
Low-level discovery
Overview
Low-level discovery (LLD) automatically discovers entities (e.g., file systems, network interfaces) on a host and creates the corresponding items, triggers, and graphs without manual setup for each.
To use LLD, you create a discovery rule that collects JSON data describing entities, and prototypes (item, trigger, and graph) for each entity.
The JSON returned by the rule must be an array of objects, where each object represents one discovered entity using key-value pairs. For example, a discovery rule with net.if.discovery might return:
[
{"{#IFNAME}": "lo"},
{"{#IFNAME}": "eth0"}
]A corresponding set of items, triggers, and graphs is then created from the prototypes—one per interface (lo and eth0).
If objects contain keys in the {#MACRO} format, those macros are used directly in prototypes. If not, or if additional/custom macros are required, macros can be defined manually and mapped to JSON fields using JSONPath.
LLD can also create hosts (e.g., for virtual machines discovered on a hypervisor) and supports nested discovery rules for multi-level discovery.
Entities that are no longer discovered can be automatically disabled or deleted.
Configuring low-level discovery
We will illustrate low-level discovery based on an example of file system discovery.
To configure the discovery, do the following:
- Go to Data collection > Templates or Hosts.
- Click Discovery in the row of an appropriate template/host.

- Click Create discovery rule in the upper-right corner of the screen.
- Fill in the discovery rule form with the required details.
Discovery rule
The discovery rule form contains five tabs, representing, from left to right, the data flow during discovery:
- Discovery rule - specifies, most importantly, the built-in item or custom script to retrieve discovery data.
- Preprocessing - applies some preprocessing to the discovered data.
- LLD macros - allows to extract some macro values to use in discovered items, triggers, etc.
- Filters - allows to filter the discovered values.
- Overrides - allows to modify items, triggers, graphs or host prototypes when applying to specific discovered objects.
The Discovery rule tab contains the item key to use for discovery (as well as some general discovery rule attributes):
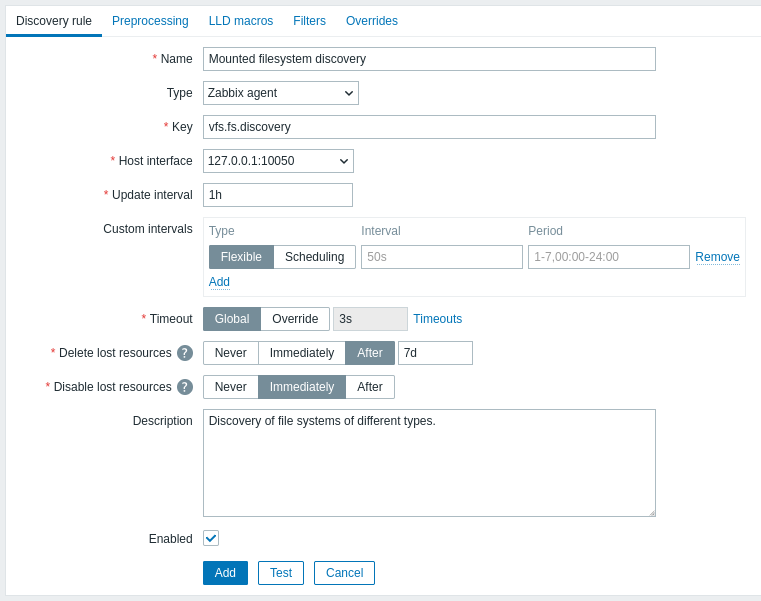
All mandatory input fields are marked with a red asterisk.
