
- 6 Log file monitoring
- Overview
- Configuration
- Important notes
- Extracting matching part of regular expression
- Using maxdelay parameter
- Notes on handling 'copytruncate' log file rotation
- Notes on persistent files for log*[] items
- Actions if communication fails between agent and server
- Handling of regular expression compilation and runtime errors
6 Log file monitoring
Overview
Zabbix can be used for centralized monitoring and analysis of log files with/without log rotation support.
Notifications can be used to warn users when a log file contains certain strings or string patterns.
To monitor a log file you must have:
- Zabbix agent running on the host
- log monitoring item set up
The size limit of a monitored log file depends on large file support.
Configuration
Verify agent parameters
Make sure that in the agent configuration file:
- 'Hostname' parameter matches the host name in the frontend
- Servers in the 'ServerActive' parameter are specified for the processing of active checks
Item configuration
Configure a log monitoring item.
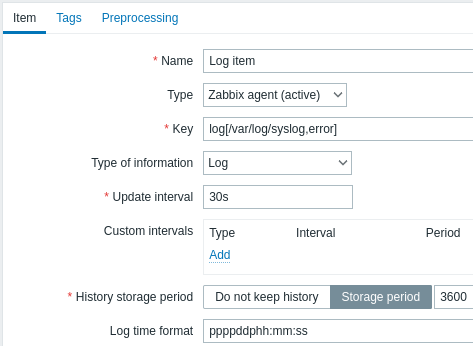
All mandatory input fields are marked with a red asterisk.
Specifically for log monitoring items you enter:
| Type | Select Zabbix agent (active) here. |
| Key | Use one of the following item keys: log[] or logrt[]: These two item keys allow to monitor logs and filter log entries by the content regexp, if present. For example: log[/var/log/syslog,error]. Make sure that the file has read permissions for the 'zabbix' user otherwise the item status will be set to 'unsupported'.log.count[] or logrt.count[]: These two item keys allow to return the number of matching lines only. See supported Zabbix agent item key section for details on using these item keys and their parameters. |
| Type of information | Prefilled automatically: For log[] or logrt[] items - Log;For log.count[] or logrt.count[] items - Numeric (unsigned).If optionally using the output parameter, you may manually select the appropriate type of information other than Log.Note that choosing a non-Log type of information will lead to the loss of local timestamp. |
| Update interval (in sec) | The parameter defines how often Zabbix agent will check for any changes in the log file. Setting it to 1 second will make sure that you get new records as soon as possible. |
| Log time format | In this field you may optionally specify the pattern for parsing the log line timestamp. Supported placeholders: * y: Year (1970-2038) * M: Month (01-12) * d: Day (01-31) * h: Hour (00-23) * m: Minute (00-59) * s: Second (00-59) If left blank, the timestamp will be set to 0 in Unix time, representing January 1, 1970. For example, consider the following line from the Zabbix agent log file: " 23480:20100328:154718.045 Zabbix agent started. Zabbix 1.8.2 (revision 11211)." It begins with six character positions for PID, followed by date, time, and the rest of the message. The log time format for this line would be "pppppp:yyyyMMdd:hhmmss". Note that "p" and ":" characters are placeholders and can be any character except "yMdhms". |
Important notes
- The server and agent keep the trace of a monitored log's size and
last modification time (for logrt) in two counters. Additionally:
- The agent also internally uses inode numbers (on UNIX/GNU/Linux), file indexes (on Microsoft Windows) and MD5 sums of the first 512 log file bytes for improving decisions when logfiles get truncated and rotated.
- On UNIX/GNU/Linux systems it is assumed that the file systems where log files are stored report inode numbers, which can be used to track files.
- On Microsoft Windows Zabbix agent determines the file system
type the log files reside on and uses:
- On NTFS file systems 64-bit file indexes.
- On ReFS file systems (only from Microsoft Windows Server 2012) 128-bit file IDs.
