
Escalationi
Panoramica
Con le escalation è possibile creare scenari personalizzati per l'invio di notifiche o l'esecuzione di comandi remoti.
In termini pratici, ciò significa che:
- Gli utenti possono essere informati immediatamente dei nuovi problemi.
- Le notifiche possono essere ripetute finché il problema non viene risolto.
- L'invio di una notifica può essere ritardato.
- Le notifiche possono essere escalate a un altro gruppo di utenti di livello "superiore".
- I comandi remoti possono essere eseguiti immediatamente oppure quando un problema non viene risolto per un lungo periodo.
Le azioni vengono escalate in base al passo di escalation. Ogni passo ha una durata temporale.
È possibile definire sia la durata predefinita sia una durata personalizzata di un singolo passo. La durata minima di un passo di escalation è di 60 secondi.
È possibile avviare azioni, come l'invio di notifiche o l'esecuzione di comandi, da qualsiasi passo. Il primo passo è destinato alle azioni immediate. Se si desidera ritardare un'azione, è possibile assegnarla a un passo successivo. Per ogni passo, possono essere definite diverse azioni.
Il numero di passi di escalation non è limitato.
Le escalation vengono definite durante la configurazione di un'operazione. Le escalation sono supportate solo per le operazioni sui problemi, non per il ripristino.
Aspetti vari del comportamento dell'escalation
Consideriamo cosa accade in diverse circostanze se un action contiene più step di escalation.
| Situation | Behavior |
|---|---|
| The host in question goes into maintenance after the initial problem notification is sent | A seconda dell'impostazione Pause operations for suppressed problems nella configurazione dell'action, tutti gli step di escalation rimanenti vengono eseguiti con un ritardo causato dal periodo di manutenzione oppure senza ritardo. Un periodo di manutenzione non annulla le operations. |
| The time period defined in the Time period action condition ends after the initial notification is sent | Tutti gli step di escalation rimanenti vengono eseguiti. La condizione Time period non può interrompere le operations; influisce su quando le actions vengono avviate o non avviate, non sulle operations. |
| A problem starts during maintenance and continues (is not resolved) after maintenance ends | A seconda dell'impostazione Pause operations for suppressed problems nella configurazione dell'action, tutti gli step di escalation vengono eseguiti a partire dal momento in cui termina la manutenzione oppure immediatamente. |
| A problem starts during a no-data maintenance and continues (is not resolved) after maintenance ends | Deve attendere che il trigger scatti, prima che tutti gli step di escalation vengano eseguiti. |
| Different escalations follow in close succession and overlap | L'esecuzione di ogni nuova escalation sostituisce la precedente, ma almeno uno step di escalation viene sempre eseguito sulla precedente escalation. Questo comportamento è rilevante nelle actions sugli eventi create con OGNI valutazione del problema del trigger. |
| During an escalation in progress (like a message being sent), based on any type of event: - the action is disabled Based on trigger event: - the trigger is disabled - the host or item is disabled Based on internal event about triggers: - the trigger is disabled Based on internal event about items/low-level discovery rules: - the item is disabled - the host is disabled |
Il messaggio in corso viene inviato e poi viene inviato un altro messaggio sull'escalation. Il messaggio successivo avrà il testo di annullamento all'inizio del corpo del messaggio (NOTE: Escalation canceled) con il motivo (ad esempio, NOTE: Escalation canceled: action '<Action name>' disabled). In questo modo il destinatario viene informato che l'escalation è annullata e che non verranno eseguiti altri step. Questo messaggio viene inviato a tutti coloro che hanno ricevuto le notifiche in precedenza. Il motivo dell'annullamento viene anche registrato nel file di log del server (a partire da Debug Level 3=Warning). Si noti che il messaggio Escalation canceled viene inviato anche se le operations sono terminate, ma le recovery operations sono configurate e non sono ancora state eseguite. |
| During an escalation in progress (like a message being sent) the action is deleted | Non vengono inviati altri messaggi. L'informazione viene registrata nel file di log del server (a partire da Debug Level 3=Warning), ad esempio: escalation canceled: action id:334 deleted |
Esempi di escalation
Esempio 1
Invio di una notifica ripetuta una volta ogni 30 minuti (5 volte in totale) a un gruppo "MySQL Administrators". Per configurarlo:
- Nella scheda Operations, impostare Default operation step duration su "30m" (30 minuti).
- Impostare i Steps dell'escalation da "1" a "5".
- Selezionare il gruppo "MySQL Administrators" come destinatario del messaggio.