| Parameter | Description |
|---|---|
| Name | Name of discovery rule. |
| Type | The type of check to perform discovery. In this example we are using a Zabbix agent item type. The discovery rule can also be a dependent item, depending on a regular item. It cannot depend on another discovery rule. For a dependent item, select the respective type (Dependent item) and specify the master item in the 'Master item' field. The master item must exist. |
| Key | Enter the discovery item key (up to 2048 characters). For example, you may use the built-in "vfs.fs.discovery" item key to return a JSON string with the list of file systems present on the computer, their types and mount options. Note that another option for filesystem discovery is using discovery results by the "vfs.fs.get" agent key (see example). |
| Update interval | This field specifies how often Zabbix performs discovery. In the beginning, when you are just setting up file system discovery, you might wish to set it to a small interval, but once you know it works you can set it to 30 minutes or more, because file systems usually do not change very often. Time suffixes are supported, e.g., 30s, 1m, 2h, 1d. User macros are supported. Note: The update interval can only be set to '0' if custom intervals exist with a non-zero value. If set to '0', and a custom interval (flexible or scheduled) exists with a non-zero value, the item will be polled during the custom interval duration. New discovery rules will be checked within 60 seconds of their creation, unless they have Scheduling or Flexible update interval and the Update interval is set to 0. Note that for an existing discovery rule the discovery can be performed immediately by pushing the Execute now button. |
| Custom intervals | You can create custom rules for checking the item: Flexible - create an exception to the Update interval (interval with different frequency) Scheduling - create a custom polling schedule. For detailed information see Custom intervals. |
| Timeout | Set the discovery check timeout. Select the timeout option: Global - proxy/global timeout is used (displayed in the grayed out Timeout field); Override - custom timeout is used (set in the Timeout field; allowed range: 1 - 600s). Time suffixes, e.g., 30s, 1m, and user macros are supported. Clicking the Timeouts link allows you to configure proxy timeouts or global timeouts (if a proxy is not used). Note that the Timeouts link is visible only to users of Super admin type with permissions to Administration > General or Administration > Proxies frontend sections. |
| Delete lost resources | Specify how soon the discovered entity will be deleted once its discovery status becomes "Not discovered anymore": Never - it will not be deleted; Immediately - it will be deleted immediately; After - it will be deleted after the specified time period. The value must be greater than Disable lost resources value. Time suffixes are supported, e.g., 2h, 1d. User macros are supported. Note: Using "Immediately" is not recommended, since just wrongly editing the filter may end up in the entity being deleted with all the historical data. Note that manually disabled resources will not be deleted by low-level discovery. |
| Disable lost resources | Specify how soon the discovered entity will be disabled once its discovery status becomes "Not discovered anymore": Never - it will not be disabled; Immediately - it will be disabled immediately; After - it will be disabled after the specified time period. The value should be greater than the discovery rule update interval. Note that automatically disabled resources will become enabled again, if re-discovered by low-level discovery. Manually disabled resources will not become enabled again if re-discovered. This field is not displayed if Delete lost resources is set to "Immediately". Time suffixes are supported, e.g., 2h, 1d. User macros are supported. |
| Description | Enter a description. |
| Enabled | If checked, the rule will be processed. |
Discovery rule history is not preserved.
Preprocessing
The Preprocessing tab allows to define transformation rules to apply to the result of discovery. One or several transformations are possible in this step. Transformations are executed in the order in which they are defined. All preprocessing is done by Zabbix server.
See also:
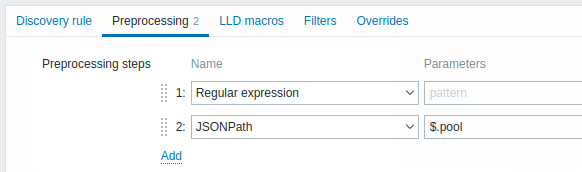
| Type | ||
|---|---|---|
| Transformation | Description | |
| Text | ||
| Regular expression | Match the received value to the <pattern> regular expression and replace value with the extracted <output>. The regular expression supports extraction of maximum 10 captured groups with the \N sequence. Parameters: pattern - regular expression output - output formatting template. An \N (where N=1…9) escape sequence is replaced with the Nth matched group. A \0 escape sequence is replaced with the matched text. If you mark the Custom on fail checkbox, it is possible to specify custom error-handling options: either to discard the value, set a specified value or set a specified error message. |
|
| Replace | Find the search string and replace it with another (or nothing). All occurrences of the search string will be replaced. Parameters: search string - the string to find and replace, case-sensitive (required) replacement - the string to replace the search string with. The replacement string may also be empty effectively allowing to delete the search string when found. It is possible to use escape sequences to search for or replace line breaks, carriage return, tabs and spaces "\n \r \t \s"; backslash can be escaped as "\\" and escape sequences can be escaped as "\\n". Escaping of line breaks, carriage return, tabs is automatically done during low-level discovery. |
|
| Structured data | ||
| JSONPath | Extract value or fragment from JSON data using JSONPath functionality. If you mark the Custom on fail checkbox, it is possible to specify custom error-handling options: either to discard the value, set a specified value or set a specified error message. |
|