- On file systems where file indexes change (e.g. FAT32, exFAT) a fall-back algorithm is used to take a sensible approach in uncertain conditions when log file rotation results in multiple log files with the same last modification time.
- The inode numbers, file indexes and MD5 sums are internally collected by Zabbix agent. They are not transmitted to Zabbix server and are lost when Zabbix agent is stopped.
- Do not modify the last modification time of log files with 'touch' utility, do not copy a log file with later restoration of the original name (this will change the file inode number). In both cases the file will be counted as different and will be analyzed from the start, which may result in duplicated alerts.
- If there are several matching log files for
logrt[]item and Zabbix agent is following the most recent of them and this most recent log file is deleted, a warning message"there are no files matching "<regexp mask>" in "<directory>"is logged. Zabbix agent ignores log files with modification time less than the most recent modification time seen by the agent for thelogrt[]item being checked.
- The agent starts reading the log file from the point it stopped the previous time.
- The number of bytes already analyzed (the size counter) and last modification time (the time counter) are stored in the Zabbix database and are sent to the agent to make sure the agent starts reading the log file from this point in cases when the agent is just started or has received items which were previously disabled or not supported. However, if the agent has received a non-zero size counter from server, but the logrt[] or logrt.count[] item is unable to find matching files, the size counter is reset to 0 to analyze from the start if the files appear later.
- Whenever the log file becomes smaller than the log size counter known by the agent, the counter is reset to zero and the agent starts reading the log file from the beginning taking the time counter into account.
- If there are several matching files with the same last modification time in the directory, then the agent tries to correctly analyze all log files with the same modification time and avoid skipping data or analyzing the same data twice, although it cannot be guaranteed in all situations. The agent does not assume any particular log file rotation scheme nor determines one. When presented multiple log files with the same last modification time, the agent will process them in a lexicographically descending order. Thus, for some rotation schemes the log files will be analyzed and reported in their original order. For other rotation schemes the original log file order will not be honored, which can lead to reporting matched log file records in altered order (the problem does not happen if log files have different last modification times).
- Zabbix agent processes new records of a log file once per Update interval seconds.
- Zabbix agent does not send more than maxlines of a log file per second. The limit prevents overloading of network and CPU resources and overrides the default value provided by MaxLinesPerSecond parameter in the agent configuration file.
- To find the required string Zabbix will process 10 times more new
lines than set in MaxLinesPerSecond. Thus, for example, if a
log[]orlogrt[]item has Update interval of 1 second, by default the agent will analyze no more than 200 log file records and will send no more than 20 matching records to Zabbix server in one check. By increasing MaxLinesPerSecond in the agent configuration file or setting maxlines parameter in the item key, the limit can be increased up to 10000 analyzed log file records and 1000 matching records sent to Zabbix server in one check. If the Update interval is set to 2 seconds the limits for one check would be set 2 times higher than with Update interval of 1 second. - Additionally, log and log.count values are always limited to 50% of the agent send buffer size, even if there are no non-log values in it. So for the maxlines values to be sent in one connection (and not in several connections), the agent BufferSize parameter must be at least maxlines x 2. Zabbix agent can upload data during log gathering and thus free the buffer, whereas Zabbix agent 2 will stop log gathering until the data is uploaded and the buffer is freed, which is performed asynchronously.
- In the absence of log items all agent buffer size is used for non-log values. When log values come in they replace the older non-log values as needed, up to the designated 50%.
- For log file records longer than 256kB, only the first 256kB are matched against the regular expression and the rest of the record is ignored. However, if Zabbix agent is stopped while it is dealing with a long record the agent internal state is lost and the long record may be analyzed again and differently after the agent is started again.
- Special note for "\" path separators: if file_format is "file\.log", then there should not be a "file" directory, since it is not possible to unambiguously define whether "." is escaped or is the first symbol of the file name.
- Regular expressions for
logrtare supported in filename only, directory regular expression matching is not supported. - On UNIX platforms a
logrt[]item becomes NOTSUPPORTED if a directory where the log files are expected to be found does not exist. - On Microsoft Windows, if a directory does not exist the item will not become NOTSUPPORTED (for example, if directory is misspelled in item key).
