
Eskalacje
Przegląd
Za pomocą eskalacji można tworzyć niestandardowe scenariusze wysyłania powiadomień lub wykonywania zdalnych poleceń.
W praktyce oznacza to, że:
- Użytkownicy mogą być natychmiast informowani o nowych problemach.
- Powiadomienia mogą być powtarzane do momentu rozwiązania problemu.
- Wysłanie powiadomienia może zostać opóźnione.
- Powiadomienia mogą być eskalowane do innej, „wyższej” grupy użytkowników.
- Zdalne polecenia mogą być wykonywane natychmiast lub wtedy, gdy problem nie zostanie rozwiązany przez dłuższy czas.
Akcje są eskalowane na podstawie kroku eskalacji. Każdy krok ma określony czas trwania.
Można zdefiniować zarówno domyślny czas trwania, jak i niestandardowy czas trwania poszczególnego kroku. Minimalny czas trwania jednego kroku eskalacji wynosi 60 sekund.
Można uruchamiać akcje, takie jak wysyłanie powiadomień lub wykonywanie poleceń, od dowolnego kroku. Krok pierwszy służy do działań natychmiastowych. Jeśli chcesz opóźnić akcję, możesz przypisać ją do późniejszego kroku. Dla każdego kroku można zdefiniować kilka akcji.
Liczba kroków eskalacji nie jest ograniczona.
Eskalacje są definiowane podczas konfigurowania operacji. Eskalacje są obsługiwane tylko dla operacji problemowych, a nie dla odzyskiwania.
Różne aspekty zachowania eskalacji
Rozważmy, co dzieje się w różnych okolicznościach, jeśli akcja zawiera kilka kroków eskalacji.
| Situation | Behavior |
|---|---|
| Host, którego dotyczy problem, przechodzi w tryb konserwacji po wysłaniu początkowego powiadomienia o problemie | W zależności od ustawienia Pause operations for suppressed problems w konfiguracji akcji configuration, wszystkie pozostałe kroki eskalacji są wykonywane albo z opóźnieniem spowodowanym okresem konserwacji, albo bez opóźnienia. Okres konserwacji nie anuluje operacji. |
| Okres czasu zdefiniowany w warunku akcji Time period kończy się po wysłaniu początkowego powiadomienia | Wszystkie pozostałe kroki eskalacji są wykonywane. Warunek Time period nie może zatrzymać operacji; wpływa on na to, kiedy akcje są uruchamiane lub nieuruchamiane, a nie na operacje. |
| Problem rozpoczyna się podczas konserwacji i trwa nadal (nie zostaje rozwiązany) po jej zakończeniu | W zależności od ustawienia Pause operations for suppressed problems w konfiguracji akcji configuration, wszystkie kroki eskalacji są wykonywane albo od momentu zakończenia konserwacji, albo natychmiast. |
| Problem rozpoczyna się podczas konserwacji typu no-data i trwa nadal (nie zostaje rozwiązany) po jej zakończeniu | Musi poczekać, aż wyzwalacz zadziała, zanim zostaną wykonane wszystkie kroki eskalacji. |
| Różne eskalacje następują po sobie w krótkich odstępach czasu i nakładają się | Wykonanie każdej nowej eskalacji zastępuje poprzednią eskalację, ale co najmniej jeden krok eskalacji jest zawsze wykonywany w ramach poprzedniej eskalacji. To zachowanie ma znaczenie w akcjach dotyczących zdarzeń, które są tworzone przy KAŻDEJ ocenie problemu przez wyzwalacz. |