| XML XPath | Extract value or fragment from XML data using XPath functionality. For this option to work, Zabbix server must be compiled with libxml support. Examples: number(/document/item/value) will extract 10 from <document><item><value>10</value></item></document>number(/document/item/@attribute) will extract 10 from <document><item attribute="10"></item></document>/document/item will extract <item><value>10</value></item> from <document><item><value>10</value></item></document>Note that namespaces are not supported. If you mark the Custom on fail checkbox, it is possible to specify custom error-handling options: either to discard the value, set a specified value or set a specified error message. |
|
| CSV to JSON | Convert CSV file data into JSON format. For more information, see: CSV to JSON preprocessing. |
|
| XML to JSON | Convert data in XML format to JSON. For more information, see: Serialization rules. If you mark the Custom on fail checkbox, it is possible to specify custom error-handling options: either to discard the value, set a specified value or set a specified error message. |
|
| SNMP | ||
| SNMP walk value | Extract value by the specified OID/MIB name and apply formatting options: Unchanged - return Hex-STRING as unescaped hex string (note that display hints are still applied); UTF-8 from Hex-STRING - convert Hex-STRING to UTF-8 string; MAC from Hex-STRING - convert Hex-STRING to MAC address string (which will have ' ' replaced by ':');Integer from BITS - convert the first 8 bytes of a bit string expressed as a sequence of hex characters (e.g., "1A 2B 3C 4D") into a 64-bit unsigned integer. In bit strings longer than 8 bytes, consequent bytes will be ignored. If you mark the Custom on fail checkbox, it is possible to specify custom error-handling options: either to discard the value, set a specified value or set a specified error message. |
|
| SNMP walk to JSON | Convert SNMP values to JSON. Specify a field name in the JSON and the corresponding SNMP OID path. Field values will be populated by values in the specified SNMP OID path. You may use this preprocessing step for SNMP OID discovery. Similar value formatting options as in the SNMP walk value step are available. If you mark the Custom on fail checkbox, it is possible to specify custom error-handling options: either to discard the value, set a specified value or set a specified error message. |
|
| SNMP get value | Apply formatting options to the SNMP get value: UTF-8 from Hex-STRING - convert Hex-STRING to UTF-8 string; MAC from Hex-STRING - convert Hex-STRING to MAC address string (which will have ' ' replaced by ':');Integer from BITS - convert the first 8 bytes of a bit string expressed as a sequence of hex characters (e.g., "1A 2B 3C 4D") into a 64-bit unsigned integer. In bit strings longer than 8 bytes, consequent bytes will be ignored. If you mark the Custom on fail checkbox, it is possible to specify custom error-handling options: either to discard the value, set a specified value or set a specified error message. |
|
| Custom scripts | ||
| JavaScript | Enter JavaScript code in the modal editor that opens when clicking in the parameter field or on the pencil icon next to it. Note that available JavaScript length depends on the database used. For more information, see: Javascript preprocessing |
|
| Validation | ||
| Does not match regular expression | Specify a regular expression that a value must not match. E.g., Error:(.*?)\.If you mark the Custom on fail checkbox, it is possible to specify custom error-handling options: either to discard the value, set a specified value or set a specified error message. |
|
| Check for error in JSON | Check for an application-level error message located at JSONPath. Stop processing if succeeded and message is not empty; otherwise continue processing with the value that was before this preprocessing step. Note that these external service errors are reported to user as is, without adding preprocessing step information. E.g., $.errors. If a JSON like {"errors":"e1"} is received, the next preprocessing step will not be executed.If you mark the Custom on fail checkbox, it is possible to specify custom error-handling options: either to discard the value, set a specified value or set a specified error message. |
|
| Check for error in XML | Check for an application-level error message located at Xpath. Stop processing if succeeded and message is not empty; otherwise continue processing with the value that was before this preprocessing step. Note that these external service errors are reported to user as is, without adding preprocessing step information. No error will be reported in case of failing to parse invalid XML. If you mark the Custom on fail checkbox, it is possible to specify custom error-handling options: either to discard the value, set a specified value or set a specified error message. |
|
| Matches regular expression | Specify a regular expression that a value must match. If you mark the Custom on fail checkbox, it is possible to specify custom error-handling options: either to discard the value, set a specified value or set a specified error message. |
|
| Throttling | ||
| Discard unchanged with heartbeat | Discard a value if it has not changed within the defined time period (in seconds). Positive integer values are supported to specify the seconds (minimum - 1 second). Time suffixes can be used in this field (e.g., 30s, 1m, 2h, 1d). User macros and low-level discovery macros can be used in this field. Only one throttling option can be specified for a discovery item. E.g., 1m. If identical text is passed into this rule twice within 60 seconds, it will be discarded.Note: Changing item prototypes does not reset throttling. Throttling is reset only when preprocessing steps are changed. |
|
| Prometheus | ||
| Prometheus to JSON | Convert required Prometheus metrics to JSON. See Prometheus checks for more details. |
|
Note that if the discovery rule has been applied to the host via template then the content of this tab is read-only.
