
3 Descoberta de baixo nível
Visão geral
A descoberta de baixo nível (LLD) fornece uma maneira de criar automaticamente itens, triggers e gráficos para diferentes entidades em um host. Por exemplo, o Zabbix pode começar automaticamente a monitorar sistemas de arquivos ou interfaces de rede na sua máquina, sem a necessidade de criar itens manualmente para cada sistema de arquivos ou interface de rede. A LLD também pode criar hosts, por exemplo, para preencher máquinas virtuais descobertas em um hipervisor, e regras de descoberta aninhadas, permitindo descoberta em vários níveis. Além disso, é possível configurar o Zabbix para remover automaticamente entidades desnecessárias com base nos resultados reais da descoberta executada periodicamente.
Um usuário pode definir seus próprios tipos de descoberta, desde que sigam um protocolo JSON específico.
A arquitetura geral do processo de descoberta é a seguinte.
Primeiro, um usuário cria uma regra de descoberta em Coleta de dados > Templates, na coluna Discovery. Uma regra de descoberta consiste em (1) um item que descobre as entidades necessárias (por exemplo, sistemas de arquivos ou interfaces de rede) e (2) protótipos de itens, triggers e gráficos que devem ser criados com base no valor desse item.
Um item que descobre as entidades necessárias é como um item regular visto em outros lugares: o server solicita a um Zabbix agent (ou qualquer que seja o tipo definido para o item) um valor desse item, e o agent responde com um valor textual. A diferença é que o valor retornado pelo agent deve conter uma lista de entidades descobertas em formato JSON. Embora os detalhes desse formato sejam importantes apenas para implementadores de verificações de descoberta personalizadas, é necessário saber que o valor retornado contém uma lista de pares macro → valor. Por exemplo, o item "net.if.discovery" pode retornar dois pares: "{#IFNAME}" → "lo" e "{#IFNAME}" → "eth0".
Essas macros são usadas em nomes, chaves e outros campos de protótipo, onde são então substituídas pelos valores recebidos para criar itens, triggers, gráficos ou até mesmo hosts reais para cada entidade descoberta. Veja a lista completa de opções para usar macros de LLD.
Quando o server recebe um valor para um item de descoberta, ele analisa os pares macro → valor e, para cada par, gera itens, triggers e gráficos reais com base em seus protótipos. No exemplo com "net.if.discovery" acima, o server geraria um conjunto de itens, triggers e gráficos para a interface de loopback "lo" e outro conjunto para a interface "eth0".
Observe que, desde o Zabbix 4.2, o formato do JSON retornado pelas regras de descoberta de baixo nível foi alterado. Não se espera mais que o JSON contenha o objeto "data". A descoberta de baixo nível agora aceitará um JSON normal contendo um array, para dar suporte a novos recursos, como o pré-processamento do valor do item e caminhos personalizados para valores de macros de descoberta de baixo nível em um documento JSON.
As chaves de descoberta integradas foram atualizadas para retornar um array de linhas LLD na raiz do documento JSON.
O Zabbix extrairá automaticamente uma macro e um valor se um campo do array usar a sintaxe {#MACRO} como chave.
Quaisquer novas verificações de descoberta nativas usarão a nova sintaxe sem os elementos "data".
Ao processar um valor de descoberta de baixo nível, primeiro a raiz é localizada (array em $. ou $.data).
Embora o elemento "data" tenha sido removido de todos os itens nativos relacionados à descoberta, por compatibilidade retroativa o Zabbix ainda aceitará a notação JSON com um elemento "data", embora seu uso não seja recomendado.
Se o JSON contiver um objeto com apenas um elemento array "data", então ele extrairá automaticamente o conteúdo do elemento usando JSONPath $.data.
A descoberta de baixo nível agora aceita macros LLD opcionais definidas pelo usuário com um caminho personalizado especificado na sintaxe JSONPath.
Como resultado das alterações acima, agents mais novos não poderão mais funcionar com um server Zabbix mais antigo.
Veja também: Entidades descobertas
Configurando a descoberta de baixo nível
Vamos ilustrar a descoberta de baixo nível com base em um exemplo de descoberta de sistema de arquivos.
Para configurar a descoberta, faça o seguinte:
- Acesse: Data collection > Templates ou Hosts.
- Clique em Discovery na linha do template/host apropriado.

- Clique em Create discovery rule no canto superior direito da tela.
- Preencha o formulário da regra de descoberta com os detalhes necessários.
Regra de descoberta
O formulário de regra de descoberta contém cinco abas, representando, da esquerda para a direita, o fluxo de dados durante a descoberta:
- Regra de descoberta - especifica, principalmente, o item integrado ou script personalizado para obter os dados de descoberta.
- Pré-processamento - aplica algum pré-processamento aos dados descobertos.
- Macros LLD - permite extrair alguns valores de macro para uso em itens, triggers etc. descobertos.
- Filtros - permite filtrar os valores descobertos.
- Substituições - permite modificar itens, triggers, gráficos ou protótipos de host ao aplicar a objetos específicos descobertos.
