
Detalles de preprocesamiento
Descripción general
Esta sección proporciona detalles sobre el preprocesamiento de valores de ítems. El preprocesamiento de valores de ítems permite definir y ejecutar reglas de transformación para los valores de ítems recibidos.
El preprocesamiento es gestionado por el proceso del gestor de preprocesamiento junto con los trabajadores de preprocesamiento que realizan los pasos de preprocesamiento. Todos los valores con preprocesamiento, recibidos de diferentes recolectores de datos, pasan por el gestor de preprocesamiento antes de ser añadidos a la caché de historial. Se utiliza comunicación IPC basada en sockets entre los recolectores de datos (pollers, trappers, etc.) y el proceso de preprocesamiento. Tanto el servidor Zabbix como el proxy Zabbix (para los ítems monitorizados por el proxy) realizan los pasos de preprocesamiento.
Procesamiento del valor del item
Para visualizar el flujo de datos desde la fuente de datos hasta la base de datos de Zabbix, podemos utilizar el siguiente diagrama simplificado:
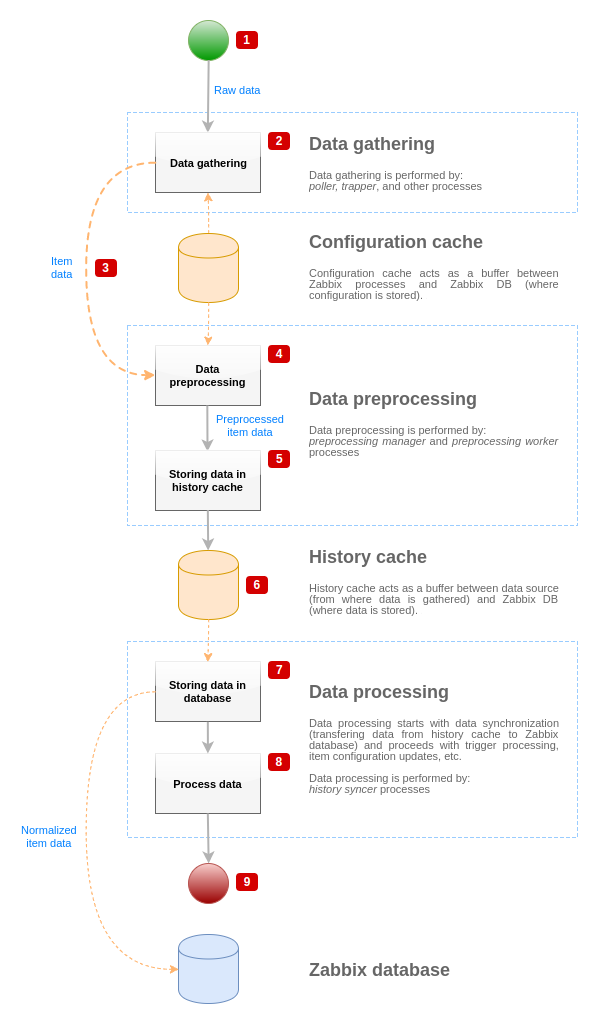
El diagrama anterior muestra solo los procesos, objetos y acciones relacionados con el procesamiento del valor del item en una forma simplificada. El diagrama no muestra cambios condicionales de dirección, manejo de errores o bucles. La caché de datos local del gestor de preprocesamiento tampoco se muestra porque no afecta directamente al flujo de datos. El objetivo de este diagrama es mostrar los procesos involucrados en el procesamiento del valor del item y la forma en que interactúan.
- La recopilación de datos comienza con datos sin procesar de una fuente de datos. En este punto, los datos contienen solo ID, marca de tiempo y valor (también pueden ser múltiples valores).
- No importa qué tipo de recopilador de datos se utilice, la idea es la misma para comprobaciones activas o pasivas, para items trapper, etc., ya que solo cambia el formato de los datos y el iniciador de la comunicación (ya sea que el recopilador de datos esté esperando una conexión y datos, o el recopilador de datos inicia la comunicación y solicita los datos). Los datos sin procesar se validan, la configuración del item se recupera de la caché de configuración (los datos se enriquecen con los datos de configuración).
- Se utiliza un mecanismo IPC basado en sockets para pasar los datos de los recopiladores de datos al gestor de preprocesamiento. En este punto, el recopilador de datos continúa recopilando datos sin esperar la respuesta del gestor de preprocesamiento.