Custom macros
The LLD macros tab allows you to specify custom LLD macros when the returned JSON does not already contain keys in the {#MACRO} format.
For example, the vfs.fs.get agent item key returns JSON filesystem data without any predefined LLD macros.
Here, you define the macros manually and map them to values in the JSON using JSONPath expressions:
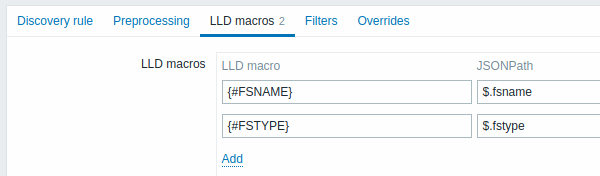
| Parameter | Description |
|---|---|
| LLD macro | Name of the LLD macro in the format {#MACRO}. |
| JSONPath | Expression that defines which value to extract from each discovered entity in the JSON array. For example, $.foo extracts "bar" and "baz" from[{"foo":"bar"}, {"foo":"baz"}].JSONPath supports both dot and bracket notation. Bracket notation must be used for keys containing special characters or Unicode, e.g., $['unicode + special chars #1']['unicode + special chars #2']. |
The discovery rule must return a JSON array at the root ($.).
For backward compatibility, a JSON object containing a single "data" array is also accepted. In this case, the "data" array is automatically unwrapped:
{"data":[{"foo":"bar"}, {"foo":"baz"}]}Filter
A filter can be used to generate real items, triggers, and graphs only for entities that match the criteria. The Filters tab contains discovery rule filter definitions allowing to filter discovery values:
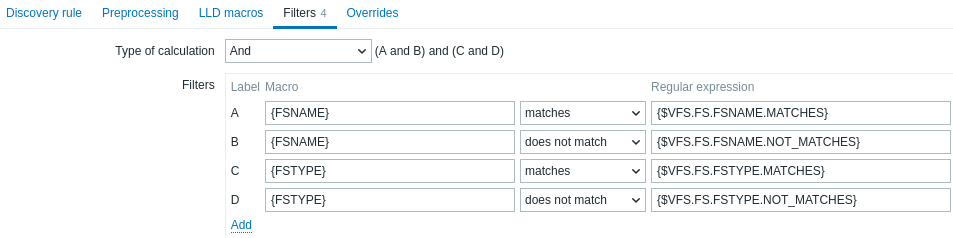
| Parameter | Description |
|---|---|
| Type of calculation | The following options for calculating filters are available: And - all filters must be passed; Or - enough if one filter is passed; And/Or - uses And with different macro names and Or with the same macro name; Custom expression - offers the possibility to define a custom calculation of filters. The formula must include all filters in the list. Limited to 255 symbols. |
| Filters | The following filter condition operators are available: matches, does not match, exists, does not exist. Matches and does not match operators expect a Perl Compatible Regular Expression (PCRE). You can enter a regular expression or reference a global regular expression in the Regular expression field. Exists and does not exist operators allow to filter entities based on the presence or absence of the specified LLD macro in the response. Note that if a macro from the filter is missing in the response, the found entity will be ignored, unless a "does not exist" condition is specified for this macro. A warning will be displayed, if the absence of a macro affects the expression result. For example, if {#B} is missing in:{#A} matches 1 and {#B} matches 2 - will give a warning{#A} matches 1 or {#B} matches 2 - no warning. |
For example, if you are only interested in the C:, D:, and E: file systems, you can put {#FSNAME} into the Macro field and ^C|^D|^E into the Regular expression field.
