador de pré-processamento antes de serem adicionados ao cache de histórico. A comunicação IPC baseada em socket é usada entre os coletores de dados (pollers, trappers, etc.) e o processo de pré-processamento. O pré-processamento é realizado pelo Zabbix server ou pelo Zabbix proxy (para os itens monitorados pelo proxy).
Processamento do valor do item
Para visualizar o fluxo de dados desde a fonte de dados até o banco de dados do Zabbix, podemos usar o seguinte diagrama simplificado:
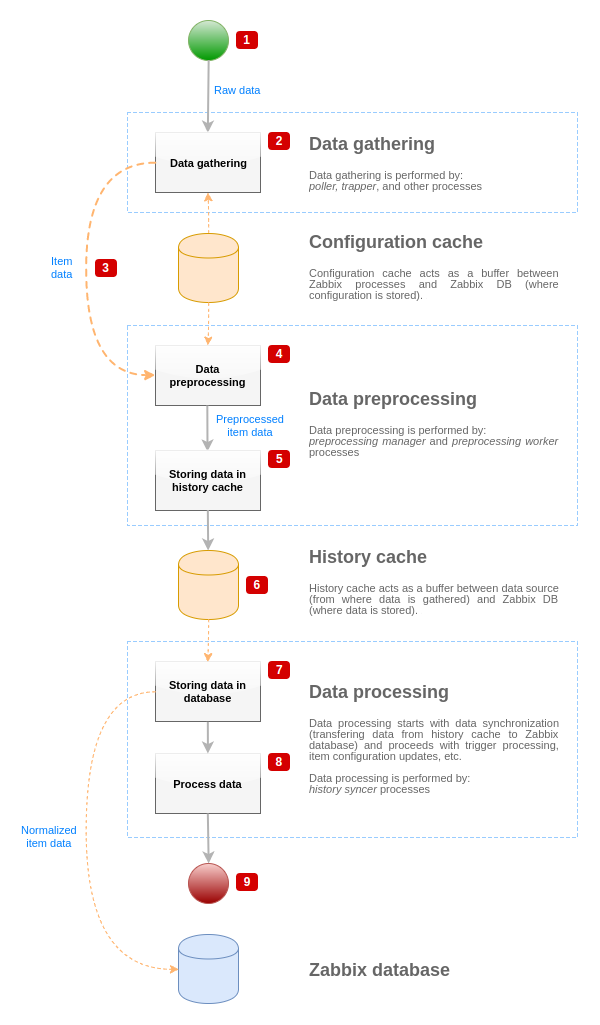
O diagrama acima mostra apenas processos, objetos e ações relacionadas ao processamento do valor do item de forma simplificada. O diagrama não mostra mudanças condicionais de direção, tratamento de erros ou loops. O cache de dados local do gerenciador de pré-processamento também não é mostrado porque não afeta o fluxo de dados diretamente. O objetivo deste diagrama é mostrar os processos envolvidos no processamento do valor do item e a forma como eles interagem.
- A coleta de dados começa com dados brutos de uma fonte de dados. Neste ponto, os dados contêm apenas ID, timestamp e valor (podem ser múltiplos valores também).
- Não importa qual tipo de coletor de dados é usado, a ideia é a mesma para checagens ativas ou passivas, para items trapper, etc., pois isso apenas muda o formato dos dados e o iniciador da comunicação (ou o coletor de dados está esperando por uma conexão e dados, ou o coletor de dados inicia a comunicação e solicita os dados). Os dados brutos são validados, a configuração do item é recuperada do cache de configuração (os dados são enriquecidos com os dados de configuração).
- Um mecanismo IPC baseado em socket é usado para passar dados dos coletores de dados para o gerenciador de pré-processamento. Neste ponto, o coletor de dados continua a coletar dados sem esperar pela resposta do gerenciador de pré-processamento.
- O pré-processamento dos dados é realizado. Isso inclui a execução das etapas de pré-processamento e o processamento de items dependentes.
Um item pode mudar seu estado para NÃO SUPORTADO enquanto o pré-processamento é realizado se qualquer uma das etapas de pré-processamento falhar.