A aba Regra de descoberta contém a chave do item a ser usada para descoberta (bem como alguns atributos gerais da regra de descoberta):
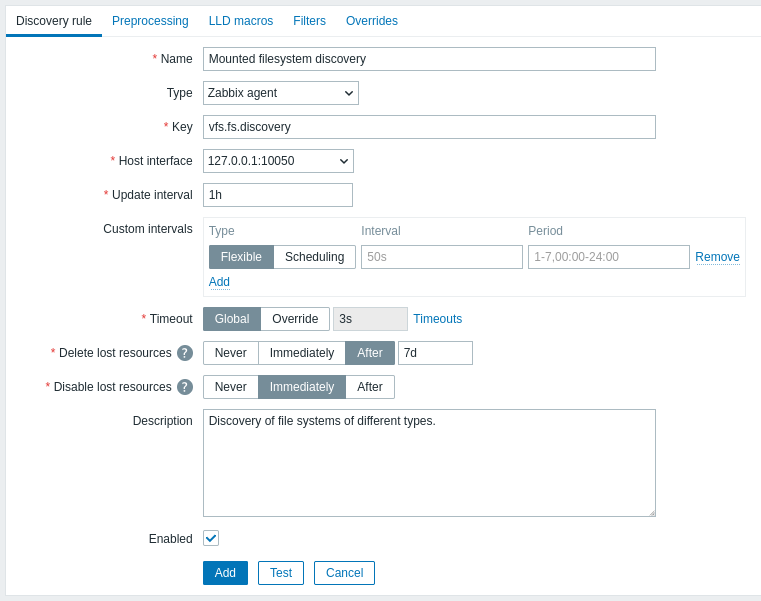
Todos os campos de entrada obrigatórios são marcados com um asterisco vermelho.
| Parameter | Description |
|---|---|
| Name | Nome da regra de descoberta. |
| Type | O tipo de verificação para realizar a descoberta. Neste exemplo, estamos usando um tipo de item Zabbix agent. A regra de descoberta também pode ser um item dependente, dependendo de um item comum. Ela não pode depender de outra regra de descoberta. Para um item dependente, selecione o respectivo tipo (Item dependente) e especifique o item mestre no campo 'Master item'. O item mestre deve existir. |
| Key | Insira a chave do item de descoberta (até 2048 caracteres). Por exemplo, você pode usar a chave de item integrada "vfs.fs.discovery" para retornar uma string JSON com a lista de sistemas de arquivos presentes no computador, seus tipos e opções de montagem. Observe que outra opção para descoberta de sistemas de arquivos é usar resultados de descoberta pela chave de agent "vfs.fs.get" (consulte o exemplo). |
| Update interval | Este campo especifica com que frequência o Zabbix realiza a descoberta. No início, quando você está apenas configurando a descoberta de sistemas de arquivos, talvez queira definir um intervalo pequeno, mas, quando souber que está funcionando, poderá defini-lo como 30 minutos ou mais, porque sistemas de arquivos normalmente não mudam com muita frequência. Sufixos de tempo são suportados, por exemplo, 30s, 1m, 2h, 1d. Macros de usuário são suportadas. Nota: O intervalo de atualização só pode ser definido como '0' se existirem intervalos personalizados com um valor diferente de zero. Se definido como '0', e existir um intervalo personalizado (flexível ou agendado) com um valor diferente de zero, o item será consultado durante a duração do intervalo personalizado. Novas regras de descoberta serão verificadas em até 60 segundos após sua criação, a menos que tenham Agendamento ou Intervalo de atualização flexível e o Update interval esteja definido como 0. Observe que, para uma regra de descoberta existente, a descoberta pode ser executada imediatamente pressionando o botão Executar agora. |
| Custom intervals | Você pode criar regras personalizadas para verificar o item: Flexível - cria uma exceção ao Update interval (intervalo com frequência diferente) Agendamento - cria um agendamento de polling personalizado. Para informações detalhadas, consulte Intervalos personalizados. |
| Timeout | Defina o timeout da verificação de descoberta. Selecione a opção de timeout: Global - o timeout global/do proxy é usado (exibido no campo Timeout acinzentado); Substituir - um timeout personalizado é usado (definido no campo Timeout; intervalo permitido: 1 - 600s). Sufixos de tempo, por exemplo, 30s, 1m, e macros de usuário são suportados. Clicar no link Timeouts permite configurar timeouts de proxy ou timeouts globais (se um proxy não for usado). Observe que o link Timeouts é visível apenas para usuários do tipo Super admin com permissões para as seções do frontend Administration > General ou Administration > Proxies. |
| Delete lost resources | Especifique em quanto tempo a entidade descoberta será excluída quando seu status de descoberta se tornar "Não descoberto mais": Nunca - não será excluída; Imediatamente - será excluída imediatamente; Após - será excluída após o período especificado. O valor deve ser maior que o valor de Disable lost resources. Sufixos de tempo são suportados, por exemplo, 2h, 1d. Macros de usuário são suportadas. Nota: O uso de "Imediatamente" não é recomendado, pois uma edição incorreta do filtro pode fazer com que a entidade seja excluída junto com todos os dados históricos. Observe que recursos desabilitados manualmente não serão excluídos pela descoberta de baixo nível. |
| Disable lost resources | Especifique em quanto tempo a entidade descoberta será desabilitada quando seu status de descoberta se tornar "Não descoberto mais": Nunca - não será desabilitada; Imediatamente - será desabilitada imediatamente; Após - será desabilitada após o período especificado. O valor deve ser maior que o intervalo de atualização da regra de descoberta. Observe que recursos desabilitados automaticamente serão habilitados novamente se forem redescobertos pela descoberta de baixo nível. Recursos desabilitados manualmente não serão habilitados novamente se forem redescobertos. Este campo não é exibido se Delete lost resources estiver definido como "Imediatamente". Sufixos de tempo são suportados, por exemplo, 2h, 1d. Macros de usuário são suportadas. |
| Description | Insira uma descrição. |
| Enabled | Se marcado, a regra será processada. |
O histórico da regra de descoberta não é preservado.