Filtering is also possible by file system types using the {#FSTYPE} macro (e.g., ^ext|^reiserfs) and by drive types (supported only by Windows agent) using the {#FSDRIVETYPE} macro (e.g., fixed).
In order to test a regular expression you can use grep -E, for example:
for f in ext2 nfs reiserfs smbfs;
do echo $f | grep -E '^ext|^reiserfs' || echo "SKIP: $f";
doneA mistake or a typo in the regular expression used in the LLD rule (for example, an incorrect "File systems for discovery" regular expression) may cause deletion of thousands of configuration elements, historical values, and events for many hosts.
Zabbix database in MySQL must be created as case-sensitive if file system names that differ only by case are to be discovered correctly.
Override
The Overrides tab allows setting rules to modify the list of item, trigger, graph, host, and discovery prototypes or their attributes for discovered objects that meet given criteria.
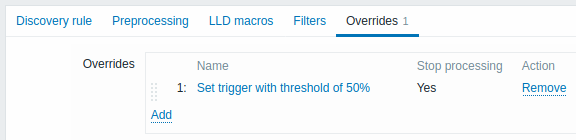
Overrides (if any) are displayed in a reorderable drag-and-drop list and executed in the order in which they are defined. To configure details of a new override, click  in the Overrides block.
To edit an existing override, click the override name.
A popup window will open allowing to edit the override rule details.
in the Overrides block.
To edit an existing override, click the override name.
A popup window will open allowing to edit the override rule details.
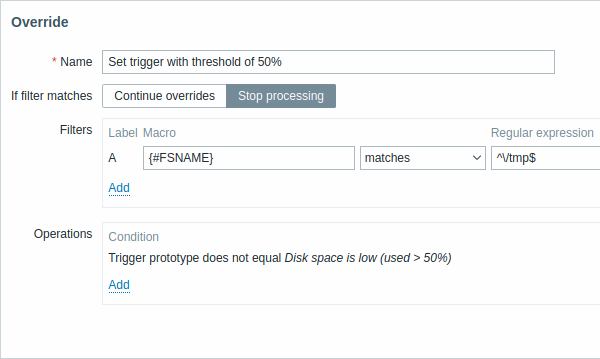
All mandatory parameters are marked with red asterisks.
| Parameter | Description |
|---|---|
| Name | A unique (per LLD rule) override name. |
| If filter matches | Defines whether next overrides should be processed when filter conditions are met: Continue overrides - subsequent overrides will be processed. Stop processing - operations from preceding (if any) and this override will be executed, subsequent overrides will be ignored for matched LLD rows. |
| Filters | Determines to which discovered entities the override should be applied. Override filters are processed after discovery rule filters and have the same functionality. |
| Operations | Override operations are displayed with these details: Condition - an object type and a condition to be met for the object name; for example: Trigger prototype does not equal Disk space is low (used > 50%). Actions - links for editing and removing an operation are displayed. |
Configuring an operation
To configure details of a new operation, click in the Operations block.
To edit an existing operation, click  next to the operation.
A popup window where you can edit the operation details will open.
next to the operation.
A popup window where you can edit the operation details will open.
