
Подробности предварительной обработки
Обзор
В этом разделе приведены сведения о предварительной обработке значений элементов данных. Предварительная обработка значений элементов данных позволяет определять и выполнять правила преобразования для полученных значений элементов данных.
Предварительная обработка управляется процессом менеджера предварительной обработки вместе с рабочими процессами предварительной обработки, которые выполняют шаги предварительной обработки. Все значения с предварительной обработкой, полученные от разных сборщиков данных, проходят через менеджер предварительной обработки перед добавлением в кэш истории. Для обмена данными между сборщиками данных (pollers, trappers и т. д.) и процессом предварительной обработки используется IPC-связь на основе сокетов. Шаги предварительной обработки выполняет либо сервер Zabbix, либо прокси Zabbix (для элементов данных, контролируемых прокси).
Обработка значений элементов данных
Чтобы визуализировать поток данных от источника данных до базы данных Zabbix, можно использовать следующую упрощенную диаграмму:
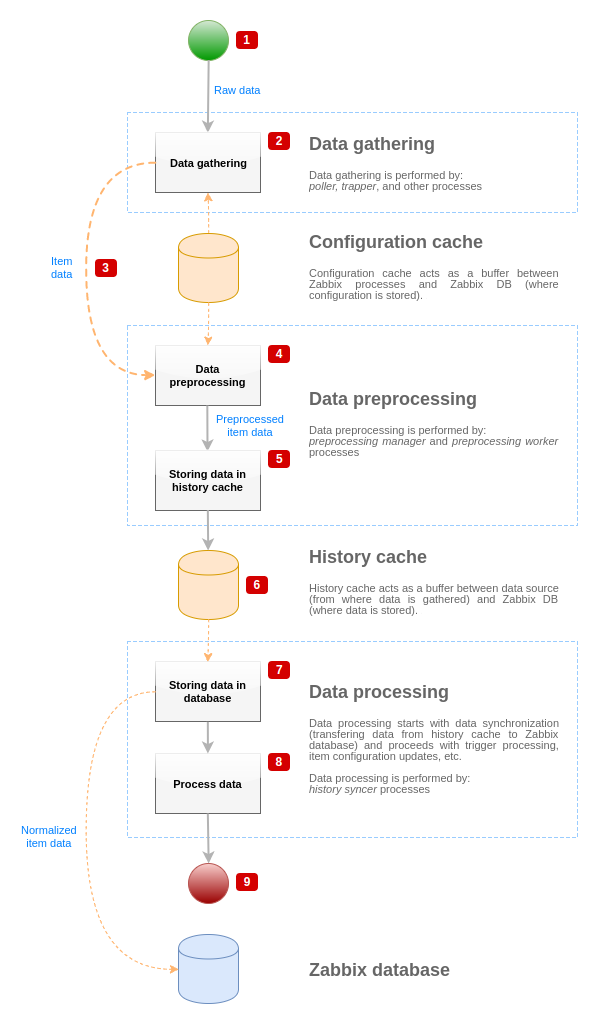
Диаграмма выше показывает только процессы, объекты и действия, связанные с обработкой значений элементов данных, в упрощенном виде. На диаграмме не показаны изменения направления при выполнении условий, обработка ошибок или циклы. Локальный кэш данных менеджера предварительной обработки также не показан, поскольку он напрямую не влияет на поток данных. Цель этой диаграммы — показать процессы, участвующие в обработке значений элементов данных, и то, как они взаимодействуют.
- Сбор данных начинается с необработанных данных из источника данных. На этом этапе данные содержат только ID, метку времени и значение (возможны также несколько значений).
- Независимо от того, какой тип сборщика данных используется, принцип остается одинаковым для активных и пассивных проверок, для элементов данных типа trapper и т. д., поскольку меняется только формат данных и инициатор связи (либо сборщик данных ожидает соединения и данные, либо сборщик данных инициирует связь и запрашивает данные). Необработанные данные проверяются, конфигурация элемента данных извлекается из кэша конфигурации (данные дополняются конфигурационной информацией).
- Для передачи данных от сборщиков данных к менеджеру предварительной обработки используется IPC-механизм на основе сокетов. На этом этапе сборщик данных продолжает собирать данные, не ожидая ответа от менеджера предварительной обработки.
