
Эскалации
Обзор
Используя эскалации, вы можете создавать пользовательские сценарии для отправки оповещений или выполнения удалённых команд.
С практической точки зрения эскалации означают, что:
- Пользователей можно информировать о новых проблемах незамедлительно.
- Оповещения могут повторяться до решения проблемы.
- Отправка оповещения может быть выполнена с задержкой.
- Оповещения могут эскалироваться другой «более высокой» группе пользователей.
- Удалённые команды могут быть выполнены незамедлительно или когда проблема не будет решена за длительный период времени.
Действия эскалируются на основании шага эскалации. Каждый шаг имеет длительность по времени.
Вы можете задать и длительность по умолчанию, и пользовательскую длительность для каждого отдельного шага. Минимальная длительность одного шага эскалации 60 секунд.
Вы можете начать действия, такие как отправка оповещения или выполнение команд, с любого шага. Шаг первый используется для немедленных действий. Если вы хотите отложить действие, вы можете назначить его на следующий шаг. Для каждого шага можно назначать несколько действий.
Количество шагов эскалаций не ограничено.
Эскалации задаются при настройке операции. Эскалации поддерживаются только для операций на проблемы, но не восстановления.
Различные аспекты поведения эскалации
Рассмотрим, что происходит в разных обстоятельствах, если действие содержит несколько шагов эскалации.
| Situation | Behavior |
|---|---|
| Узел сети, о котором идет речь, переходит в обслуживание после отправки первоначального уведомления о проблеме | В зависимости от настройки Приостанавливать операции для подавленных проблем в конфигурации действия, все оставшиеся шаги эскалации выполняются либо с задержкой, вызванной периодом обслуживания, либо без задержки. Период обслуживания не отменяет операции. |
| Период времени, заданный условием действия Период времени, заканчивается после отправки первоначального уведомления | Все оставшиеся шаги эскалации выполняются. Условие Период времени не может остановить операции; оно влияет на то, когда действия запускаются или не запускаются, а не на операции. |
| Проблема начинается во время обслуживания и продолжается (не решается) после завершения обслуживания | В зависимости от настройки Приостанавливать операции для подавленных проблем в конфигурации действия, все шаги эскалации выполняются либо с момента завершения обслуживания, либо немедленно. |
| Проблема начинается во время обслуживания без данных и продолжается (не решается) после завершения обслуживания | Необходимо дождаться срабатывания триггера, прежде чем будут выполнены все шаги эскалации. |
| Разные эскалации следуют одна за другой с небольшим интервалом и перекрываются | Выполнение каждой новой эскалации отменяет предыдущую эскалацию, но при этом всегда выполняется как минимум один шаг эскалации предыдущей. Это поведение актуально для действий по событиям, которые создаются при КАЖДОЙ оценке проблемы триггера. |
| Во время выполняющейся эскалации (например, при отправке сообщения), на основе любого типа события: - действие отключается На основе события триггера: - триггер отключается - узел сети или элемент данных отключается На основе внутреннего события о триггерах: - триггер отключается На основе внутреннего события об элементах данных/правилах обнаружения низкого уровня: - элемент данных отключается - узел сети отключается |
Сообщение, находящееся в процессе отправки, отправляется, а затем отправляется еще одно сообщение по эскалации. В последующем сообщении в начале текста будет указано сообщение об отмене (NOTE: Escalation canceled) с указанием причины (например, NOTE: Escalation canceled: action '<Action name>' disabled). Таким образом получатель информируется о том, что эскалация отменена и дальнейшие шаги выполняться не будут. Это сообщение отправляется всем, кто уже получил уведомления ранее. Причина отмены также записывается в файл журнала сервера (начиная с Debug Level 3=Warning). Обратите внимание, что сообщение Escalation canceled также отправляется, если операции завершены, но операции восстановления настроены и еще не выполнены. |
| Во время выполняющейся эскалации (например, при отправке сообщения) действие удаляется | Больше никаких сообщений не отправляется. Информация записывается в файл журнала сервера (начиная с Debug Level 3=Warning), например: escalation canceled: action id:334 deleted |
Примеры эскалаций
Пример 1
Отправка повторяющихся оповещений каждые 30 минут (в общей сложности 5 раз) группе «MySQL администраторы». Для настройки:
- На вкладке Операции (Operations) задайте Длительность шага операции по умолчанию (Default operation step duration) значением «30m» (30 минут)
- Укажите шаги эскалаций С (From) «1» До (To) «5»
- Выберите группу «MySQL администраторы» получателями сообщений
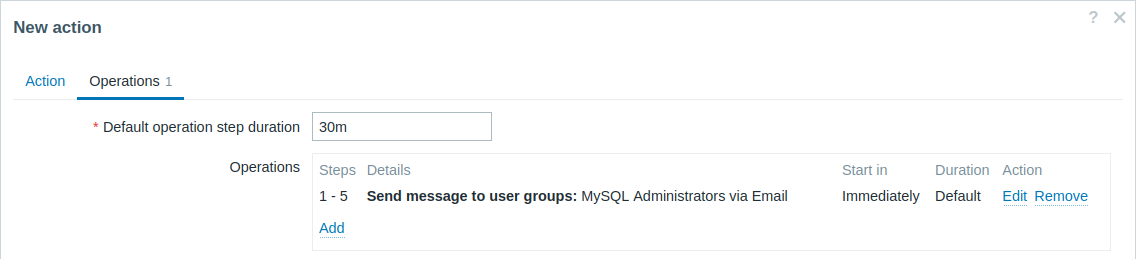
Оповещения будут отправлены через 0:00, 0:30, 1:00, 1:30, 2:00 часов после начала проблемы (если, конечно, проблема не будет решена раньше).