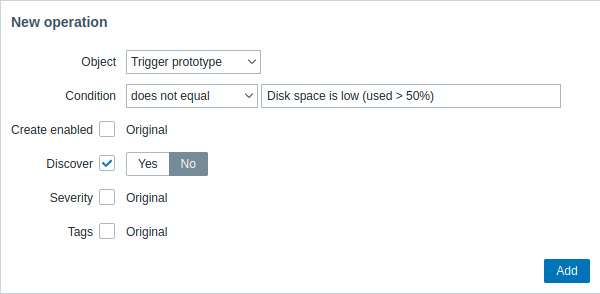
| Parameter | Description | ||
|---|---|---|---|
| Object | Five types of objects are available: Item prototype Trigger prototype Graph prototype Host prototype Discovery prototype |
||
| Condition | Allows filtering entities to which the operation should be applied. | ||
| Operator | Supported operators: equals - apply to this prototype does not equal - apply to all prototypes, except this contains - apply, if prototype name contains this string does not contain - apply, if prototype name does not contain this string matches - apply, if prototype name matches regular expression does not match - apply, if prototype name does not match regular expression |
||
| Pattern | A regular expression or a string to search for. | ||
| Object: Item prototype | |||
| Create enabled | When the checkbox is marked, the buttons will appear, allowing to override original item prototype settings: Yes - the item will be added in an enabled state. No - the item will be added to a discovered entity but in a disabled state. |
||
| Discover | When the checkbox is marked, the buttons will appear, allowing to override original item prototype settings: Yes - the item will be added. No - the item will not be added. |
||
| Update interval | When the checkbox is marked, two options will appear, allowing to set different interval for the item: Delay - Item update interval. User macros, LLD macros, and time suffixes (e.g., 30s, 1m, 2h, 1d) are supported. Should be set to 0 if Custom interval is used. Custom interval - click to specify flexible/scheduling intervals. For detailed information see Custom intervals. |
||
| History | When the checkbox is marked, the buttons will appear, allowing different history storage period to be set for the item: Do not store - if selected, the history will not be stored. Store up to - if selected, an input field for specifying storage period will appear to the right. User macros and LLD macros are supported. |
||
| Trends | When the checkbox is marked, the buttons will appear, allowing different trend storage period to be set for the item: Do not store - if selected, the trends will not be stored. Store up to - if selected, an input field for specifying storage period will appear to the right. User macros and LLD macros are supported. |
||
| Tags | When the checkbox is marked, a new block will appear, allowing to specify tag-value pairs. User macros and LLD macros are supported. These tags will be appended to the tags specified in the item prototype, even if the tag names match. |
||
| Object: Trigger prototype | |||
| Create enabled | When the checkbox is marked, the buttons will appear, allowing to override original trigger prototype settings: Yes - the trigger will be added in an enabled state. No - the trigger will be added to a discovered entity, but in a disabled state. |
||
| Discover | When the checkbox is marked, the buttons will appear, allowing to override original trigger prototype settings: Yes - the trigger will be added. No - the trigger will not be added. |
||
| Severity | When the checkbox is marked, trigger severity buttons will appear, allowing to modify trigger severity. | ||
| Tags | When the checkbox is marked, a new block will appear, allowing to specify tag-value pairs. User macros and LLD macros are supported. These tags will be appended to the tags specified in the trigger prototype, even if the tag names match. |
||
| Object: Graph prototype | |||
| Discover | When the checkbox is marked, the buttons will appear, allowing to override original graph prototype settings: Yes - the graph will be added. No - the graph will not be added. |
||
| Object: Host prototype | |||
| Create enabled | When the checkbox is marked, the buttons will appear, allowing to override original host prototype settings: Yes - the host will be created in an enabled state. No - the host will be created in a disabled state. |
||
| Discover | When the checkbox is marked, the buttons will appear, allowing to override original host prototype settings: Yes - the host will be discovered. No - the host will not be discovered. |
||
| Link templates | When the checkbox is marked, an input field for specifying templates will appear. Start typing the template name or click Select next to the field and select templates from the list in a popup window. Templates from this override are added to all templates already linked to the host prototype. |
||
| Tags | When the checkbox is marked, a new block will appear, allowing to specify tag-value pairs. User macros and LLD macros are supported. These tags will be appended to the tags specified in the host prototype, even if the tag names match. |
||
| Host inventory | When the checkbox is marked, the buttons will appear, allowing to select different inventory mode for the host prototype: Disabled - do not populate host inventory Manual - provide details manually Automated - auto-fill host inventory data based on collected metrics. |
||
| Object: Discovery prototype | |||
| Create enabled | When the checkbox is marked, the buttons will appear, allowing to override original discovery prototype settings: Yes - the discovery rule will be added in an enabled state. No - the discovery rule will be added in a disabled state. |
||
| Discover | When the checkbox is marked, the buttons will appear, allowing to override original discovery prototype settings: Yes - the discovery rule will be added. No - the discovery rule will not be added. |
||
| Update interval | When the checkbox is marked, two options will appear, allowing to set different interval for the discovery rule: Delay - Rule update interval. User macros, LLD macros, and time suffixes (e.g., 30s, 1m, 2h, 1d) are supported. Should be set to 0 if Custom interval is used. Custom interval - click to specify flexible/scheduling intervals. For detailed information see Custom intervals. |
||
Form buttons
Buttons at the bottom of the form allow to perform several operations.
