
Szczegóły przetwarzania wstępnego
Przegląd
Ta sekcja zawiera szczegółowe informacje o wstępnym przetwarzaniu wartości pozycji. Wstępne przetwarzanie wartości pozycji pozwala definiować i wykonywać reguły transformacji dla otrzymanych wartości pozycji.
Wstępne przetwarzanie jest zarządzane przez proces menedżera wstępnego przetwarzania wraz z workerami wstępnego przetwarzania, które wykonują kroki wstępnego przetwarzania. Wszystkie wartości ze wstępnym przetwarzaniem, otrzymane od różnych modułów zbierania danych, przechodzą przez menedżera wstępnego przetwarzania, zanim zostaną dodane do pamięci podręcznej historii. Używana jest komunikacja IPC oparta na gniazdach między modułami zbierania danych (pollerami, trapperami itp.) a procesem wstępnego przetwarzania. Kroki wstępnego przetwarzania wykonuje serwer Zabbix lub proxy Zabbix (dla pozycji monitorowanych przez proxy).
Przetwarzanie wartości pozycji
Aby zwizualizować przepływ danych od źródła danych do bazy danych Zabbix, możemy użyć następującego uproszczonego diagramu:
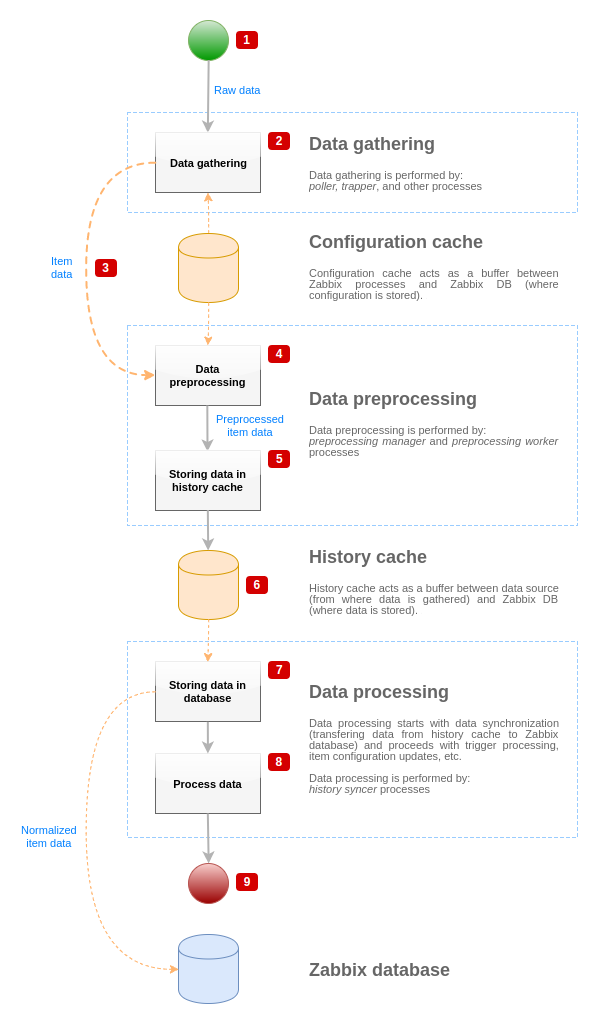
Powyższy diagram pokazuje tylko procesy, obiekty i działania związane z przetwarzaniem wartości pozycji w uproszczonej formie. Diagram nie pokazuje warunkowych zmian kierunku, obsługi błędów ani pętli. Nie pokazano również lokalnej pamięci podręcznej danych menedżera preprocessing, ponieważ nie wpływa ona bezpośrednio na przepływ danych. Celem tego diagramu jest pokazanie procesów biorących udział w przetwarzaniu wartości pozycji oraz sposobu ich współdziałania.
- Zbieranie danych rozpoczyna się od surowych danych ze źródła danych. Na tym etapie dane zawierają tylko identyfikator, znacznik czasu i wartość (może to być również wiele wartości).
- Niezależnie od tego, jaki typ mechanizmu zbierania danych jest używany, idea jest taka sama dla sprawdzeń aktywnych i pasywnych, dla pozycji trapper itd., ponieważ zmienia się tylko format danych i inicjator komunikacji (albo mechanizm zbierania danych oczekuje na połączenie i dane, albo inicjuje komunikację i żąda danych). Surowe dane są walidowane, konfiguracja pozycji jest pobierana z pamięci podręcznej konfiguracji (dane są wzbogacane o dane konfiguracyjne).
- Mechanizm IPC oparty na gniazdach jest używany do przekazywania danych z mechanizmów zbierania danych do menedżera preprocessing. W tym momencie mechanizm zbierania danych kontynuuje zbieranie danych bez oczekiwania na odpowiedź od menedżera preprocessing.
- Wykonywane jest preprocessing danych. Obejmuje to wykonanie kroków preprocessing oraz przetwarzanie pozycji zależnych.
Pozycja może zmienić swój stan na NOT SUPPORTED podczas wykonywania preprocessing, jeśli którykolwiek z kroków preprocessing zakończy się niepowodzeniem.