Если проблема решена и сообщение о восстановлении настроено, оно будет отправлено всем тем, кто получил хотя бы одно сообщение в этом сценарии эскалаций.
Если триггер, который вызвал активную эскалацию, был деактивирован, Zabbix отправит информационное сообщение об этом всем, кто уже получил оповещения.
Пример 2
Отправка оповещения с задержкой о давней проблеме. Для настройки:
- На вкладке Операции (Operations) задайте Длительность шага операции по умолчанию (Default operation step duration) значением «10h» (10 часов)
- Укажите шаги эскалации С (From) «2» До (To) «2»
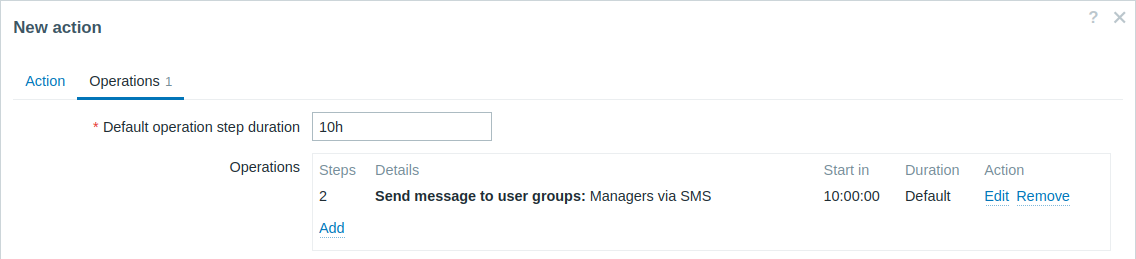
Оповещение будет отправлено только на Шаге 2 сценария эскалации, или через 10 часов после начала проблемы.
Вы можете изменить текст сообщения на что-то вроде «Проблема не решена уже более чем 10 часов».
Пример 3
Эскалирование проблемы Руководству.
В первом примере мы настраивали периодическую отправку сообщений Администраторам MySQL. В данном же случае администраторы получат четыре сообщения до того, как проблема будет эскалирована Менеджеру баз данных. Обратите внимание, что менеджер получит сообщение только в случае, если проблема ещё не подтверждена, предположительно, никто не работает над ней.
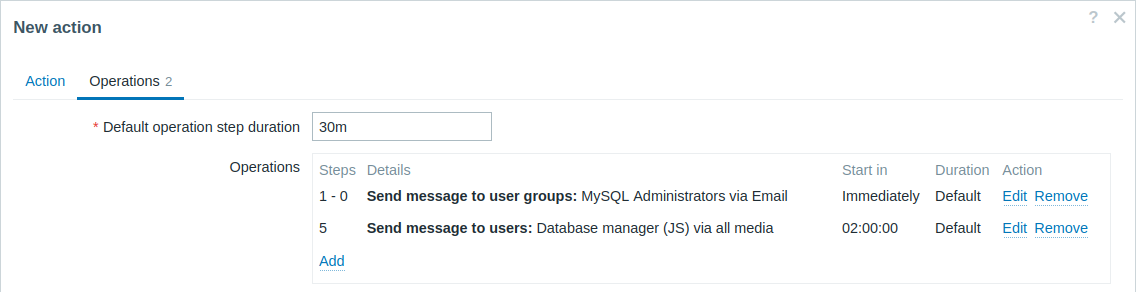
Детали Операции 2:
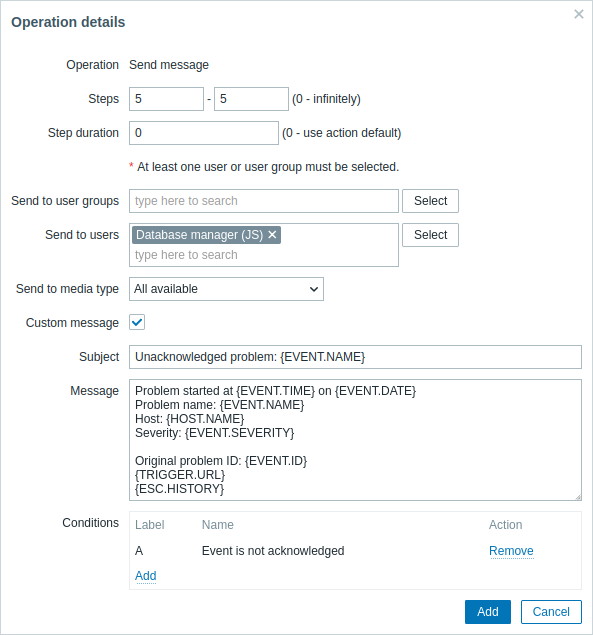
Обратите внимание на использование макроса {ESC.HISTORY} в сообщении. Этот макрос будет содержать информацию обо всех ранее выполненных шагах этой эскалации, таких как отправленные оповещения и выполненные команды.