 |
Add a discovery rule. This button is only available for new discovery rules. |
 |
Update the properties of a discovery rule. This button is only available for existing discovery rules. |
 |
Create another discovery rule based on the properties of the current discovery rule. |
 |
Perform discovery based on the discovery rule immediately. The discovery rule must already exist. See more details. Note that when performing discovery immediately, configuration cache is not updated, thus the result will not reflect very recent changes to discovery rule configuration. |
 |
Test the discovery rule configuration. Use this button to verify the configuration settings (such as connectivity and parameter correctness) without permanently applying any changes. |
 |
Delete the discovery rule. |
 |
Cancel the editing of discovery rule properties. |
Discovered entities
The screenshots below illustrate how discovered items, triggers, and graphs look like in the host's configuration. Discovered entities are prefixed with an orange link to a discovery rule they come from.
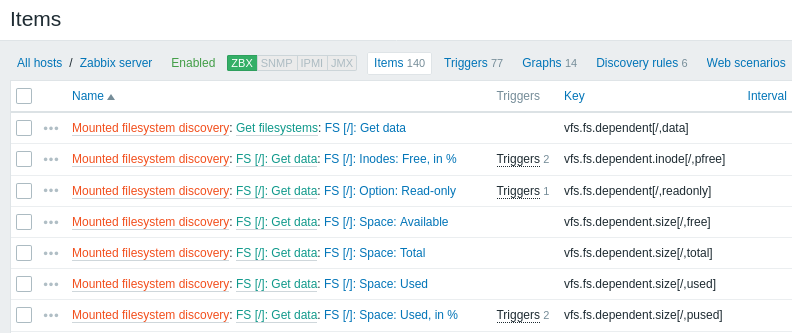
Note that discovered entities will not be created in case there are already existing entities with the same uniqueness criteria, for example, an item with the same key or graph with the same name. An error message is displayed in this case in the frontend that the low-level discovery rule could not create certain entities. The discovery rule itself, however, will not turn unsupported because some entity could not be created and had to be skipped. The discovery rule will go on creating/updating other entities.
If a discovered entity (host, file system, interface, etc) stops being discovered (or does not pass the filter anymore) the entities that were created based on it may be automatically disabled and eventually deleted.
Lost resources may be automatically disabled based on the value of the Disable lost resources parameter. This affects lost hosts, items and triggers.
Lost resources may be automatically deleted based on the value of the Delete lost resources parameter. This affects lost hosts, host groups, items, triggers, and graphs.
When discovered entities become 'Not discovered anymore', a lifetime indicator is displayed in the entity list. Move your mouse pointer over it and a message will be displayed indicating its status details.

If entities were marked for deletion, but were not deleted at the expected time (disabled discovery rule or item host), they will be deleted the next time the discovery rule is processed.
Entities containing other entities, which are marked for deletion, will not update if changed on the discovery rule level. For example, LLD-based triggers will not update if they contain items that are marked for deletion.
Other types of discovery
More detail and how-tos on other types of out-of-the-box discovery is available in the following sections:
- discovery of network interfaces
- discovery of CPUs and CPU cores
- discovery of SNMP OIDs
- discovery of JMX objects;
- discovery using ODBC SQL queries
- discovery of Windows services
- discovery of host interfaces in Zabbix
For more detail on the JSON format for discovery items and an example of how to implement your own file system discoverer as a Perl script, see creating custom LLD rules.