- Dane historyczne z lokalnej pamięci podręcznej danych menedżera preprocessing są opróżniane do pamięci podręcznej historii.
- W tym momencie przepływ danych zatrzymuje się do czasu następnej synchronizacji pamięci podręcznej historii (gdy proces synchronizacji historii wykonuje synchronizację danych).
- Proces synchronizacji rozpoczyna się od normalizacji danych przed zapisaniem ich w bazie danych Zabbix. Normalizacja danych wykonuje konwersje do żądanego typu pozycji (typu zdefiniowanego w konfiguracji pozycji), w tym obcinanie danych tekstowych na podstawie predefiniowanych rozmiarów dozwolonych dla tych typów (HISTORY_STR_VALUE_LEN dla string, HISTORY_TEXT_VALUE_LEN dla text oraz HISTORY_LOG_VALUE_LEN dla wartości log). Po zakończeniu normalizacji dane są wysyłane do bazy danych Zabbix.
Pozycja może zmienić swój stan na NOT SUPPORTED, jeśli normalizacja danych zakończy się niepowodzeniem (na przykład gdy wartości tekstowej nie można przekonwertować na liczbę).
- Zebrane dane są przetwarzane — sprawdzane są wyzwalacze, konfiguracja pozycji jest aktualizowana, jeśli pozycja staje się NOT SUPPORTED itd.
- Jest to uznawane za koniec przepływu danych z punktu widzenia przetwarzania wartości pozycji.
Wstępne przetwarzanie wartości pozycji
Wstępne przetwarzanie danych odbywa się w następujących krokach:
- Jeśli pozycja nie ma ani wstępnego przetwarzania, ani pozycji zależnych, jej wartość jest albo dodawana do pamięci podręcznej historii, albo wysyłana do menedżera LLD. W przeciwnym razie wartość pozycji jest przekazywana do menedżera wstępnego przetwarzania za pomocą mechanizmu IPC opartego na gniazdach UNIX.
- Tworzone jest zadanie wstępnego przetwarzania, dodawane do kolejki, a workery wstępnego przetwarzania są powiadamiane o nowym zadaniu.
- W tym momencie przepływ danych zatrzymuje się, dopóki nie będzie dostępny co najmniej jeden nieużywany (tj. niewykonujący żadnych zadań) worker wstępnego przetwarzania.
- Gdy worker wstępnego przetwarzania jest dostępny, pobiera następne zadanie z kolejki.
- Po zakończeniu wstępnego przetwarzania (zarówno w przypadku nieudanego, jak i udanego wykonania kroków wstępnego przetwarzania) wstępnie przetworzona wartość jest dodawana do kolejki zakończonych zadań, a menedżer jest powiadamiany o nowym zakończonym zadaniu.
- Menedżer wstępnego przetwarzania konwertuje wynik do żądanego formatu (zdefiniowanego przez typ wartości pozycji) i albo dodaje go do pamięci podręcznej historii, albo wysyła do menedżera LLD.
- Jeśli dla przetwarzanej pozycji istnieją pozycje zależne, są one dodawane do kolejki wstępnego przetwarzania z użyciem wstępnie przetworzonej wartości nadrzędnej pozycji. Pozycje zależne są umieszczane w kolejce z pominięciem zwykłych żądań wstępnego przetwarzania wartości, ale tylko dla pozycji nadrzędnych z ustawioną wartością i niebędących w stanie NOT SUPPORTED.

Należy pamiętać, że na diagramie wstępne przetwarzanie pozycji nadrzędnej jest nieco uproszczone przez pominięcie buforowania wstępnego przetwarzania.
Kolejka przetwarzania wstępnego
Kolejka przetwarzania wstępnego jest zorganizowana następująco:
-
lista oczekujących zadań:
- zadania utworzone bezpośrednio na podstawie żądań przetwarzania wstępnego wartości, w kolejności ich otrzymania
-
lista zadań natychmiastowych (przetwarzanych przed zadaniami oczekującymi):
- zadania testowe (tworzone w odpowiedzi na żądania testowania pozycja/przetwarzania wstępnego przez frontend)
- zadania zależnych pozycji
- zadania sekwencyjne (zadania, które muszą być wykonywane w ścisłej kolejności):
- posiadające kroki przetwarzania wstępnego wykorzystujące ostatnią wartość:
- zmiana
- ograniczanie
- JavaScript (buforowanie kodu bajtowego)
- buforowanie przetwarzania wstępnego zależnych pozycji
- posiadające kroki przetwarzania wstępnego wykorzystujące ostatnią wartość:
-
lista zakończonych zadań
Buforowanie przetwarzania wstępnego
Buforowanie przetwarzania wstępnego zostało wprowadzone w celu poprawy wydajności przetwarzania wstępnego dla wielu zależnych pozycji mających podobne kroki przetwarzania wstępnego (co jest częstym rezultatem LLD).