- An absence of log files for
logrt[]item does not make it NOTSUPPORTED. Errors of reading log files forlogrt[]item are logged as warnings into Zabbix agent log file but do not make the item NOTSUPPORTED. - Zabbix agent log file can be helpful to find out why a
log[]orlogrt[]item became NOTSUPPORTED. Zabbix can monitor its agent log file, except when at DebugLevel=4 or DebugLevel=5. - Searching for a question mark using a regular expression, e.g.
\?may result in false positives if the text file contains NUL symbols, as those are replaced with "?" by Zabbix to continue processing the line until the newline character.
Extracting matching part of regular expression
Sometimes we may want to extract only the interesting value from a target file instead of returning the whole line when a regular expression match is found.
Since Zabbix 2.2.0, log items have the ability to extract desired values
from matched lines. This is accomplished by the additional output
parameter in log and logrt items.
Using the 'output' parameter allows to indicate the "capturing group" of the match that we may be interested in.
So, for example
log[/path/to/the/file,"large result buffer allocation.*Entries: ([0-9]+)",,,,\1]should allow returning the entry count as found in the content of:
Fr Feb 07 2014 11:07:36.6690 */ Thread Id 1400 (GLEWF) large result
buffer allocation - /Length: 437136/Entries: 5948/Client Ver: >=10/RPC
ID: 41726453/User: AUser/Form: CFG:ServiceLevelAgreementOnly the number will be returned because \1 refers to the first and only capturing group: ([0-9]+).
And, with the ability to extract and return a number, the value can be used to define triggers.
Using maxdelay parameter
The 'maxdelay' parameter in log items allows ignoring some older lines from log files in order to get the most recent lines analyzed within the 'maxdelay' seconds.
Specifying 'maxdelay' > 0 may lead to ignoring important log file records and missed alerts. Use it carefully at your own risk only when necessary.
By default items for log monitoring follow all new lines appearing in
the log files. However, there are applications which in some situations
start writing an enormous number of messages in their log files. For
example, if a database or a DNS server is unavailable, such applications
flood log files with thousands of nearly identical error messages until
normal operation is restored. By default, all those messages will be
dutifully analyzed and matching lines sent to server as configured in
log and logrt items.
Built-in protection against overload consists of a configurable 'maxlines' parameter (protects server from too many incoming matching log lines) and a 10*'maxlines' limit (protects host CPU and I/O from overloading by agent in one check). Still, there are 2 problems with the built-in protection. First, a large number of potentially not-so-informative messages are reported to server and consume space in the database. Second, due to the limited number of lines analyzed per second the agent may lag behind the newest log records for hours. Quite likely, you might prefer to be sooner informed about the current situation in the log files instead of crawling through old records for hours.
The solution to both problems is using the 'maxdelay' parameter. If 'maxdelay' > 0 is specified, during each check the number of processed bytes, the number of remaining bytes and processing time is measured. From these numbers the agent calculates an estimated delay - how many seconds it would take to analyze all remaining records in a log file.
If the delay does not exceed 'maxdelay' then the agent proceeds with analyzing the log file as usual.
If the delay is greater than 'maxdelay' then the agent ignores a chunk of a log file by "jumping" over it to a new estimated position so that the remaining lines could be analyzed within 'maxdelay' seconds.
Note that agent does not even read ignored lines into buffer, but calculates an approximate position to jump to in a file.
The fact of skipping log file lines is logged in the agent log file like this:
14287:20160602:174344.206 item:"logrt["/home/zabbix32/test[0-9].log",ERROR,,1000,,,120.0]"
logfile:"/home/zabbix32/test1.log" skipping 679858 bytes
(from byte 75653115 to byte 76332973) to meet maxdelayThe "to byte" number is approximate because after the "jump" the agent adjusts the position in the file to the beginning of a log line which may be further in the file or earlier.
