
2 保存前処理の詳細
概要
ここでは、item 値のプリプロセッシングについて説明します。item 値のプリプロセッシングでは、
受け取ったitem 値に対してtransformation rulesを定義し、実行することができます。
プリプロセスは、Zabbix3.4で追加されたプリプロセスマネージャプロセスとプリプロセスワーカーによって管理され、
プリプロセスのステップを実行することができます。
プリプロセスのステップは、異なるデータ収集元からのすべての値(プリプロセスあり/なし)が、
ヒストリーキャッシュに追加される前に、プリプロセッシングマネージャを通過します。
データ収集装置(ポーラ、トラッパーなど)とプリプロセスの間で、ソケットベースのIPC通信が使用されます。
Zabbix server またはZabbix proxy(proxy が監視する item の場合)のどちらかがプリプロセスを実行します。
item 値の処理
データソースからZabbixデータベースへのデータフローを可視化するために、以下の簡略化された図を使用します。
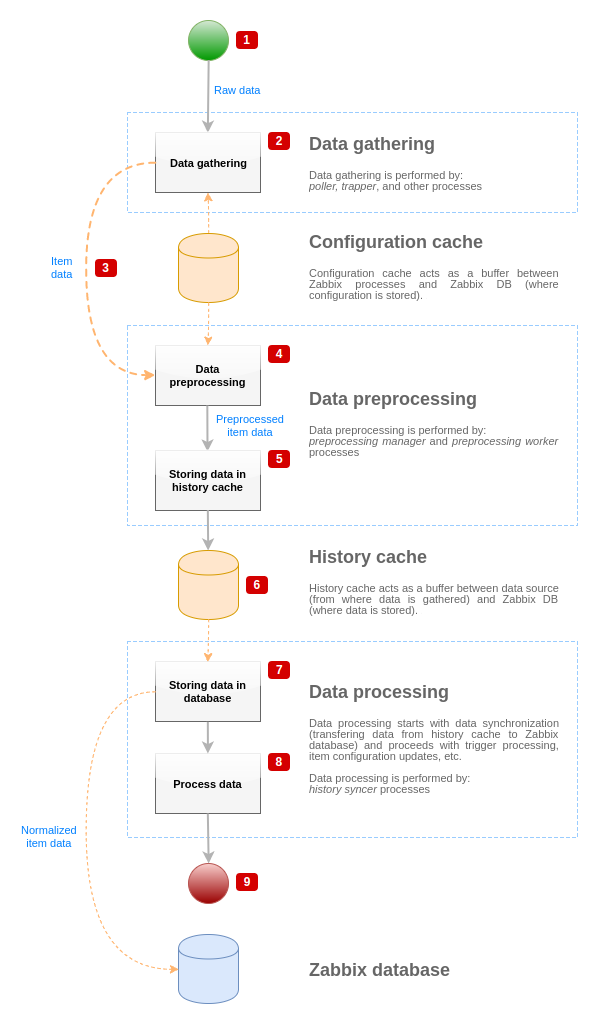
上の図は、item 値処理に関連するプロセス、オブジェクト、アクションのみを簡略化して示しています。
この図には条件分岐、エラー処理、ループなどは示していません。プリプロセスマネージャの
ローカルデータキャッシュも表示されていません。データフローに直接影響しないためです。
この図の目的は、item 値処理に関わるプロセスと、それらが相互作用する方法を示すことです。<
- データ収集は、データソースからの生データから始まる。このデータにはID、タイムスタンプ、値(複数の値も可能)のみが含まれます。
- アクティブチェック、パッシブチェック、トラッパー item など、どのような種類のデータ収集装置を使っても、
考え方は同じで、データ形式と通信の開始方法を変えるだけです。
(データ収集者が接続とデータを待っているか、データ収集者が通信を開始し、データを要求しているか)
生データは検証され、item 設定は設定キャッシュから取得されます。(データは設定データでリッチ化されます)。 - データ収集者からプリプロセスマネージャへのデータの受け渡しには、ソケットベースのIPCメカニズムが使用されます。
この時点でデータ収集装置はプリプロセスマネージャからの応答を待たずにデータ収集を続ける。 - データのプリプロセッシングが行われる。これには、プリプロセスステップの実行と依存項目処理が含まれます。
item はプリプロセッシングが行われている間にいずれかの処理が失敗した場合、状態が NOT SUPPORTED に変更されることがあります。
- プリプロセスマネージャのローカルデータキャッシュからヒストリデータがヒストリーキャッシュに流される。
- この時点でデータの流れは止まり、次のヒストリーキャッシュの同期(ヒストリーシンサープロセスがデータの同期を行う)まで
データの流れは停止します。 - 同期処理はデータの正規化から始まり、データをZabbixデータベースに格納することから始まります。
データの正規化では、以下の変換を行います。
目的の item タイプ(item 設定で定義されたタイプ)への変換を行います。
テキストデータについては、あらかじめ定義されたサイズに基づき、切り捨てを行います。
テキストデータは、それらのタイプに許容される事前定義されたサイズ(文字列はHISTORY_STR_VALUE_LEN、
テキストはHISTORY_TEXT_LEN、ログ値にはHISTORY_LOG_VALUE_LEN)に基づいて切り捨てられます。