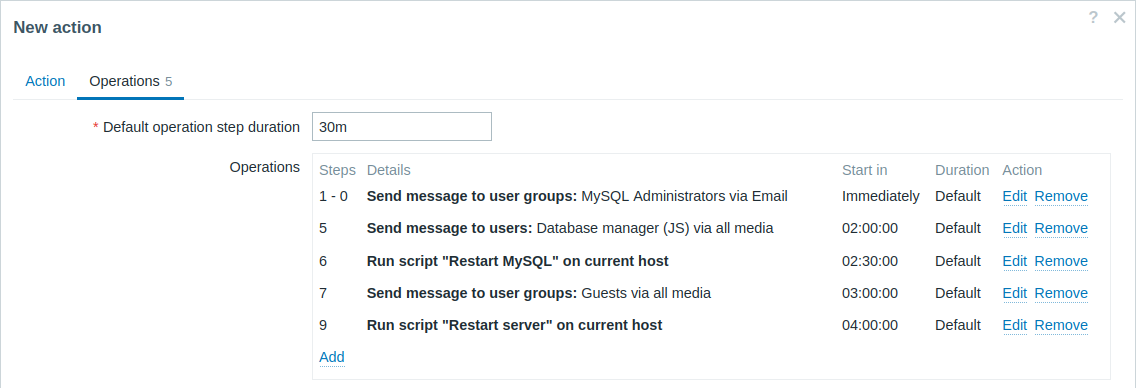
Пример 4
Более сложный сценарий. После нескольких сообщений Администраторам MySQL и эскалации менеджеру, Zabbix попытается перезапустить базу данных MySQL. Это произойдёт, если через 2:30 часа проблема присутствует и не была подтверждена.
Если проблема всё ещё существует, спустя ещё 30 минут Zabbix отправит сообщение всем гостевым пользователям.
Если и это не поможет, спустя ещё час Zabbix перезагрузит сервер с этой базой данных MySQL (вторая удалённая команда), используя IPMI команды.
Пример 5
Эскалация с несколькими операциями, которые имеют перекрывающиеся диапазоны шагов и пользовательские интервалы. Длительность шага операции по умолчанию равна 30 минутам.
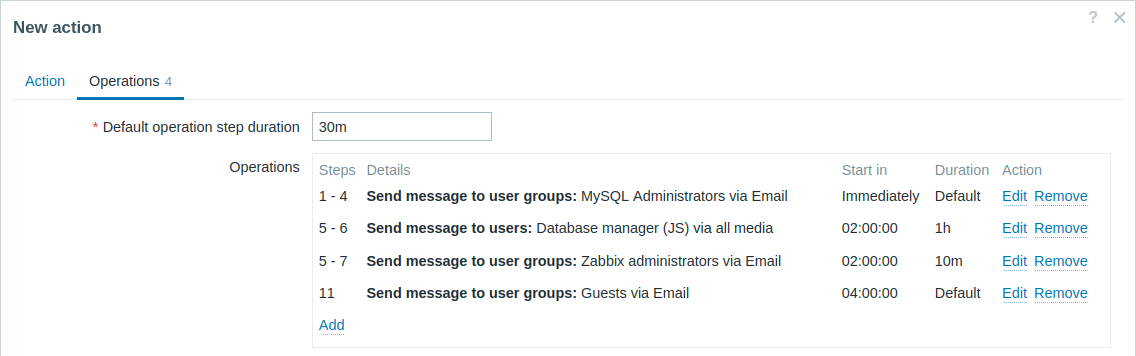
Оповещения будут отправлены в следующем порядке:
- Администраторам MySQL через 0:00, 0:30, 1:00, 1:30 после начала проблемы.
- Менеджеру баз данных через 2:00 и 2:10 (более короткая пользовательская длительность шага в 10 минут, заданная в последующей операции, перекрывает более длительную длительность шага в 1 час, настроенную здесь, как указано в разделе Детали операций для параметра Длительность шага (Step duration), если шаги перекрываются).
- Zabbix администраторам через 2:00, 2:10 и 2:20 после начала проблемы (применяется пользовательская длительность шага, равная 10 минутам).
- Гостевым пользователям через 4:00 часа после начала проблемы (между шагами 8 и 11 имеет силу интервал по умолчанию, равный 30 минутам).