- Os dados de histórico do cache de dados local do gerenciador de pré-processamento estão sendo gravados no cache de histórico.
- Neste ponto, o fluxo de dados para até a próxima sincronização do cache de histórico (quando o processo de sincronização de histórico realiza a sincronização dos dados).
- O processo de sincronização começa com a normalização dos dados antes de armazená-los no banco de dados do Zabbix. A normalização dos dados realiza conversões para o tipo de item desejado (tipo definido na configuração do item), incluindo o truncamento de dados textuais com base nos tamanhos predefinidos permitidos para esses tipos (HISTORY_STR_VALUE_LEN para string, HISTORY_TEXT_VALUE_LEN para texto e HISTORY_LOG_VALUE_LEN para valores de log). Os dados são enviados para o banco de dados do Zabbix após a normalização ser concluída.
Um item pode mudar seu estado para NÃO SUPORTADO se a normalização dos dados falhar (por exemplo, quando um valor textual não pode ser convertido para número).
- Os dados coletados estão sendo processados - triggers são verificadas, a configuração do item é atualizada se o item se tornar NÃO SUPORTADO, etc.
- Isso é considerado o fim do fluxo de dados do ponto de vista do processamento do valor do item.
Pré-processamento de valor de item
O pré-processamento de dados é realizado nas seguintes etapas:
- Se o item não possui pré-processamento nem itens dependentes, seu valor é adicionado ao cache de histórico ou enviado ao gerenciador de LLD. Caso contrário, o valor do item é passado para o gerenciador de pré-processamento usando um mecanismo IPC baseado em socket UNIX.
- Uma tarefa de pré-processamento é criada e adicionada à fila e os workers de pré-processamento são notificados sobre a nova tarefa.
- Neste ponto, o fluxo de dados é interrompido até que haja pelo menos um worker de pré-processamento desocupado (ou seja, que não esteja executando nenhuma tarefa).
- Quando um worker de pré-processamento está disponível, ele pega a próxima tarefa da fila.
- Após a conclusão do pré-processamento (tanto em caso de falha quanto de execução bem-sucedida das etapas de pré-processamento), o valor pré-processado é adicionado à fila de tarefas concluídas e o gerenciador é notificado sobre uma nova tarefa concluída.
- O gerenciador de pré-processamento converte o resultado para o formato desejado (definido pelo tipo de valor do item) e o adiciona ao cache de histórico ou o envia ao gerenciador de LLD.
- Se houver itens dependentes para o item processado, os itens dependentes são adicionados à fila de pré-processamento com o valor do item mestre pré-processado. Os itens dependentes são enfileirados ignorando as solicitações normais de pré-processamento de valor, mas apenas para itens mestres com o valor definido e que não estejam em estado NÃO SUPORTADO.

Observe que, no diagrama, o pré-processamento do item mestre é ligeiramente simplificado ao ignorar o cache de pré-processamento.
Fila de pré-processamento
A fila de pré-processamento é organizada como:
-
a lista de tarefas pendentes:
- tarefas criadas diretamente a partir de solicitações de pré-processamento de valores na ordem em que foram recebidas
-
a lista de tarefas imediatas (processadas antes das tarefas pendentes):
- tarefas de teste (criadas em resposta a solicitações de teste de item/pré-processamento pelo frontend)
- tarefas de item dependente
- tarefas de sequência (tarefas que devem ser executadas em uma ordem estrita):
- tendo etapas de pré-processamento usando o último valor:
- change
- throttling
- JavaScript (cache de bytecode)
- cache de pré-processamento de item dependente
- tendo etapas de pré-processamento usando o último valor:
-
a lista de tarefas finalizadas
Cache de pré-processamento
O cache de pré-processamento foi introduzido para melhorar o desempenho do pré-processamento para múltiplos items dependentes que possuem etapas de pré-processamento semelhantes (o que é um resultado comum do LLD).