| Podczas trwającej eskalacji (na przykład podczas wysyłania wiadomości), w zależności od dowolnego typu zdarzenia: - akcja jest wyłączona W przypadku zdarzenia wyzwalacza: - wyzwalacz jest wyłączony - host lub pozycja jest wyłączony W przypadku zdarzenia wewnętrznego dotyczącego wyzwalaczy: - wyzwalacz jest wyłączony W przypadku zdarzenia wewnętrznego dotyczącego pozycji/reguł wykrywania niskiego poziomu: - pozycja jest wyłączona - host jest wyłączony |
Trwająca wiadomość jest wysyłana, a następnie wysyłana jest jeszcze jedna wiadomość w ramach eskalacji. Wiadomość uzupełniająca będzie zawierać tekst anulowania na początku treści wiadomości (NOTE: Escalation canceled) z podaniem przyczyny (na przykład NOTE: Escalation canceled: action '<Action name>' disabled). W ten sposób odbiorca zostaje poinformowany, że eskalacja została anulowana i nie będą wykonywane dalsze kroki. Ta wiadomość jest wysyłana do wszystkich, którzy wcześniej otrzymali powiadomienia. Przyczyna anulowania jest również zapisywana w pliku dziennika serwera (od Debug Level 3=Warning). Należy pamiętać, że wiadomość Escalation canceled jest również wysyłana, jeśli operacje zostały zakończone, ale operacje odzyskiwania są skonfigurowane i nie zostały jeszcze wykonane. |
| Podczas trwającej eskalacji (na przykład podczas wysyłania wiadomości) akcja zostaje usunięta | Nie są wysyłane żadne dalsze wiadomości. Informacja jest zapisywana w pliku dziennika serwera (od Debug Level 3=Warning), na przykład: escalation canceled: action id:334 deleted |
Przykłady eskalacji
Przykład 1
Wysyłanie powtarzanego powiadomienia co 30 minut (łącznie 5 razy) do grupy „MySQL Administrators”. Aby to skonfigurować:
- Na karcie Operations ustaw Default operation step duration na „30m” (30 minut).
- Ustaw Steps eskalacji od „1” do „5”.
- Wybierz grupę „MySQL Administrators” jako odbiorców wiadomości.
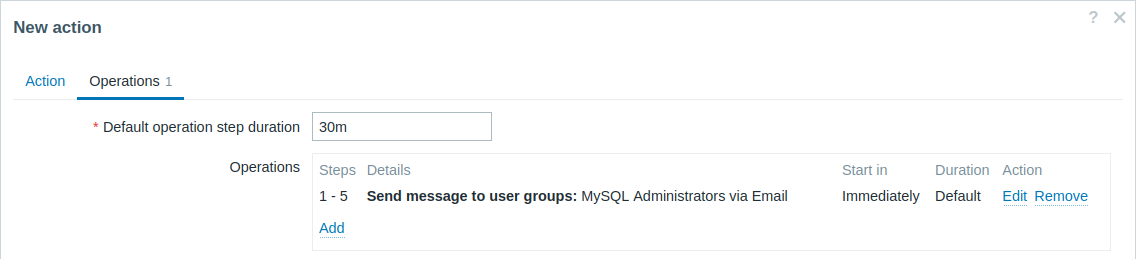
Powiadomienia będą wysyłane po 0:00, 0:30, 1:00, 1:30 i 2:00 godziny od wystąpienia problemu (chyba że problem zostanie oczywiście rozwiązany wcześniej).
Jeśli problem zostanie rozwiązany i skonfigurowano wiadomość o odzyskaniu, zostanie ona wysłana do tych, którzy otrzymali co najmniej jedną wiadomość o problemie w ramach tego scenariusza eskalacji.
Jeśli wyzwalacz, który wygenerował aktywną eskalację, zostanie wyłączony, Zabbix wyśle wszystkim osobom, które otrzymały już powiadomienia, wiadomość informacyjną na ten temat.
Przykład 2
Wysyłanie opóźnionego powiadomienia o długotrwałym problemie. Aby to skonfigurować:
- Na karcie Operations ustaw Default operation step duration na „10h” (10 godzin).
- Ustaw Steps eskalacji od „2” do „2”.
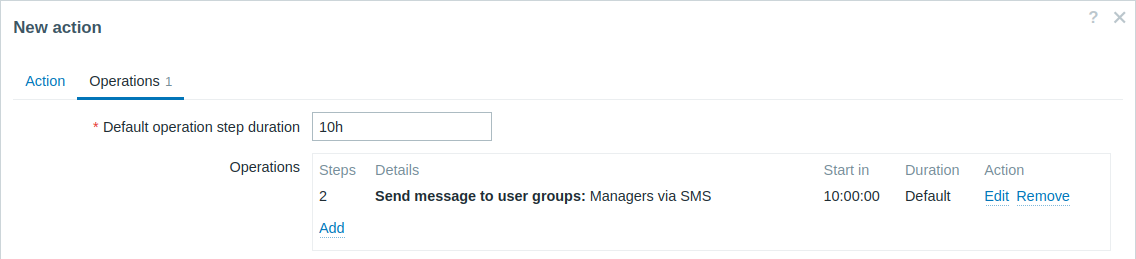
Powiadomienie zostanie wysłane dopiero w kroku 2 scenariusza eskalacji, czyli 10 godzin po wystąpieniu problemu.