- Выполняется предварительная обработка данных. Она включает выполнение шагов предварительной обработки и обработку зависимых элементов данных.
Элемент данных может изменить свое состояние на NOT SUPPORTED во время выполнения предварительной обработки, если любой из шагов предварительной обработки завершится с ошибкой.
- Исторические данные из локального кэша данных менеджера предварительной обработки переносятся в кэш истории.
- На этом этапе поток данных останавливается до следующей синхронизации кэша истории (когда процесс синхронизации истории выполняет синхронизацию данных).
- Процесс синхронизации начинается с нормализации данных перед сохранением в базе данных Zabbix. Нормализация данных выполняет преобразование к требуемому типу элемента данных (тип, определенный в конфигурации элемента данных), включая усечение текстовых данных на основе предопределенных размеров, разрешенных для этих типов (HISTORY_STR_VALUE_LEN для string, HISTORY_TEXT_VALUE_LEN для text и HISTORY_LOG_VALUE_LEN для log values). После завершения нормализации данные отправляются в базу данных Zabbix.
Элемент данных может изменить свое состояние на NOT SUPPORTED, если нормализация данных завершится с ошибкой (например, когда текстовое значение не может быть преобразовано в число).
- Собранные данные обрабатываются — проверяются триггеры, обновляется конфигурация элемента данных, если элемент данных становится NOT SUPPORTED, и т. д.
- Это считается завершением потока данных с точки зрения обработки значений элементов данных.
Предобработка значения элемента данных
Предобработка данных выполняется в следующих шагах:
- Если у элемента данных нет ни предобработки, ни зависимых элементов данных, его значение либо добавляется в кэш истории, либо отправляется в менеджер LLD. В противном случае значение элемента данных передается в менеджер предобработки с использованием механизма IPC на основе UNIX-сокета.
- Создается задача предобработки, она добавляется в очередь, а рабочие процессы предобработки уведомляются о новой задаче.
- На этом этапе поток данных останавливается до тех пор, пока не появится хотя бы один свободный (то есть не выполняющий никаких задач) рабочий процесс предобработки.
- Когда рабочий процесс предобработки становится доступен, он берет следующую задачу из очереди.
- После завершения предобработки (как при неудачном, так и при успешном выполнении шагов предобработки) предварительно обработанное значение добавляется в очередь завершенных задач, а менеджер уведомляется о новой завершенной задаче.
- Менеджер предобработки преобразует результат в нужный формат (определяемый типом значения элемента данных) и либо добавляет его в кэш истории, либо отправляет в менеджер LLD.
- Если для обработанного элемента данных есть зависимые элементы данных, то они добавляются в очередь предобработки с предварительно обработанным значением основного элемента данных. Зависимые элементы данных помещаются в очередь в обход обычных запросов на предобработку значений, но только для основных элементов данных со значением, которое задано, и не находящихся в состоянии NOT SUPPORTED.

Обратите внимание, что на диаграмме предобработка основного элемента данных немного упрощена за счет пропуска кэширования предобработки.
Очередь предварительной обработки
Очередь предварительной обработки организована следующим образом:
-
список ожидающих задач:
- задачи, созданные непосредственно из запросов предварительной обработки значений в порядке их получения
-
список немедленных задач (обрабатываемых до ожидающих задач):
- задачи тестирования (созданы в ответ на запросы тестирования элементов данных/предварительной обработки веб-интерфейсом)
- задачи зависимых элементов данных
- последовательные задачи (задачи, которые должны выполняться в строгом порядке):
- имеющие шаги предварительной обработки с использованием последнего значения:
- изменение
- троттлинг
- JavaScript (кэширование байт-кода)
- кэширование предварительной обработки зависимых элементов данных
-
список завершённых задач
Кэширование предварительной обработки
Кэширование предварительной обработки было введено для повышения производительности предварительной обработки для нескольких зависимых элементов данных, имеющих схожие шаги предварительной обработки (что является распространённым результатом LLD).