Preprocessamento
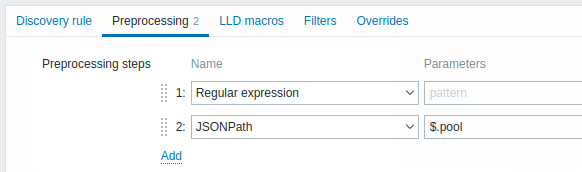
A aba Preprocessamento permite definir regras de transformação a serem aplicadas ao resultado da descoberta. Uma ou várias transformações são possíveis nesta etapa. As transformações são executadas na ordem em que são definidas. Todo o preprocessamento é feito pelo Zabbix server.
Veja também:
| Tipo | ||
|---|---|---|
| Transformação | Descrição | |
| Texto | ||
| Expressão regular | Corresponde o valor recebido à expressão regular <pattern> e substitui o valor pelo <output> extraído. A expressão regular suporta a extração de no máximo 10 grupos capturados com a sequência \N. Parâmetros: pattern - expressão regular output - modelo de formatação da saída. Uma sequência de escape \N (onde N=1…9) é substituída pelo N-ésimo grupo correspondente. Uma sequência de escape \0 é substituída pelo texto correspondente. Se você marcar a caixa de seleção Custom on fail, é possível especificar opções personalizadas de tratamento de erro: descartar o valor, definir um valor especificado ou definir uma mensagem de erro especificada. |
|
| Substituir | Localiza a string de pesquisa e a substitui por outra (ou por nada). Todas as ocorrências da string de pesquisa serão substituídas. Parâmetros: search string - a string a ser localizada e substituída, com distinção entre maiúsculas e minúsculas (obrigatório) replacement - a string que substituirá a string de pesquisa. A string de substituição também pode estar vazia, permitindo efetivamente excluir a string de pesquisa quando encontrada. É possível usar sequências de escape para pesquisar ou substituir quebras de linha, retorno de carro, tabulações e espaços "\n \r \t \s"; a barra invertida pode ser escapada como "\\" e sequências de escape podem ser escapadas como "\\n". O escape de quebras de linha, retorno de carro e tabulações é feito automaticamente durante a descoberta em baixo nível. |
|
| Dados estruturados | ||
| JSONPath | Extrai valor ou fragmento de dados JSON usando a funcionalidade JSONPath. Se você marcar a caixa de seleção Custom on fail, é possível especificar opções personalizadas de tratamento de erro: descartar o valor, definir um valor especificado ou definir uma mensagem de erro especificada. |
|
| XML XPath | Extrai valor ou fragmento de dados XML usando a funcionalidade XPath. Para que esta opção funcione, o Zabbix server deve ser compilado com suporte a libxml. Exemplos: number(/document/item/value) extrairá 10 de <document><item><value>10</value></item></document>number(/document/item/@attribute) extrairá 10 de <document><item attribute="10"></item></document>/document/item extrairá <item><value>10</value></item> de <document><item><value>10</value></item></document>Observe que namespaces não são suportados. Se você marcar a caixa de seleção Custom on fail, é possível especificar opções personalizadas de tratamento de erro: descartar o valor, definir um valor especificado ou definir uma mensagem de erro especificada. |
|
| CSV para JSON | Converte dados de arquivo CSV para o formato JSON. Para mais informações, consulte: Preprocessamento de CSV para JSON. |
|
| XML para JSON | Converte dados no formato XML para JSON. Para mais informações, consulte: Regras de serialização. Se você marcar a caixa de seleção Custom on fail, é possível especificar opções personalizadas de tratamento de erro: descartar o valor, definir um valor especificado ou definir uma mensagem de erro especificada. |
|
| SNMP | ||
| Valor de SNMP walk | Extrai o valor pelo OID/nome MIB especificado e aplica opções de formatação: Unchanged - retorna Hex-STRING como string hexadecimal sem escape (observe que as dicas de exibição ainda são aplicadas); UTF-8 from Hex-STRING - converte Hex-STRING em string UTF-8; MAC from Hex-STRING - converte Hex-STRING em string de endereço MAC (na qual ' ' será substituído por ':');Integer from BITS - converte os primeiros 8 bytes de uma string de bits expressa como uma sequência de caracteres hexadecimais (por exemplo, "1A 2B 3C 4D") em um inteiro sem sinal de 64 bits. Em strings de bits maiores que 8 bytes, os bytes subsequentes serão ignorados. Se você marcar a caixa de seleção Custom on fail, é possível especificar opções personalizadas de tratamento de erro: descartar o valor, definir um valor especificado ou definir uma mensagem de erro especificada. |
|