O cache é feito pré-processando um item dependente e reutilizando alguns dos dados internos de pré-processamento para o restante dos items dependentes. O cache de pré-processamento é suportado apenas para a primeira etapa de pré-processamento dos seguintes tipos:
- Padrão Prometheus (indexa a entrada por métricas)
- JSONPath (analisa os dados em uma árvore de objetos e indexa a primeira expressão
[?(@.path == "value")])
Workers de pré-processamento
O arquivo de configuração do Zabbix server permite que os usuários definam a quantidade de threads de worker de pré-processamento. O parâmetro de configuração StartPreprocessors deve ser usado para definir o número de instâncias de workers de pré-processamento pré-iniciadas, que deve ser pelo menos igual ao número de núcleos de CPU disponíveis.
Se as tarefas de pré-processamento não forem limitadas pela CPU e envolverem solicitações frequentes de rede, é recomendável configurar workers adicionais. O número ideal de workers de pré-processamento pode ser determinado por muitos fatores, incluindo a quantidade de items "pré-processáveis" (items que exigem a execução de qualquer etapa de pré-processamento), a quantidade de processos de coleta de dados, a média de etapas de pré-processamento por item etc. A quantidade insuficiente de workers pode levar a alto uso de memória. Para solucionar problemas de uso excessivo de memória na sua instalação do Zabbix, consulte Profiling excessive memory usage with tcmalloc.
Mas, assumindo que não haja operações pesadas de pré-processamento, como a análise de grandes blocos XML/JSON, o número de workers de pré-processamento pode corresponder ao número total de coletores de dados. Dessa forma, na maior parte do tempo (exceto nos casos em que os dados do coletor chegam em lote), haverá pelo menos um worker de pré-processamento desocupado para os dados coletados.
Processos demais de coleta de dados (pollers, unreachable pollers, ODBC pollers, HTTP pollers, Java pollers, pingers, trappers, proxypollers), juntamente com o IPMI manager, SNMP trapper e workers de pré-processamento, podem esgotar o limite de descritores de arquivo por processo para o preprocessing manager.
Esgotar o limite de descritores de arquivo por processo fará com que o Zabbix server pare, normalmente logo após a inicialização, mas às vezes levando mais tempo.
Para evitar esses problemas, revise o arquivo de configuração do Zabbix server para otimizar o número de verificações e processos simultâneos.
Além disso, se necessário, certifique-se de que o limite de descritores de arquivo esteja definido em um valor suficientemente alto, verificando e ajustando os limites do sistema.
Pipeline de processamento de valor
O processamento do valor do item é executado em várias etapas (ou fases) por vários processos. Isso pode causar:
- Um item dependente pode receber valores, enquanto o valor mestre não pode.
Isso pode ser alcançado usando o seguinte caso de uso:
- O item mestre tem o tipo de valor
UINT(um item trapper pode ser usado), o item dependente tem o tipo de valorTEXT. - Nenhuma etapa de pré-processamento é necessária para os itens mestre e dependente.
- Um valor textual (por exemplo, "abc") deve ser passado para o item mestre.
- Como não há etapas de pré-processamento a serem executadas, o gerenciador de pré-processamento verifica se o item mestre não está no estado NÃO SUPORTADO e se o valor está definido (ambos são verdadeiros) e coloca o item dependente na fila com o mesmo valor do item mestre (já que não há etapas de pré-processamento).
- Quando ambos os itens, mestre e dependente, atingem a fase de sincronização do histórico, o item mestre se torna NÃO SUPORTADO devido ao erro de conversão de valor (dados textuais não podem ser convertidos em inteiro sem sinal).
- O item mestre tem o tipo de valor
Como resultado, o item dependente recebe um valor, enquanto o item mestre muda seu estado para NÃO SUPORTADO.
- Um item dependente recebe um valor que não está presente no histórico do item mestre. O caso de uso é muito semelhante ao anterior, exceto pelo tipo do item mestre. Por exemplo, se o tipo
CHARfor usado para o item mestre, então o valor do item mestre será truncado na fase de sincronização do histórico, enquanto os itens dependentes receberão seus valores a partir do valor inicial (não truncado) do item mestre.