Кэширование выполняется путём предварительной обработки одного зависимого элемента данных и повторного использования некоторых внутренних данных предварительной обработки для остальных зависимых элементов данных. Кэширование предварительной обработки поддерживается только для первого шага предварительной обработки следующих типов:
- шаблон Prometheus (индексирует входные данные по метрикам)
- JSONPath (разбирает данные в дерево объектов и индексирует первое выражение
[?(@.path == "значение")])
Рабочие процессы предварительной обработки
Файл конфигурации сервера Zabbix позволяет пользователям задавать количество потоков рабочих процессов предварительной обработки. Параметр конфигурации StartPreprocessors следует использовать для задания числа заранее запущенных экземпляров рабочих процессов предварительной обработки, которое должно как минимум соответствовать числу доступных ядер CPU.
Если задачи предварительной обработки не ограничены CPU и предполагают частые сетевые запросы, рекомендуется настроить дополнительных рабочих процессов. Оптимальное количество рабочих процессов предварительной обработки можно определить по многим факторам, включая количество "preprocessable" элементов данных (элементов данных, для которых требуется выполнение любых шагов предварительной обработки), количество процессов сбора данных, среднее число шагов предварительной обработки для элемента данных и т. д. Недостаточное количество рабочих процессов может привести к высокому потреблению памяти. Для устранения неполадок, связанных с чрезмерным использованием памяти в вашей установке Zabbix, см. Профилирование чрезмерного использования памяти с tcmalloc.
Однако если предположить, что нет ресурсоемких операций предварительной обработки, таких как разбор больших фрагментов XML/JSON, количество рабочих процессов предварительной обработки может соответствовать общему числу сборщиков данных. В этом случае в основном (за исключением случаев, когда данные от сборщика поступают пакетно) для собранных данных будет как минимум один свободный рабочий процесс предварительной обработки.
Слишком большое количество процессов сбора данных (pollers, unreachable pollers, ODBC pollers, HTTP pollers, Java pollers, pingers, trappers, proxypollers) вместе с IPMI manager, SNMP trapper и рабочими процессами предварительной обработки может исчерпать лимит файловых дескрипторов на процесс для preprocessing manager.
Исчерпание лимита файловых дескрипторов на процесс приведет к остановке сервера Zabbix, обычно вскоре после запуска, но иногда это занимает больше времени.
Чтобы избежать таких проблем, проверьте файл конфигурации сервера Zabbix и оптимизируйте количество одновременных проверок и процессов.
Кроме того, при необходимости убедитесь, что лимит файловых дескрипторов установлен достаточно высоким, проверив и скорректировав системные ограничения.
Поток обработки значения
Предварительная обработка значения элемента данных выполняется в несколько шагов (или фаз) несколькими процессами. Это может привести к тому, что:
- Зависимый элемент данных может получить значения, в то время как основной элемент данных — нет. Такое может произойти при следующем сценарии:
- У основного элемента данных тип значения
UINT(можно использовать элемент данных траппер), у зависимого элемента данных тип значенияTEXT. - Шаги предварительной обработки не требуются ни для основного, ни для зависимого элементов данных.
- Основному элементу данных необходимо передать текстовое значение (например, «abc»).
- Поскольку нет шагов предварительной обработки для выполнения, менеджер предварительной обработки проверяет, что основной элемент данных не находится в НЕПОДДЕРЖИВАЕМОМ состоянии и что имеется значение (оба условия выполняются), и помещает в очередь зависимый элемент данных с таким же значением, что и основной элемент данных (поскольку шаги предварительной обработки отсутствуют).
- Когда основной и зависимый элементы данных переходят в фазу синхронизации истории, основной элемент данных становится НЕПОДДЕРЖИВАЕМЫМ из-за ошибки конвертации значения (текстовые данные невозможно преобразовать в целое положительное число).
- У основного элемента данных тип значения
В результате зависимый элемент данных получает значение, тогда как основной элемент данных меняет свое состояние на НЕ ПОДДЕРЖИВАЕТСЯ.
- Зависимый элемент данных получает значение, которое отсутствует в истории основного элемента данных. Данный случай очень похож на предыдущий, за исключением типа основного элемента данных. Например, если у основного элемента данных используется тип
CHAR, то значение основного элемента данных будет усечено на стадии синхронизации истории, в то время как зависимые элементы данных получат свои значения с изначального (не усечённого) значения основного элемента данных.