| SNMP walk para JSON | Converte valores SNMP para JSON. Especifique um nome de campo no JSON e o caminho OID SNMP correspondente. Os valores dos campos serão preenchidos pelos valores no caminho OID SNMP especificado. Você pode usar esta etapa de preprocessamento para descoberta de OID SNMP. Estão disponíveis opções de formatação de valor semelhantes às da etapa Valor de SNMP walk. Se você marcar a caixa de seleção Custom on fail, é possível especificar opções personalizadas de tratamento de erro: descartar o valor, definir um valor especificado ou definir uma mensagem de erro especificada. |
|
| Valor de SNMP get | Aplica opções de formatação ao valor de SNMP get: UTF-8 from Hex-STRING - converte Hex-STRING em string UTF-8; MAC from Hex-STRING - converte Hex-STRING em string de endereço MAC (na qual ' ' será substituído por ':');Integer from BITS - converte os primeiros 8 bytes de uma string de bits expressa como uma sequência de caracteres hexadecimais (por exemplo, "1A 2B 3C 4D") em um inteiro sem sinal de 64 bits. Em strings de bits maiores que 8 bytes, os bytes subsequentes serão ignorados. Se você marcar a caixa de seleção Custom on fail, é possível especificar opções personalizadas de tratamento de erro: descartar o valor, definir um valor especificado ou definir uma mensagem de erro especificada. |
|
| Scripts personalizados | ||
| JavaScript | Insira o código JavaScript no editor modal que é aberto ao clicar no campo de parâmetro ou no ícone de lápis ao lado dele. Observe que o tamanho disponível do JavaScript depende do banco de dados usado. Para mais informações, consulte: Preprocessamento em Javascript |
|
| Validação | ||
| Não corresponde à expressão regular | Especifique uma expressão regular à qual um valor não deve corresponder. Por exemplo, Error:(.*?)\.Se você marcar a caixa de seleção Custom on fail, é possível especificar opções personalizadas de tratamento de erro: descartar o valor, definir um valor especificado ou definir uma mensagem de erro especificada. |
|
| Verificar erro em JSON | Verifica se há uma mensagem de erro no nível da aplicação localizada em JSONPath. Interrompe o processamento se for bem-sucedido e a mensagem não estiver vazia; caso contrário, continua o processamento com o valor que estava antes desta etapa de preprocessamento. Observe que esses erros de serviços externos são informados ao usuário como estão, sem adicionar informações da etapa de preprocessamento. Por exemplo, $.errors. Se um JSON como {"errors":"e1"} for recebido, a próxima etapa de preprocessamento não será executada.Se você marcar a caixa de seleção Custom on fail, é possível especificar opções personalizadas de tratamento de erro: descartar o valor, definir um valor especificado ou definir uma mensagem de erro especificada. |
|
| Verificar erro em XML | Verifica se há uma mensagem de erro no nível da aplicação localizada em Xpath. Interrompe o processamento se for bem-sucedido e a mensagem não estiver vazia; caso contrário, continua o processamento com o valor que estava antes desta etapa de preprocessamento. Observe que esses erros de serviços externos são informados ao usuário como estão, sem adicionar informações da etapa de preprocessamento. Nenhum erro será informado em caso de falha ao analisar XML inválido. Se você marcar a caixa de seleção Custom on fail, é possível especificar opções personalizadas de tratamento de erro: descartar o valor, definir um valor especificado ou definir uma mensagem de erro especificada. |
|
| Corresponde à expressão regular | Especifique uma expressão regular à qual um valor deve corresponder. Se você marcar a caixa de seleção Custom on fail, é possível especificar opções personalizadas de tratamento de erro: descartar o valor, definir um valor especificado ou definir uma mensagem de erro especificada. |
|
| Limitação de taxa | ||
| Descartar inalterado com heartbeat | Descarta um valor se ele não tiver mudado dentro do período de tempo definido (em segundos). São aceitos valores inteiros positivos para especificar os segundos (mínimo - 1 segundo). Sufixos de tempo podem ser usados neste campo (por exemplo, 30s, 1m, 2h, 1d). Macros de usuário e macros de descoberta em baixo nível podem ser usadas neste campo. Apenas uma opção de limitação de taxa pode ser especificada para um item de descoberta. Por exemplo, 1m. Se o mesmo texto for passado para esta regra duas vezes em 60 segundos, ele será descartado.Observação: alterar protótipos de item não redefine a limitação de taxa. A limitação de taxa é redefinida somente quando as etapas de preprocessamento são alteradas. |
|
| Prometheus | ||
| Prometheus para JSON | Converte as métricas Prometheus necessárias para JSON. Consulte Verificações Prometheus para mais detalhes. |
|
Observe que, se a regra de descoberta tiver sido aplicada ao host por meio de template, o conteúdo desta aba será somente leitura.