Buforowanie polega na przetworzeniu wstępnym jednej zależnej pozycji i ponownym wykorzystaniu części wewnętrznych danych przetwarzania wstępnego dla pozostałych zależnych pozycji. Pamięć podręczna przetwarzania wstępnego jest obsługiwana tylko dla pierwszego kroku przetwarzania wstępnego następujących typów:
- Wzorzec Prometheus (indeksuje dane wejściowe według metryk)
- JSONPath (parsuje dane do drzewa obiektów i indeksuje pierwsze wyrażenie
[?(@.path == "value")])
Procesy robocze przetwarzania wstępnego
Plik konfiguracyjny serwera Zabbix umożliwia użytkownikom ustawienie liczby wątków roboczych przetwarzania wstępnego. Parametr konfiguracyjny StartPreprocessors należy użyć do ustawienia liczby uruchomionych wcześniej instancji procesów roboczych przetwarzania wstępnego, która powinna co najmniej odpowiadać liczbie dostępnych rdzeni CPU.
Jeśli zadania przetwarzania wstępnego nie są ograniczone przez CPU i obejmują częste żądania sieciowe, zaleca się skonfigurowanie dodatkowych procesów roboczych. Optymalną liczbę procesów roboczych przetwarzania wstępnego można określić na podstawie wielu czynników, w tym liczby "preprocessable" pozycji (pozycji, które wymagają wykonania dowolnych kroków przetwarzania wstępnego), liczby procesów zbierania danych, średniej liczby kroków dla przetwarzania wstępnego pozycji itp. Niewystarczająca liczba procesów roboczych może prowadzić do wysokiego użycia pamięci. W celu rozwiązywania problemów z nadmiernym użyciem pamięci w instalacji Zabbix, zobacz Profiling excessive memory usage with tcmalloc.
Zakładając jednak, że nie występują ciężkie operacje przetwarzania wstępnego, takie jak analizowanie dużych fragmentów XML/JSON, liczba procesów roboczych przetwarzania wstępnego może odpowiadać łącznej liczbie procesów zbierających dane. W ten sposób zazwyczaj (z wyjątkiem przypadków, gdy dane od zbierającego przychodzą zbiorczo) co najmniej jeden proces roboczy przetwarzania wstępnego będzie wolny dla zebranych danych.
Zbyt duża liczba procesów zbierania danych (pollers, unreachable pollers, ODBC pollers, HTTP pollers, Java pollers, pingers, trappers, proxypollers) wraz z menedżerem IPMI, trapperem SNMP i procesami roboczymi przetwarzania wstępnego może wyczerpać limit deskryptorów plików na proces dla menedżera przetwarzania wstępnego.
Wyczerpanie limitu deskryptorów plików na proces spowoduje zatrzymanie serwera Zabbix, zwykle krótko po uruchomieniu, ale czasami dopiero po dłuższym czasie.
Aby uniknąć takich problemów, przejrzyj plik konfiguracyjny serwera Zabbix, aby zoptymalizować liczbę jednoczesnych kontroli i procesów.
Dodatkowo, w razie potrzeby upewnij się, że limit deskryptorów plików jest ustawiony wystarczająco wysoko, sprawdzając i dostosowując limity systemowe.
Potok przetwarzania wartości
Przetwarzanie wartości pozycji jest wykonywane w wielu krokach (lub fazach) przez wiele procesów. Może to powodować:
- Zależna pozycja może otrzymywać wartości, podczas gdy wartość główna NIE może.
Można to osiągnąć przy użyciu następującego przypadku użycia:
- Główna pozycja ma typ wartości
UINT(można użyć trapper item), zależna pozycja ma typ wartościTEXT. - Dla głównej i zależnej pozycji nie są wymagane żadne kroki preprocessing.
- Wartość tekstowa (na przykład „abc”) powinna zostać przekazana do głównej pozycji.
- Ponieważ nie ma kroków preprocessing do wykonania, menedżer preprocessing sprawdza, czy główna pozycja nie jest w stanie NOT SUPPORTED oraz czy wartość jest ustawiona (oba warunki są spełnione), a następnie umieszcza zależną pozycję w kolejce z tą samą wartością co główna pozycja (ponieważ nie ma kroków preprocessing).
- Gdy zarówno główna, jak i zależna pozycja osiągną fazę synchronizacji historii, główna pozycja przechodzi w stan NOT SUPPORTED z powodu błędu konwersji wartości (dane tekstowe nie mogą zostać przekonwertowane na liczbę całkowitą bez znaku).
- Główna pozycja ma typ wartości
W rezultacie zależna pozycja otrzymuje wartość, podczas gdy główna pozycja zmienia swój stan na NOT SUPPORTED.
- Zależna pozycja otrzymuje wartość, która nie jest obecna w historii
głównej pozycji. Ten przypadek użycia jest bardzo podobny do poprzedniego, z wyjątkiem
typu głównej pozycji. Na przykład, jeśli dla głównej pozycji używany jest typ
CHAR, to wartość głównej pozycji zostanie obcięta w fazie synchronizacji historii, podczas gdy zależne pozycje otrzymają swoje wartości z początkowej (nieobciętej) wartości głównej pozycji.