- Se realiza el preprocesamiento de los datos. Esto incluye la ejecución de los pasos de preprocesamiento y el procesamiento de items dependientes.
Un item puede cambiar su estado a NO SOPORTADO mientras se realiza el preprocesamiento si alguno de los pasos de preprocesamiento falla.
- Los datos históricos de la caché de datos local del gestor de preprocesamiento se vacían en la caché de historial.
- En este punto, el flujo de datos se detiene hasta la siguiente sincronización de la caché de historial (cuando el proceso de sincronización de historial realiza la sincronización de datos).
- El proceso de sincronización comienza con la normalización de los datos antes de almacenar los datos en la base de datos de Zabbix. La normalización de datos realiza conversiones al tipo de item deseado (tipo definido en la configuración del item), incluida la truncación de datos textuales según los tamaños predefinidos permitidos para esos tipos (HISTORY_STR_VALUE_LEN para string, HISTORY_TEXT_VALUE_LEN para text y HISTORY_LOG_VALUE_LEN para valores de log). Los datos se envían a la base de datos de Zabbix después de que se completa la normalización.
Un item puede cambiar su estado a NO SOPORTADO si la normalización de datos falla (por ejemplo, cuando un valor textual no se puede convertir a número).
- Los datos recopilados se procesan: se comprueban los triggers, se actualiza la configuración del item si el item se vuelve NO SOPORTADO, etc.
- Esto se considera el final del flujo de datos desde el punto de vista del procesamiento del valor del item.
Preprocesamiento del valor del ítem
El preprocesamiento de datos se realiza en los siguientes pasos:
- Si el ítem no tiene preprocesamiento ni ítems dependientes, su valor se agrega a la caché de historial o se envía al gestor de LLD. De lo contrario, el valor del ítem se pasa al gestor de preprocesamiento utilizando un mecanismo IPC basado en sockets UNIX.
- Se crea una tarea de preprocesamiento y se añade a la cola, y se notifica a los trabajadores de preprocesamiento sobre la nueva tarea.
- En este punto, el flujo de datos se detiene hasta que haya al menos un trabajador de preprocesamiento desocupado (es decir, que no esté ejecutando ninguna tarea).
- Cuando un trabajador de preprocesamiento está disponible, toma la siguiente tarea de la cola.
- Una vez realizado el preprocesamiento (tanto si la ejecución de los pasos de preprocesamiento falla como si tiene éxito), el valor preprocesado se añade a la cola de tareas finalizadas y se notifica al gestor sobre una nueva tarea finalizada.
- El gestor de preprocesamiento convierte el resultado al formato deseado (definido por el tipo de valor del ítem) y lo agrega a la caché de historial o lo envía al gestor de LLD.
- Si hay ítems dependientes para el ítem procesado, entonces los ítems dependientes se añaden a la cola de preprocesamiento con el valor preprocesado del ítem maestro. Los ítems dependientes se ponen en cola omitiendo las solicitudes normales de preprocesamiento de valores, pero solo para ítems maestros con el valor establecido y que no estén en estado NO SOPORTADO.

Tenga en cuenta que en el diagrama el preprocesamiento del ítem maestro está ligeramente simplificado al omitir el almacenamiento en caché del preprocesamiento.
Cola de preprocesamiento
La cola de preprocesamiento se organiza como:
-
la lista de tareas pendientes:
- tareas creadas directamente a partir de solicitudes de preprocesamiento de valores en el orden en que se recibieron
-
la lista de tareas inmediatas (procesadas antes que las tareas pendientes):
- tareas de prueba (creadas en respuesta a solicitudes de prueba de métrica/preprocesamiento por la interfaz web)
- tareas de métricas dependientes
- tareas de secuencia (tareas que deben ejecutarse en un orden estricto):
- que tienen pasos de preprocesamiento usando el último valor:
- cambio
- limitación de frecuencia
- JavaScript (caché de bytecode)
- caché de preprocesamiento de métricas dependientes
- que tienen pasos de preprocesamiento usando el último valor:
-
la lista de tareas finalizadas
Caché de preprocesamiento
Se introdujo la caché de preprocesamiento para mejorar el rendimiento del preprocesamiento en múltiples métricas dependientes que tienen pasos de preprocesamiento similares (lo cual es un resultado común de LLD).