Możesz dostosować treść wiadomości do czegoś w rodzaju „Problem trwa dłużej niż 10 godzin”.
Przykład 3
Eskalacja problemu do Szefa.
W pierwszym przykładzie powyżej skonfigurowaliśmy okresowe wysyłanie wiadomości do administratorów MySQL. W tym przypadku administratorzy otrzymają cztery wiadomości, zanim problem zostanie eskalowany do menedżera bazy danych. Należy pamiętać, że menedżer otrzyma wiadomość tylko wtedy, gdy problem nie został jeszcze potwierdzony, co oznacza, że prawdopodobnie nikt jeszcze nad nim nie pracuje.
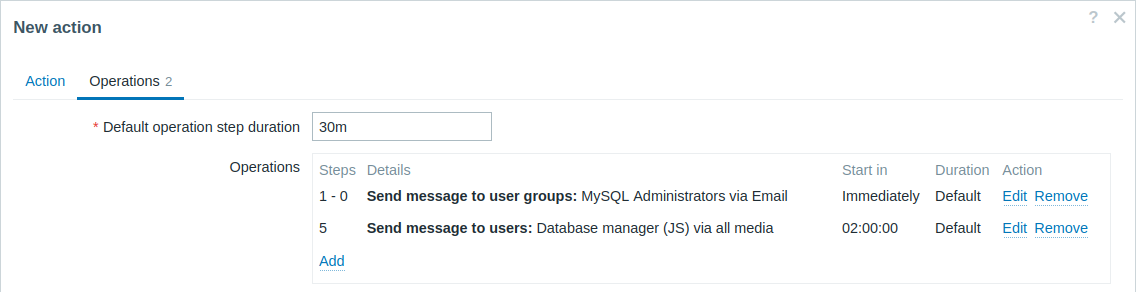
Szczegóły operacji 2:
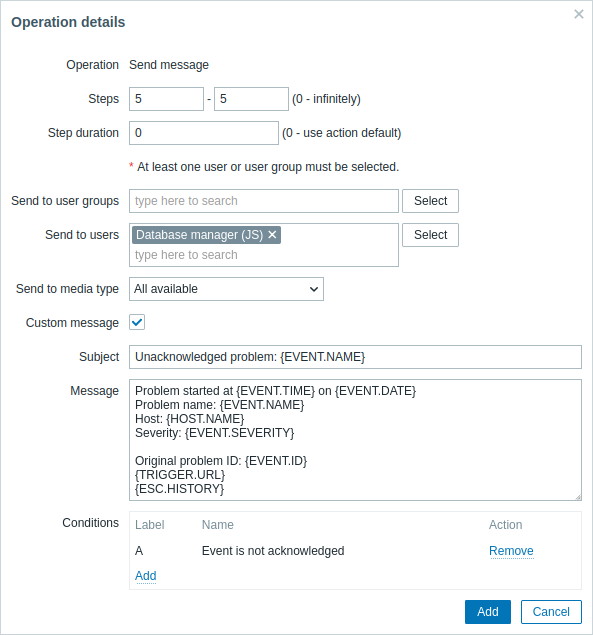
Zwróć uwagę na użycie makra {ESC.HISTORY} w dostosowanej wiadomości. Makro to będzie zawierać informacje o wszystkich wcześniej wykonanych krokach tej eskalacji, takich jak wysłane powiadomienia i wykonane polecenia.
Przykład 4
Bardziej złożony scenariusz. Po wysłaniu wielu wiadomości do administratorów MySQL i eskalacji do menedżera, Zabbix spróbuje ponownie uruchomić bazę danych MySQL. Stanie się to, jeśli problem będzie występował przez 2:30 godziny i nie zostanie potwierdzony.