データは正規化された後、Zabbixデータベースに送信されます。
データの正規化に失敗した場合(例:テキスト値を数値に変換できない場合)、item はNOT SUPPORTEDに状態を変更されることがあります。
- 収集されたデータは処理される - トリガーがチェックされ、item が NOT SUPPORTED になった場合は設定が更新される
- item 値処理の観点からは、これでデータフローは終了したとみなされる。
item 値のプリプロセッシング
データのプリプロセッシングを可視化するために、以下のような簡略化した図を示します。
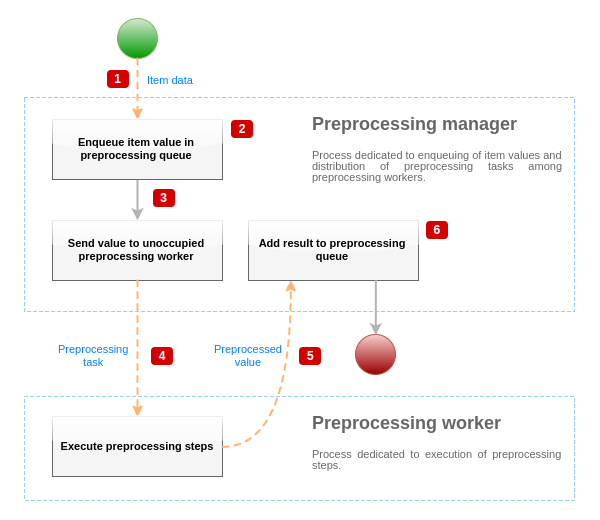
上の図は、item 値のプリプロセッシングに関連するプロセス、オブジェクト、および主なアクションのみを 簡略化 した形で示しています。
この図では条件分岐、エラー処理、ループは示していない。ただ1つのプリプロセスワーカーだけが示されています。
(実際は複数のプリプロセスワーカーを使用することも可能です)
この項目は少なくとも1つのプリプロセス工程を実行する必要があると想定している。
この図の目的は、item 値のプリプロセスパイプラインの考え方を示すことである。
- item データとitem 値は、ソケットベースのIPCメカニズムを使用してプリプロセスマネージャに渡される。
- item はプリプロセスキューに入れられる。
item はプリプロセスキューの最後または先頭に配置されます。
Zabbix内部アイテムは常にプリプロセスキューの先頭に配置され、その他のアイテムタイプは最後にキューイングされます。
- この時点で、少なくとも1つの未使用の(タスクを実行していない)プリプロセスワーカーが存在するまでデータフローは停止します。
- プリプロセスワーカーが利用可能になると、プリプロセスタスクはそのワーカーに送られます。
- プリプロセスが完了すると(プリプロセスステップの実行に失敗した場合も成功した場合も)処理された値が
プリプロセッシングマネージャに戻されます。 - プリプロセスマネージャは、結果を(item 値の型によって定義される)希望する形式に変換し、結果をプリプロセスキューに入れる。
もし現在の item に依存する item がある場合、依存する item もプリプロセスキューに追加されます。
ただし、値が設定され、NOT SUPPORTED 状態でないマスター item に限ります。
値処理のパイプライン
item 値処理は、複数のプロセスによって、複数のステップ(またはフェーズ)で実行されます。
これが要因となって、
- 従属 item は値を受け取ることができるが、親 item は値を受け取ることができない。
これは、次のユースケースを使用することで実現できます。
- 親 item は値型が
UINT(トラッパー項目も使用できる)、従属項目は値型TEXTを持つ。 - 親 item 、従属 item ともに前処理は必要ありません。
- テキスト値 (例えば "abc") は親 item に渡す必要があります。
- 実行するプリプロセスステップがないので、プリプロセスマネージャーは、
親 item が NOT SUPPORTED 状態でないかどうか、 値が設定されているかどうかを確認し (両方とも真) 、
親 item と同じ値を持つ従属アイテムを待ちます。 - 親 item と従属アイテムの両方が履歴同期フェーズに到達すると、親 item は NOT SUPPORTED になります。
なぜなら、値の変換エラー (テキストデータは符号なし整数に変換できない) が発生するからです。