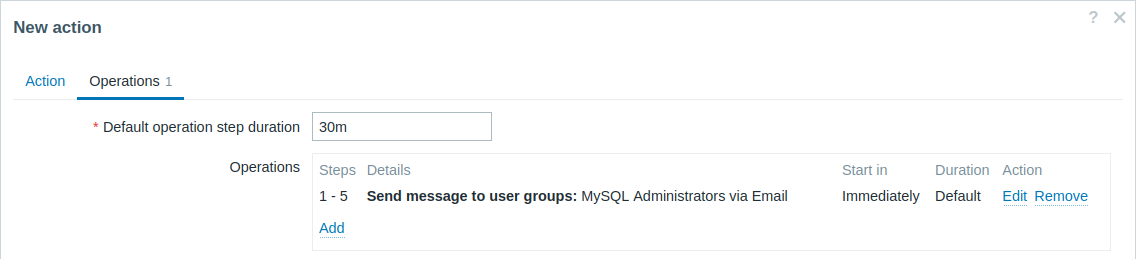
Le notifiche verranno inviate a 0:00, 0:30, 1:00, 1:30, 2:00 ore dopo l'inizio del problema (a meno che, naturalmente, il problema non venga risolto prima).
Se il problema viene risolto ed è configurato un messaggio di ripristino, esso verrà inviato a coloro che hanno ricevuto almeno un messaggio di problema all'interno di questo scenario di escalation.
Se il trigger che ha generato un'escalation attiva viene disabilitato, Zabbix invia un messaggio informativo al riguardo a tutti coloro che hanno già ricevuto notifiche.
Esempio 2
Invio di una notifica ritardata relativa a un problema persistente. Per configurare:
- Nella scheda Operations, impostare Default operation step duration su "10h" (10 ore).
- Impostare gli Steps dell'escalation da "2" a "2".
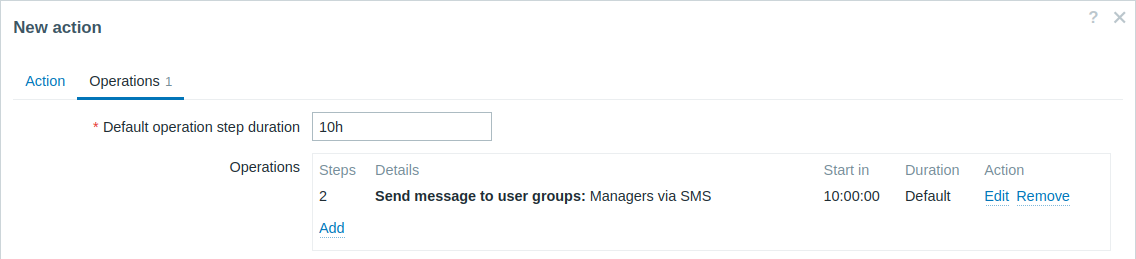
Una notifica verrà inviata solo allo Step 2 dello scenario di escalation, ovvero 10 ore dopo l'inizio del problema.
È possibile personalizzare il testo del messaggio con qualcosa come "Il problema dura da più di 10 ore".
Esempio 3
Escalation del problema al responsabile.
Nel primo esempio sopra abbiamo configurato l'invio periodico di messaggi agli amministratori MySQL. In questo caso, gli amministratori riceveranno quattro messaggi prima che il problema venga escalato al responsabile del database. Si noti che il responsabile riceverà un messaggio solo nel caso in cui il problema non sia ancora stato confermato, presumibilmente perché nessuno ci sta ancora lavorando.
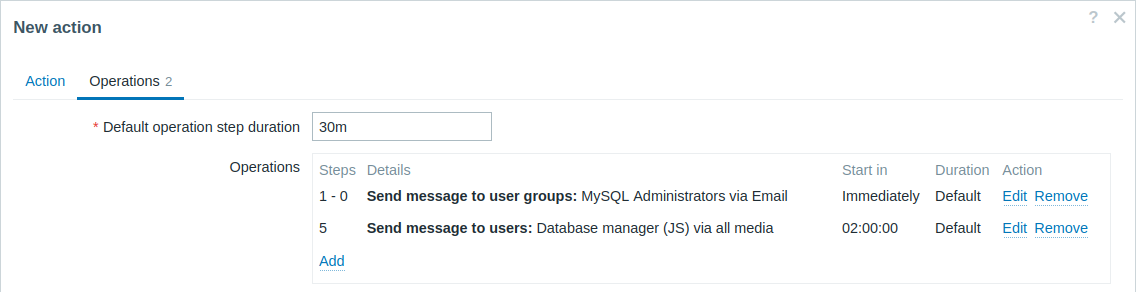
Dettagli dell'operazione 2:
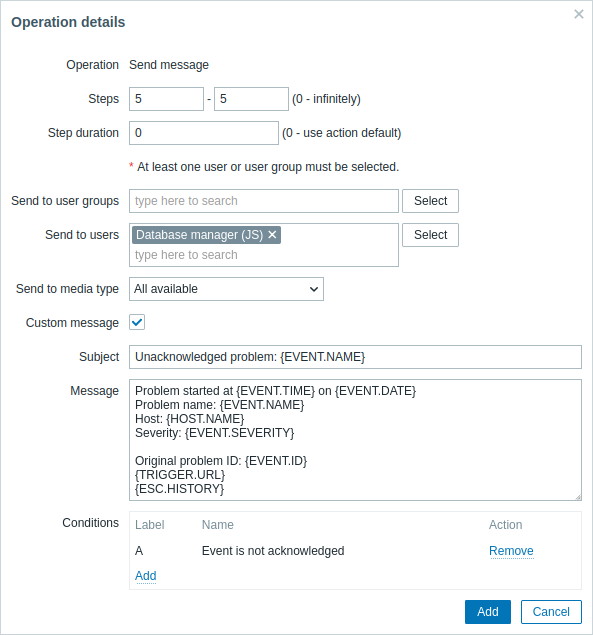
Si noti l'uso della macro {ESC.HISTORY} nel messaggio personalizzato. La macro conterrà informazioni su tutti i passaggi eseguiti in precedenza in questa escalation, come le notifiche inviate e i comandi eseguiti.