Jeśli problem nadal będzie występował, po kolejnych 30 minutach Zabbix wyśle wiadomość do wszystkich użytkowników gościnnych.
Jeśli to nie pomoże, po kolejnej godzinie Zabbix zrestartuje serwer z bazą danych MySQL (drugie zdalne polecenie) przy użyciu poleceń IPMI.
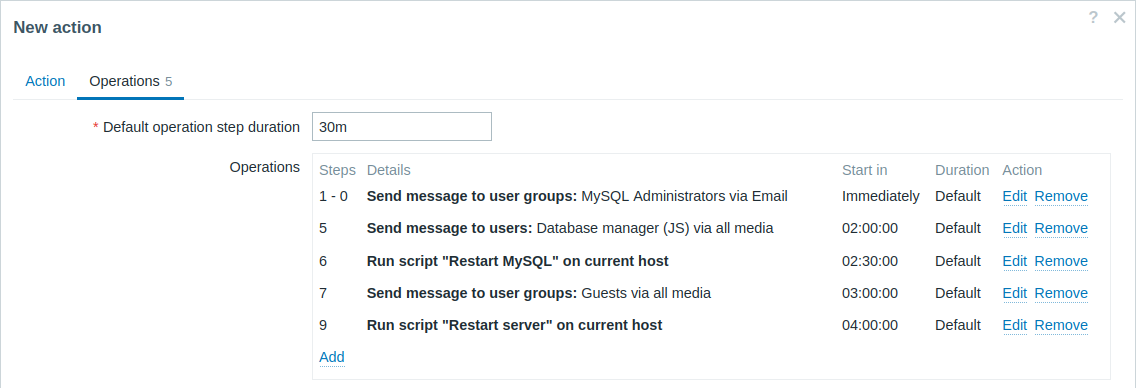
Przykład 5
Eskalacja z kilkoma operacjami, które mają nakładające się zakresy kroków i niestandardowe interwały. Domyślny czas trwania kroku operacji wynosi 30 minut.
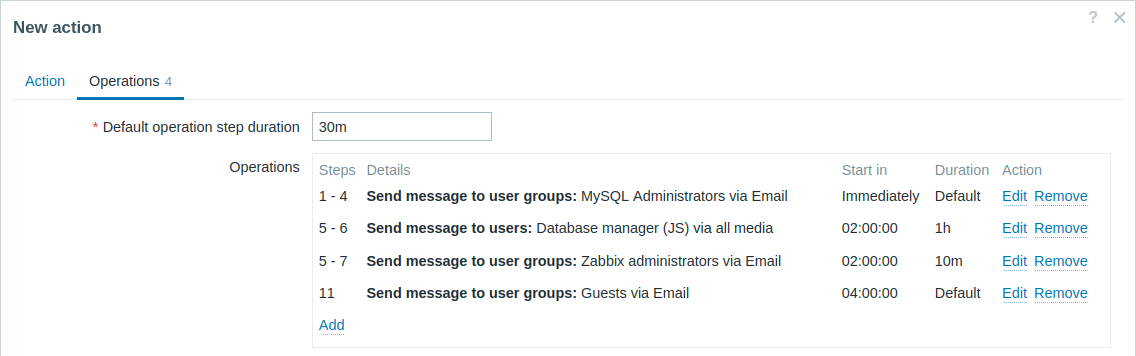
Powiadomienia będą wysyłane w następujący sposób:
- Do administratorów MySQL o 0:00, 0:30, 1:00 i 1:30 od momentu wystąpienia problemu.
- Do menedżera bazy danych o 2:00 i 2:10 (krótszy niestandardowy czas trwania kroku wynoszący 10 minut, zdefiniowany w kolejnej operacji, zastępuje dłuższy czas trwania kroku wynoszący 1 godzinę skonfigurowany tutaj, zgodnie z opisem w Szczegóły operacji dla Czas trwania kroku, gdy kroki nakładają się).
- Do administratorów Zabbix o 2:00, 2:10 i 2:20 od momentu wystąpienia problemu (zastosowany jest niestandardowy czas trwania kroku wynoszący 10 minut).
- Do użytkowników guest o 4:00 od momentu wystąpienia problemu (domyślny czas trwania kroku wynoszący 30 minut obowiązuje między krokami 8 i 11).