- 親 item は値型が
その結果、従属 item は値を受け取り、親 item の状態が NOT SUPPORTED に変わります。
- 従属 item は 親 item の履歴に存在しない値を受け取ります。
このユースケースは、以下の点を除き、親 item の種類を除いて、前のものと非常によく似ています。
たとえば、CHAR型が親 item に使用されている場合、親 item の値は
親 item の値は履歴の同期段階で切り捨てられます。
従属 item の値は親 item の初期値 (切り捨てられない) から取得します。
プリプロセスキュー
プリプロセスキューは、プリプロセスマネージャーによって値がレビューされる順序を維持したまま値を格納するFIFOデータ構造です。FIFOロジックにはいくつかの例外があります:
- 内部アイテムはキューの先頭にエンキューされます
- 依存アイテムは常に親アイテムの後にエンキューされます
プリプロセスキューのロジックを視覚化するために、次の図を使用します。
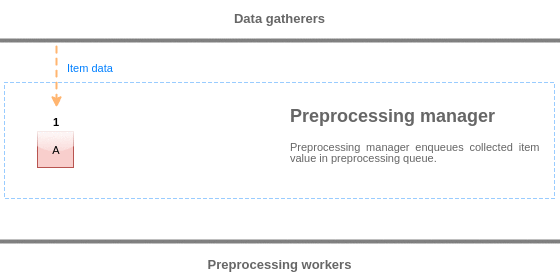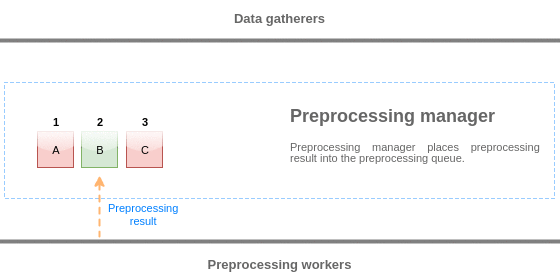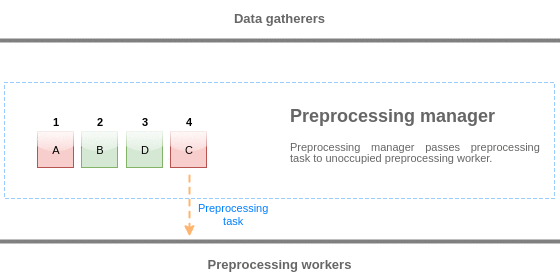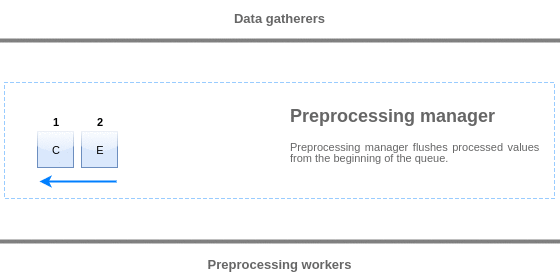
プリプロセスキューからの値は、キューの先頭から最初の未処理キューにフラッシュされます。
したがって、例えば、プリプロセスマネージャは、値1、2、3 をフラッシュしますが、値4 はまだ処理されていないため、
値5 はフラッシュしません。

フラッシュ後、キューには2つの値(4と5)だけが残され、プリプロセッシングマネージャのローカルデータキャッシュに追加され、
その後、値がローカルキャッシュからヒストリーキャッシュに転送されます。
プリプロセッシングマネージャは、ローカルデータキャッシュから、単一 item モードまたはバルクモード
(依存する item や一括して受け取った値に使用)で値をフラッシュすることができます。
プリプロセスワーカー
Zabbixサーバ設定ファイルでは、プリプロセスワーカープロセスの数を設定することができます。
StartPreprocessors 設定パラメータを使用して、フォークされたプリプロセスワーカーインスタンスの数を設定する必要があります。
最適なプリプロセスワーカーの数は、"プリプロセッシング可能な"アイテムの数など、多くの要因によって決まります。
データ収集プロセスの数、item の前処理にかかる平均ステップ数などです。
しかし、大きなXML/JSONチャンクのパースなどの重いプリプロセスがないと仮定すると、
プリプロセスワーカーの数はデータ収集プロセスの総数と一致させることができます。この方法では、ほとんどの場合
(ギャザラーからのデータが大量に来る場合を除く)、少なくとも1つの空いたプリプロセスワーカーが存在することになります。
データ収集プロセスが多すぎる (ポーラ、到達不能ポーラ、ODBC ポーラ、HTTP ポーラ、Java ポーラ、pingers、trappers,
プロキシポーラ) ケースで、IPMI マネージャ、SNMP トラッパ、プリプロセスワーカーを一緒に使用すると、
プリプロセスマネージャのプロセスごとのファイルディスクリプタを使い果たす可能性があります。
この場合、Zabbixサーバは停止します。(通常は起動後すぐに停止しますが、もっと時間がかかる場合もあります)
この状況を回避するために、設定ファイルを修正するか、制限値を上げる必要があります。