Esempio 4
Uno scenario più complesso. Dopo più messaggi agli amministratori MySQL e l'escalation al manager, Zabbix proverà a riavviare il database MySQL. Ciò avverrà se il problema esiste da 2:30 ore e non è stato riconosciuto.
Se il problema esiste ancora, dopo altri 30 minuti Zabbix invierà un messaggio a tutti gli utenti guest.
Se questo non aiuta, dopo un'altra ora Zabbix riavvierà il server con il database MySQL (secondo comando remoto) utilizzando comandi IPMI.
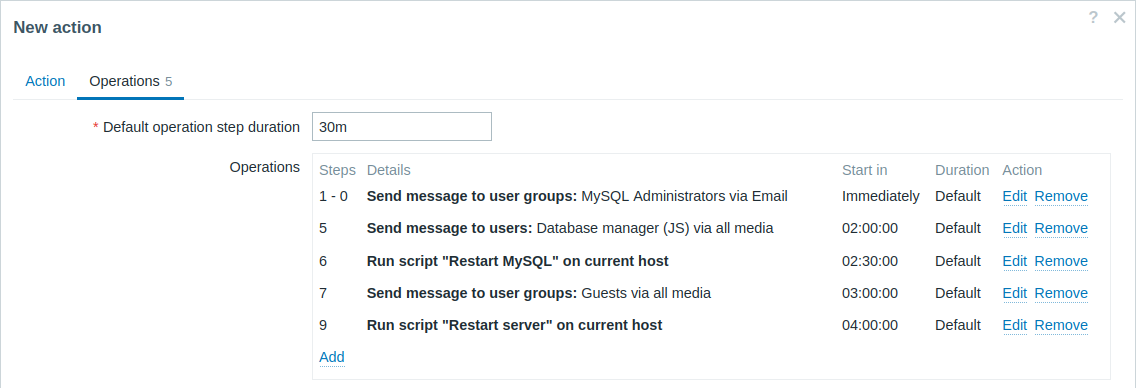
Esempio 5
Un'escalation con diverse operazioni che hanno intervalli di step sovrapposti e intervalli personalizzati. La durata predefinita dello step dell'operazione è di 30 minuti.
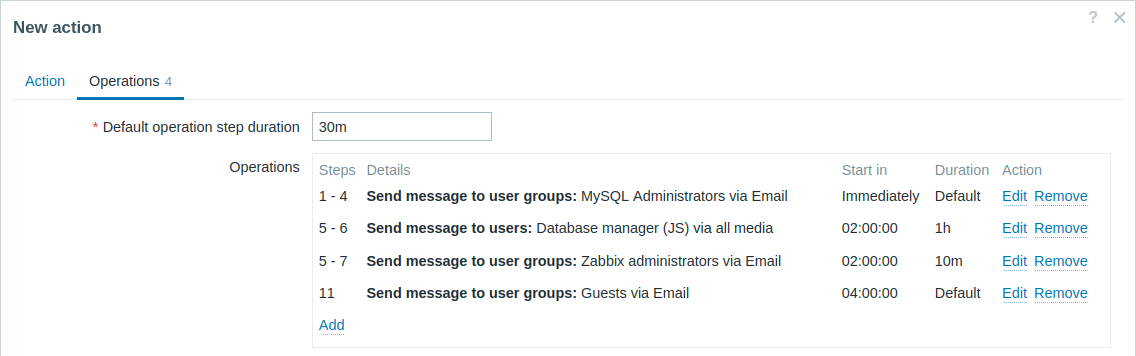
Le notifiche verranno inviate come segue:
- Agli amministratori MySQL a 0:00, 0:30, 1:00 e 1:30 dopo l'inizio del problema.
- Al responsabile del database a 2:00 e 2:10 (la durata personalizzata dello step più breve di 10 minuti definita nell'operazione successiva prevale sulla durata dello step più lunga di 1 ora configurata qui, come descritto in Dettagli dell'operazione per Durata dello step quando gli step si sovrappongono).
- Agli amministratori Zabbix a 2:00, 2:10 e 2:20 dopo l'inizio del problema (viene applicata la durata personalizzata dello step di 10 minuti).
- Agli utenti guest a 4:00 dopo l'inizio del problema (la durata predefinita dello step di 30 minuti entra in vigore tra gli step 8 e 11).