La caché se realiza preprocesando una métrica dependiente y reutilizando algunos de los datos internos de preprocesamiento para el resto de las métricas dependientes. La caché de preprocesamiento solo es compatible con el primer paso de preprocesamiento de los siguientes tipos:
- Patrón Prometheus (indexa la entrada por métricas)
- JSONPath (analiza los datos en un árbol de objetos e indexa la primera expresión
[?(@.path == "value")])
Workers de preprocesamiento
El archivo de configuración de Zabbix server permite a los usuarios establecer la cantidad de hilos de workers de preprocesamiento. El parámetro de configuración StartPreprocessors debe usarse para definir el número de instancias preiniciadas de workers de preprocesamiento, que como mínimo debe coincidir con el número de núcleos de CPU disponibles.
Si las tareas de preprocesamiento no están limitadas por la CPU e implican solicitudes de red frecuentes, se recomienda configurar workers adicionales. El número óptimo de workers de preprocesamiento puede determinarse por muchos factores, incluido el número de items "preprocesables" (items que requieren ejecutar cualquier paso de preprocesamiento), el número de procesos de recopilación de datos, el número promedio de pasos para el preprocesamiento de items, etc. Un número insuficiente de workers puede provocar un alto uso de memoria. Para solucionar problemas de uso excesivo de memoria en su instalación de Zabbix, consulte Profiling excessive memory usage with tcmalloc.
Pero suponiendo que no haya operaciones de preprocesamiento intensivas, como el análisis de grandes fragmentos XML/JSON, el número de workers de preprocesamiento puede coincidir con el número total de recolectores de datos. De este modo, normalmente (excepto en los casos en que los datos del recolector llegan en bloque) habrá al menos un worker de preprocesamiento libre para los datos recopilados.
Demasiados procesos de recopilación de datos (pollers, unreachable pollers, ODBC pollers, HTTP pollers, Java pollers, pingers, trappers, proxypollers) junto con IPMI manager, SNMP trapper y workers de preprocesamiento pueden agotar el límite de descriptores de archivo por proceso para el preprocessing manager.
Agotar el límite de descriptores de archivo por proceso hará que Zabbix server se detenga, normalmente poco después del inicio, aunque a veces puede tardar más.
Para evitar este tipo de problemas, revise el archivo de configuración de Zabbix server para optimizar el número de comprobaciones y procesos simultáneos.
Además, si es necesario, asegúrese de que el límite de descriptores de archivo esté configurado suficientemente alto comprobando y ajustando los límites del sistema.
Canalización de procesamiento de valores
El procesamiento de valores de métricas se ejecuta en múltiples pasos (o fases) por múltiples procesos. Esto puede causar:
- Una métrica dependiente puede recibir valores, mientras que la métrica principal no puede.
Esto se puede lograr utilizando el siguiente caso de uso:
- La métrica principal tiene tipo de valor
UINT(se puede usar una métrica trapper), la métrica dependiente tiene tipo de valorTEXT. - No se requieren pasos de preprocesamiento para ambas métricas, principal y dependiente.
- Se debe pasar un valor textual (por ejemplo, "abc") a la métrica principal.
- Como no hay pasos de preprocesamiento que ejecutar, el gestor de preprocesamiento verifica si la métrica principal no está en estado NO SOPORTADO y si el valor está establecido (ambos son verdaderos) y pone en cola la métrica dependiente con el mismo valor que la métrica principal (ya que no hay pasos de preprocesamiento).
- Cuando tanto la métrica principal como la dependiente alcanzan la fase de sincronización del historial, la métrica principal pasa a estar en estado NO SOPORTADO debido al error de conversión de valor (los datos textuales no se pueden convertir a un entero sin signo).
- La métrica principal tiene tipo de valor
Como resultado, la métrica dependiente recibe un valor, mientras que la métrica principal cambia su estado a NO SOPORTADO.
- Una métrica dependiente recibe un valor que no está presente en el historial de la métrica principal. El caso de uso es muy similar al anterior, excepto por el tipo de la métrica principal. Por ejemplo, si se utiliza el tipo
CHARpara la métrica principal, entonces el valor de la métrica principal se truncará en la fase de sincronización del historial, mientras que las métricas dependientes recibirán sus valores a partir del valor inicial (no truncado) de la métrica principal.