Macros personalizadas
A aba Macros LLD permite especificar macros de descoberta de baixo nível personalizadas.
Macros personalizadas são úteis em casos em que o JSON retornado não possui as macros necessárias já definidas. Então, por exemplo:
- A chave nativa
vfs.fs.discoverypara descoberta de sistemas de arquivos retorna um JSON com algumas macros LLD pré-definidas, como {#FSNAME}, {#FSTYPE}. Essas macros podem ser usadas diretamente em protótipos de item, trigger (veja as seções subsequentes da página); não é necessário definir macros personalizadas; - O item agent
vfs.fs.gettambém retorna um JSON com dados do sistema de arquivos, mas sem nenhuma macro LLD pré-definida. Neste caso, você pode definir as macros manualmente e mapeá-las para os valores no JSON usando JSONPath:
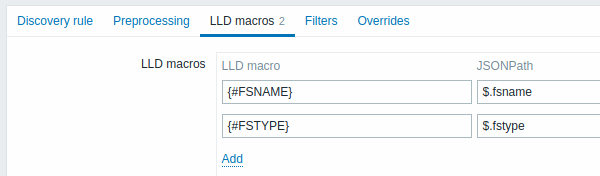
Os valores extraídos podem ser usados em itens, triggers, etc. descobertos. Observe que os valores serão extraídos do resultado da descoberta e de quaisquer etapas de pré-processamento até o momento.
| Parâmetro | Descrição |
|---|---|
| Macro LLD | Nome da macro de descoberta de baixo nível, usando a seguinte sintaxe: {#MACRO}. |
| JSONPath | Caminho usado para extrair o valor da macro LLD de uma linha LLD, usando a sintaxe JSONPath. Os valores extraídos do JSON retornado são usados para substituir as macros LLD nos campos de protótipo de item, trigger, etc. O JSONPath pode ser especificado usando a notação de ponto ou a notação de colchetes. A notação de colchetes deve ser usada em caso de caracteres especiais e Unicode, como $['unicode + special chars #1']['unicode + special chars #2'].Por exemplo, $.foo irá extrair "bar" e "baz" deste JSON: [{"foo":"bar"}, {"foo":"baz"}]Observe que $.foo também irá extrair "bar" e "baz" deste JSON: {"data":[{"foo":"bar"}, {"foo":"baz"}]} porque um único objeto "data" é processado automaticamente (para compatibilidade retroativa com a implementação de descoberta de baixo nível em versões do Zabbix anteriores à 4.2). |
Filtro
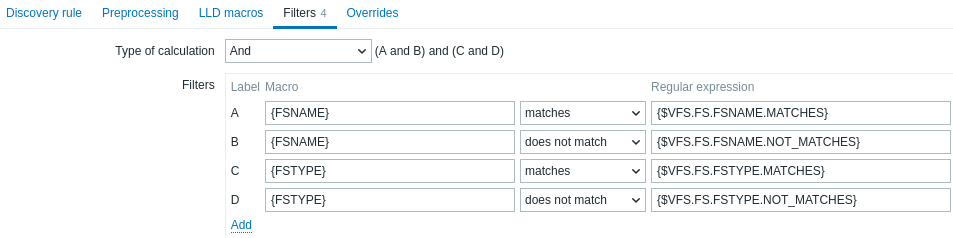
Um filtro pode ser usado para gerar itens, triggers e gráficos reais apenas para entidades que correspondam aos critérios. A aba Filtros contém definições de filtro da regra de descoberta, permitindo filtrar valores de descoberta:
| Parâmetro | Descrição |
|---|---|
| Tipo de cálculo | As seguintes opções para calcular filtros estão disponíveis: E - todos os filtros devem ser aprovados; Ou - basta que um filtro seja aprovado; E/Ou - usa E com nomes de macro diferentes e Ou com o mesmo nome de macro; Expressão personalizada - oferece a possibilidade de definir um cálculo personalizado de filtros. A fórmula deve incluir todos os filtros da lista. Limitado a 255 símbolos. |
| Filtros | Os seguintes operadores de condição de filtro estão disponíveis: corresponde, não corresponde, existe, não existe. Os operadores corresponde e não corresponde esperam uma Expressão Regular Compatível com Perl (PCRE). Por exemplo, se você estiver interessado apenas nos sistemas de arquivos C:, D: e E:, você pode colocar {#FSNAME} em "Macro" e a expressão regular "\C|\D|\E" no campo de texto "Expressão regular". A filtragem também é possível por tipos de sistema de arquivos usando a macro {#FSTYPE} (por exemplo, "\ext|\reiserfs") e por tipos de unidade (suportado apenas pelo agent do Windows) usando a macro {#FSDRIVETYPE} (por exemplo, "fixed"). Você pode inserir uma expressão regular ou referenciar uma expressão regular global no campo "Expressão regular". Para testar uma expressão regular, você pode usar "grep -E", por exemplo: ````for f in ext2 nfs reiserfs smbfs; do echo $f | grep -E 'ext|^reiserfs' || echo "SKIP: $f"; done```` Os operadores existe e não existe permitem filtrar entidades com base na presença ou ausência da macro LLD especificada na resposta. Observe que, se uma macro do filtro estiver ausente na resposta, a entidade encontrada será ignorada, a menos que uma condição "não existe" seja especificada para essa macro. Um aviso será exibido se a ausência de uma macro afetar o resultado da expressão. Por exemplo, se {#B} estiver ausente em: {#A} corresponde a 1 e {#B} corresponde a 2 - exibirá um aviso {#A} corresponde a 1 ou {#B} corresponde a 2 - sem aviso |
Um erro ou um erro de digitação na expressão regular usada na regra LLD (por exemplo, uma expressão regular incorreta em "Sistemas de arquivos para descoberta") pode causar a exclusão de milhares de elementos de configuração, valores históricos e eventos para muitos hosts.