Depending on how the speed of growing compares with the speed of analyzing the log file you may see no "jumps", rare or often "jumps", large or small "jumps", or even a small "jump" in every check. Fluctuations in the system load and network latency also affect the calculation of delay and hence, "jumping" ahead to keep up with the "maxdelay" parameter.
Setting 'maxdelay' < 'update interval' is not recommended (it may result in frequent small "jumps").
Notes on handling 'copytruncate' log file rotation
logrt with the copytruncate option assumes that different log files
have different records (at least their timestamps are different),
therefore MD5 sums of initial blocks (up to the first 512 bytes) will be
different. Two files with the same MD5 sums of initial blocks means that
one of them is the original, another - a copy.
logrt with the copytruncate option makes effort to correctly process
log file copies without reporting duplicates. However, things like
producing multiple log file copies with the same timestamp, log file
rotation more often than logrt[] item update interval, frequent
restarting of agent are not recommended. The agent tries to handle all
these situations reasonably well, but good results cannot be guaranteed
in all circumstances.
Notes on persistent files for log*[] items
Purpose of persistent files
When Zabbix agent is started it receives a list of active checks from Zabbix server or proxy. For log*[] metrics it receives the processed log size and the modification time for finding where to start log file monitoring from. Depending on the actual log file size and modification time reported by file system the agent decides either to continue log file monitoring from the processed log size or re-analyze the log file from the beginning.
A running agent maintains a larger set of attributes for tracking all monitored log files between checks. This in-memory state is lost when the agent is stopped.
The new optional parameter persistent_dir specifies a directory for storing this state of log[], log.count[], logrt[] or logrt.count[] item in a file. The state of log item is restored from the persistent file after the Zabbix agent is restarted.
The primary use-case is monitoring of log file located on a mirrored file system. Until some moment in time the log file is written to both mirrors. Then mirrors are split. On the active copy the log file is still growing, getting new records. Zabbix agent analyzes it and sends processed logs size and modification time to server. On the passive copy the log file stays the same, well behind the active copy. Later the operating system and Zabbix agent are rebooted from the passive copy. The processed log size and modification time the Zabbix agent receives from server may not be valid for situation on the passive copy. To continue log file monitoring from the place the agent left off at the moment of file system mirror split the agent restores its state from the persistent file.
Agent operation with persistent file
On startup Zabbix agent knows nothing about persistent files. Only after receiving a list of active checks from Zabbix server (proxy) the agent sees that some log items should be backed by persistent files under specified directories.
During agent operation the persistent files are opened for writing (with fopen(filename, "w")) and overwritten with the latest data. The chance of losing persistent file data if the overwriting and file system mirror split happen at the same time is very small, no special handling for it. Writing into persistent file is NOT followed by enforced synchronization to storage media (fsync() is not called).
Overwriting with the latest data is done after successful reporting of matching log file record or metadata (processed log size and modification time) to Zabbix server. That may happen as often as every item check if log file keeps changing.
No special actions during agent shutdown.
After receiving a list of active checks the agent marks obsolete persistent files for removal. A persistent file becomes obsolete if: 1) the corresponding log item is no longer monitored, 2) a log item is reconfigured with a different persistent_dir location than before.
Removing is done with delay 24 hours because log files in NOTSUPPORTED state are not included in the list of active checks but they may become SUPPORTED later and their persistent files will be useful.
If the agent is stopped before 24 hours expire, then the obsolete files will not be deleted as Zabbix agent is not getting info about their location from Zabbix server anymore.
Reconfiguring a log item's persistent_dir back to the old persistent_dir location while the agent is stopped, without deleting the old persistent file by user - will cause restoring the agent state from the old persistent file resulting in missed messages or false alerts.