O banco de dados Zabbix no MySQL deve ser criado como sensível a maiúsculas e minúsculas se nomes de sistemas de arquivos que diferem apenas por maiúsculas/minúsculas precisarem ser descobertos corretamente.
Override
A guia Overrides permite definir regras para modificar a lista de protótipos de item, trigger, gráfico, host e descoberta, ou seus atributos, para objetos descobertos que atendam a critérios específicos.
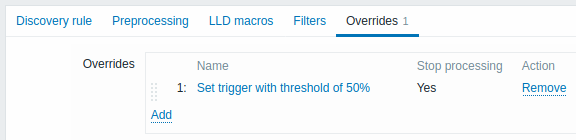
Os overrides, se houver, são exibidos em uma lista reordenável de arrastar e soltar e executados na ordem em que são definidos. To configure details of a new override, click  in the Overrides block.
Para editar um override existente, clique no nome do override.
Uma janela pop-up será aberta, permitindo editar os detalhes da regra de override.
in the Overrides block.
Para editar um override existente, clique no nome do override.
Uma janela pop-up será aberta, permitindo editar os detalhes da regra de override.
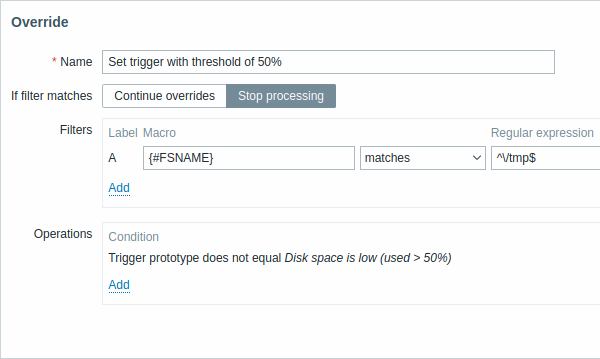
Todos os parâmetros obrigatórios são marcados com asteriscos vermelhos.
| Parameter | Description |
|---|---|
| Name | Um nome de override exclusivo (por regra de LLD). |
| If filter matches | Define se os próximos overrides devem ser processados quando as condições do filtro forem atendidas: Continue overrides - os overrides subsequentes serão processados. Stop processing - as operações dos overrides anteriores (se houver) e deste override serão executadas, e os overrides subsequentes serão ignorados para as linhas de LLD correspondentes. |
| Filters | Determina a quais entidades descobertas o override deve ser aplicado. Os filtros de override são processados após os filtros da regra de descoberta e têm a mesma funcionalidade. |
| Operations | As operações de override são exibidas com estes detalhes: Condition - um tipo de objeto e uma condição que deve ser atendida para o nome do objeto; por exemplo: Trigger prototype does not equal Disk space is low (used > 50%). Actions - são exibidos links para editar e remover uma operação. |
Configurando uma operação
Para configurar os detalhes de uma nova operação, clique em no bloco Operations.
Para editar uma operação existente, clique em  ao lado da operação.
Uma janela pop-up onde você pode editar os detalhes da operação será aberta.
ao lado da operação.
Uma janela pop-up onde você pode editar os detalhes da operação será aberta.