Naming and location of persistent files
Zabbix agent distinguishes active checks by their keys. For example, logrt[/home/zabbix/test.log] and logrt[/home/zabbix/test.log,] are different items. Modifying the item logrt[/home/zabbix/test.log,,,10] in frontend to logrt[/home/zabbix/test.log,,,20] will result in deleting the item logrt[/home/zabbix/test.log,,,10] from the agent's list of active checks and creating logrt[/home/zabbix/test.log,,,20] item (some attributes are carried across modification in frontend/server, not in agent).
The file name is composed of MD5 sum of item key with item key length appended to reduce possibility of collisions. For example, the state of logrt[/home/zabbix50/test.log,,,,,,,,/home/zabbix50/agent_private] item will be kept in persistent file c963ade4008054813bbc0a650bb8e09266.
Multiple log items can use the same value of persistent_dir.
persistent_dir is specified by taking into account specific file system layouts, mount points and mount options and storage mirroring configuration - the persistent file should be on the same mirrored filesystem as the monitored log file.
If persistent_dir directory cannot be created or does not exist, or access rights for Zabbix agent does not allow to create/write/read/delete files the log item becomes NOTSUPPORTED.
If access rights to persistent storage files are removed during agent operation or other errors occur (e.g. disk full) then errors are logged into the agent log file but the log item does not become NOTSUPPORTED.
Load on I/O
Item's persistent file is updated after successful sending of every batch of data (containing item's data) to server. For example, default 'BufferSize' is 100. If a log item has found 70 matching records then the first 50 records will be sent in one batch, persistent file will be updated, then remaining 20 records will be sent (maybe with some delay when more data is accumulated) in the 2nd batch, and the persistent file will be updated again.
Actions if communication fails between agent and server
Each matching line from log[] and logrt[] item and a result of each
log.count[] and logrt.count[] item check requires a free slot in the
designated 50% area in the agent send buffer. The buffer elements are
regularly sent to server (or proxy) and the buffer slots are free again.
While there are free slots in the designated log area in the agent send buffer and communication fails between agent and server (or proxy) the log monitoring results are accumulated in the send buffer. This helps to mitigate short communication failures.
During longer communication failures all log slots get occupied and the following actions are taken:
log[]andlogrt[]item checks are stopped. When communication is restored and free slots in the buffer are available the checks are resumed from the previous position. No matching lines are lost, they are just reported later.log.count[]andlogrt.count[]checks are stopped ifmaxdelay = 0(default). Behavior is similar tolog[]andlogrt[]items as described above. Note that this can affectlog.count[]andlogrt.count[]results: for example, one check counts 100 matching lines in a log file, but as there are no free slots in the buffer the check is stopped. When communication is restored the agent counts the same 100 matching lines and also 70 new matching lines. The agent now sends count = 170 as if they were found in one check.log.count[]andlogrt.count[]checks withmaxdelay > 0: if there was no "jump" during the check, then behavior is similar to described above. If a "jump" over log file lines took place then the position after "jump" is kept and the counted result is discarded. So, the agent tries to keep up with a growing log file even in case of communication failure.
Handling of regular expression compilation and runtime errors
If a regular expression used in log[], logrt[], log.count[] or logrt.count[] item cannot be compiled by PCRE or PCRE2 library then the item goes into
NOTSUPPORTED state with an error message. To continue monitoring the log item, the regular expression should be fixed.
If the regular expression compiles successfully, but fails at runtime (on some or on all log records), then the log item remains supported and monitoring continues. The runtime error is logged in the Zabbix agent log file (without the log file record).
Note that the logging of regular expression runtime errors is supported since Zabbix 6.4.6.
The logging rate is limited to one runtime error per check to allow Zabbix agent to monitor its own log file. For example, if 10 records are analyzed and 3 records fail with a regexp runtime error, one record is produced in the agent log.
Exception: if MaxLinesPerSecond=1 and update interval=1 (only 1 record is allowed to analyze per check) then regexp runtime errors are not logged.
zabbix_agentd logs the item key in case of a runtime error, zabbix_agent2 logs the item ID to help identify which log item has runtime errors. It is recommended to redesign the regular expression in case of runtime errors.