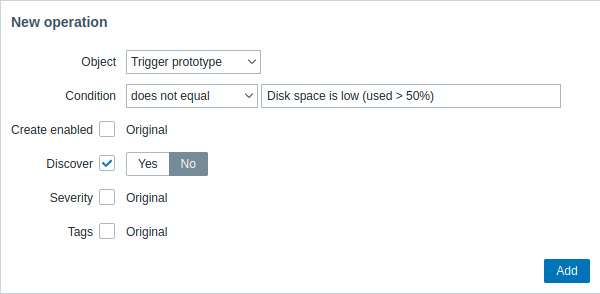
| Parameter | Description | ||
|---|---|---|---|
| Object | Cinco tipos de objetos estão disponíveis: Item prototype Trigger prototype Graph prototype Host prototype Discovery prototype |
||
| Condition | Permite filtrar as entidades às quais a operação deve ser aplicada. | ||
| Operator | Operadores suportados: equals - aplicar a este prototype does not equal - aplicar a todos os prototypes, exceto este contains - aplicar se o nome do prototype contiver esta string does not contain - aplicar se o nome do prototype não contiver esta string matches - aplicar se o nome do prototype corresponder à expressão regular does not match - aplicar se o nome do prototype não corresponder à expressão regular |
||
| Pattern | Uma expressão regular ou uma string a ser pesquisada. | ||
| Object: Item prototype | |||
| Create enabled | Quando a caixa de seleção é marcada, os botões aparecem, permitindo substituir as configurações originais do item prototype: Yes - o item será adicionado em estado habilitado. No - o item será adicionado a uma entidade descoberta, mas em estado desabilitado. |
||
| Discover | Quando a caixa de seleção é marcada, os botões aparecem, permitindo substituir as configurações originais do item prototype: Yes - o item será adicionado. No - o item não será adicionado. |
||
| Update interval | Quando a caixa de seleção é marcada, duas opções aparecerão, permitindo definir um intervalo diferente para o item: Delay - intervalo de atualização do item. User macros, LLD macros e time suffixes (por exemplo, 30s, 1m, 2h, 1d) são suportados. Deve ser definido como 0 se Custom interval for usado. Custom interval - clique em para especificar intervalos flexíveis/de agendamento. Para informações detalhadas, consulte Custom intervals. |
||
| History | Quando a caixa de seleção é marcada, os botões aparecerão, permitindo definir um período diferente de armazenamento de histórico para o item: Do not store - se selecionado, o histórico não será armazenado. Store up to - se selecionado, um campo de entrada para especificar o período de armazenamento aparecerá à direita. User macros e LLD macros são suportados. |
||
| Trends | Quando a caixa de seleção é marcada, os botões aparecerão, permitindo definir um período diferente de armazenamento de tendências para o item: Do not store - se selecionado, as tendências não serão armazenadas. Store up to - se selecionado, um campo de entrada para especificar o período de armazenamento aparecerá à direita. User macros e LLD macros são suportados. |
||
| Tags | Quando a caixa de seleção é marcada, um novo bloco aparecerá, permitindo especificar pares de tag-valor. User macros e LLD macros são suportados. Essas tags serão anexadas às tags especificadas no item prototype, mesmo que os nomes das tags coincidam. |
||
| Object: Trigger prototype | |||
| Create enabled | Quando a caixa de seleção é marcada, os botões aparecem, permitindo substituir as configurações originais do trigger prototype: Yes - o trigger será adicionado em estado habilitado. No - o trigger será adicionado a uma entidade descoberta, mas em estado desabilitado. |
||
| Discover | Quando a caixa de seleção é marcada, os botões aparecem, permitindo substituir as configurações originais do trigger prototype: Yes - o trigger será adicionado. No - o trigger não será adicionado. |
||
| Severity | Quando a caixa de seleção é marcada, os botões de severidade do trigger aparecerão, permitindo modificar a severidade do trigger. | ||
| Tags | Quando a caixa de seleção é marcada, um novo bloco aparecerá, permitindo especificar pares de tag-valor. User macros e LLD macros são suportados. Essas tags serão anexadas às tags especificadas no trigger prototype, mesmo que os nomes das tags coincidam. |
||
| Object: Graph prototype | |||
| Discover | Quando a caixa de seleção é marcada, os botões aparecem, permitindo substituir as configurações originais do graph prototype: Yes - o gráfico será adicionado. No - o gráfico não será adicionado. |
||
| Object: Host prototype | |||
| Create enabled | Quando a caixa de seleção é marcada, os botões aparecem, permitindo substituir as configurações originais do host prototype: Yes - o host será criado em estado habilitado. No - o host será criado em estado desabilitado. |
||
| Discover | Quando a caixa de seleção é marcada, os botões aparecem, permitindo substituir as configurações originais do host prototype: Yes - o host será descoberto. No - o host não será descoberto. |
||
| Link templates | Quando a caixa de seleção é marcada, um campo de entrada para especificar templates aparecerá. Comece a digitar o nome do template ou clique em Select ao lado do campo e selecione templates na lista em uma janela pop-up. Os templates deste override são adicionados a todos os templates já vinculados ao host prototype. |
||
| Tags | Quando a caixa de seleção é marcada, um novo bloco aparecerá, permitindo especificar pares de tag-valor. User macros e LLD macros são suportados. Essas tags serão anexadas às tags especificadas no host prototype, mesmo que os nomes das tags coincidam. |
||
| Host inventory | Quando a caixa de seleção é marcada, os botões aparecerão, permitindo selecionar um modo diferente de inventário para o host prototype: Disabled - não preencher o inventário do host Manual - fornecer os detalhes manualmente Automated - preencher automaticamente os dados do inventário do host com base nas métricas coletadas. |
||
Botões do formulário
Os botões na parte inferior do formulário permitem realizar várias operações.
 |
Adiciona uma regra de descoberta. Este botão está disponível apenas para novas regras de descoberta. |
 |
Atualiza as propriedades de uma regra de descoberta. Este botão está disponível apenas para regras de descoberta existentes. |
 |
Cria outra regra de descoberta com base nas propriedades da regra de descoberta atual. |
 |
Executa a descoberta com base na regra de descoberta imediatamente. A regra de descoberta já deve existir. Veja mais detalhes. Nota que ao executar a descoberta imediatamente, o cache de configuração não é atualizado, portanto o resultado não refletirá alterações muito recentes na configuração da regra de descoberta. |
 |
Testa a configuração da regra de descoberta. Use este botão para verificar as configurações (como conectividade e correção dos parâmetros) sem aplicar permanentemente quaisquer alterações. |
 |
Exclui a regra de descoberta. |
 |
Cancela a edição das propriedades da regra de descoberta. |
Entidades descobertas
As capturas de tela abaixo ilustram como os items, triggers e gráficos descobertos aparecem na configuração do host. As entidades descobertas são prefixadas com um link laranja para a regra de descoberta da qual elas se originam.
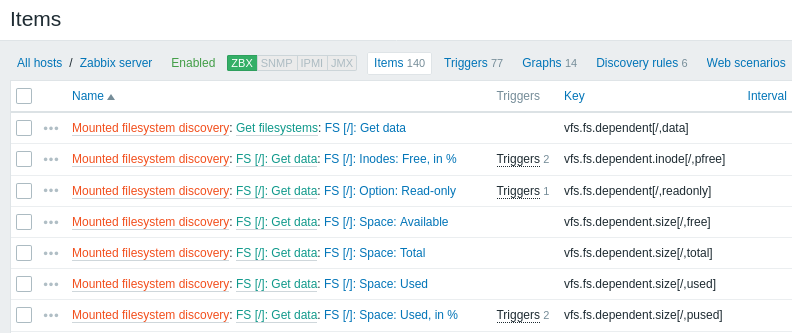
Observe que as entidades descobertas não serão criadas caso já existam entidades com os mesmos critérios de exclusividade, por exemplo, um item com a mesma chave ou um gráfico com o mesmo nome. Uma mensagem de erro é exibida neste caso no frontend informando que a regra de descoberta de baixo nível não pôde criar determinadas entidades. A própria regra de descoberta, no entanto, não ficará como não suportada porque alguma entidade não pôde ser criada e teve que ser ignorada. A regra de descoberta continuará criando/atualizando outras entidades.
Se uma entidade descoberta (host, sistema de arquivos, interface, etc) parar de ser descoberta (ou não passar mais no filtro), as entidades que foram criadas com base nela podem ser automaticamente desativadas e eventualmente excluídas.
Recursos perdidos podem ser automaticamente desativados com base no valor do parâmetro Desativar recursos perdidos. Isso afeta hosts, items e triggers perdidos.
Recursos perdidos podem ser automaticamente excluídos com base no valor do parâmetro Excluir recursos perdidos. Isso afeta hosts, grupos de hosts, items, triggers e gráficos perdidos.
Quando as entidades descobertas se tornam 'Não descobertas mais', um indicador de tempo de vida é exibido na lista de entidades. Mova o ponteiro do mouse sobre ele e uma mensagem será exibida indicando os detalhes do status.

Se as entidades foram marcadas para exclusão, mas não foram excluídas no momento esperado (regra de descoberta ou host do item desativado), elas serão excluídas na próxima vez que a regra de descoberta for processada.
Entidades que contêm outras entidades, que estão marcadas para exclusão, não serão atualizadas se forem alteradas no nível da regra de descoberta. Por exemplo, triggers baseados em LLD não serão atualizados se contiverem items que estão marcados para exclusão.
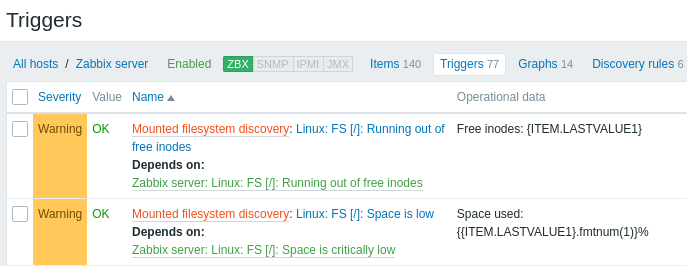
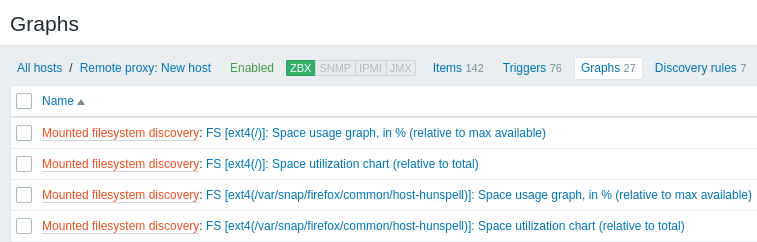
Outros tipos de descoberta
Mais detalhes e tutoriais sobre outros tipos de descoberta prontos para uso estão disponíveis nas seguintes seções:
- descoberta de interfaces de rede
- descoberta de CPUs e núcleos de CPU
- descoberta de OIDs SNMP
- descoberta de objetos JMX;
- descoberta usando consultas SQL ODBC
- descoberta de serviços do Windows
- descoberta de interfaces de host no Zabbix
Para mais detalhes sobre o formato JSON para items de descoberta e um exemplo de como implementar seu próprio descobridor de sistema de arquivos como um script Perl, veja criando regras LLD personalizadas.