
- 6 Monitoramento de arquivos de log
- Visão geral
- Configuração
- Notas importantes
- Extraindo parte correspondente da expressão regular
- Usando o parâmetro maxdelay
- Notas sobre o tratamento da rotação de arquivos de log 'copytruncate'
- Notas sobre arquivos persistentes para itens log*[]
- Ações se a comunicação falhar entre o agent e o server
- Manipulação de erros de compilação e execução de expressões regulares
6 Monitoramento de arquivos de log
Visão geral
O Zabbix pode ser usado para monitoramento centralizado e análise de arquivos de log com/sem suporte à rotação de logs.
Notificações podem ser usadas para alertar os usuários quando um arquivo de log contém determinadas strings ou padrões de string.
Para monitorar um arquivo de log, você deve ter:
- O agent Zabbix em execução no host
- item de monitoramento de log configurado
O limite de tamanho de um arquivo de log monitorado depende do suporte a arquivos grandes.
Configuração
Verifique os parâmetros do agent
Certifique-se de que no arquivo de configuração do agent:
- O parâmetro
Hostnamecorresponde ao nome do host no frontend. - Os servidores no parâmetro
ServerActiveestão especificados para o processamento de verificações ativas.
Configuração do item
Configure um item de monitoramento de log.
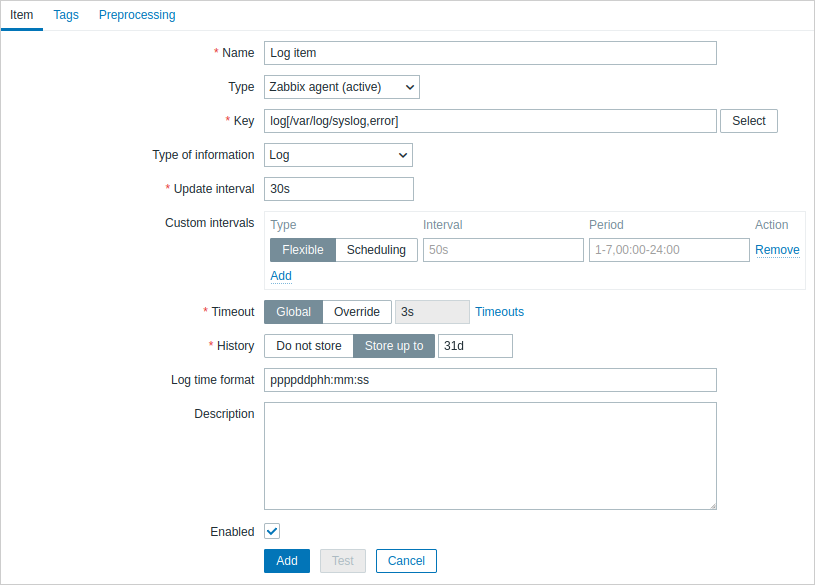
Todos os campos obrigatórios estão marcados com um asterisco vermelho.
Especificamente para itens de monitoramento de log, você deve preencher:
| Tipo | Selecione Zabbix agent (active) aqui. |
| Chave | Use uma das seguintes chaves de item: log[] ou logrt[]: Essas duas chaves de item permitem monitorar logs e filtrar entradas de log pelo conteúdo da expressão regular, se presente. Por exemplo: log[/var/log/syslog,error]. Certifique-se de que o arquivo tenha permissões de leitura para o usuário 'zabbix', caso contrário o status do item será definido como 'não suportado'.log.count[] ou logrt.count[]: Essas duas chaves de item permitem retornar apenas o número de linhas correspondentes. Consulte a seção de chaves de item do Zabbix agent suportadas para detalhes sobre o uso dessas chaves de item e seus parâmetros. |
| Tipo de informação | Pré-preenchido automaticamente: Para itens log[] ou logrt[] - Log;Para itens log.count[] ou logrt.count[] - Numérico (sem sinal).Se estiver usando opcionalmente o parâmetro output, você pode selecionar manualmente o tipo de informação apropriado diferente de Log.Observe que escolher um tipo de informação diferente de Log levará à perda do timestamp local. |
| Intervalo de atualização (em seg) | O parâmetro define com que frequência o Zabbix agent verificará alterações no arquivo de log. Definir como 1 segundo garantirá que você receba novos registros o mais rápido possível. |
| Formato de data/hora do log | Neste campo, você pode especificar opcionalmente o padrão para analisar o timestamp da linha do log. Placeholders suportados: * y: Ano (1970-2038) * M: Mês (01-12) * d: Dia (01-31) * h: Hora (00-23) * m: Minuto (00-59) * s: Segundo (00-59) Se deixado em branco, o timestamp será definido como 0 em tempo Unix, representando 1º de janeiro de 1970. Por exemplo, considere a seguinte linha do arquivo de log do Zabbix agent: " 23480:20100328:154718.045 Zabbix agent started. Zabbix 1.8.2 (revision 11211)." Ela começa com seis posições de caracteres para o PID, seguidas por data, hora e o restante da mensagem. O formato de data/hora do log para esta linha seria "pppppp:yyyyMMdd:hhmmss". Observe que os caracteres "p" e ":" são placeholders e podem ser qualquer caractere, exceto "yMdhms". |
Notas importantes
- O server e o agent mantêm o controle do tamanho do log monitorado e do horário da última modificação (para logrt) em dois contadores.
Adicionalmente:
- O agent também utiliza internamente números de inode (em UNIX/GNU/Linux), índices de arquivo (em Microsoft Windows) e somas MD5 dos primeiros 512 bytes do arquivo de log para melhorar as decisões quando os arquivos de log são truncados e rotacionados.
- Em sistemas UNIX/GNU/Linux, assume-se que os sistemas de arquivos onde os arquivos de log estão armazenados relatam números de inode, que podem ser usados para rastrear arquivos.
- No Microsoft Windows, o agent do Zabbix determina o tipo de sistema de arquivos onde os logs residem e usa:
- Em sistemas de arquivos NTFS, índices de arquivos de 64 bits.
- Em sistemas de arquivos ReFS (apenas a partir do Microsoft Windows Server 2012), IDs de arquivos de 128 bits.
- Em sistemas de arquivos onde os índices de arquivos mudam (por exemplo, FAT32, exFAT), um algoritmo alternativo é usado para adotar uma abordagem sensata em condições incertas quando a rotação do arquivo de log resulta em vários arquivos de log com o mesmo horário de modificação.
- Os números de inode, índices de arquivo e somas MD5 são coletados internamente pelo agent do Zabbix. Eles não são transmitidos para o server do Zabbix e são perdidos quando o agent do Zabbix é parado.
- Não modifique o horário da última modificação de um arquivo de log (por exemplo, com
touch) e não substitua um arquivo de log monitorado copiando um arquivo de volta para seu nome original (isso cria um novo inode). Em ambos os casos, o Zabbix pode tratar o arquivo como um arquivo diferente e relê-lo desde o início, o que pode produzir alertas duplicados. - Se houver vários arquivos de log correspondentes para o item
logrt[]e o agent do Zabbix estiver acompanhando o mais recente deles e esse arquivo de log mais recente for excluído, uma mensagem de aviso"there are no files matching "<regexp mask>" in "<directory>"será registrada. O agent do Zabbix ignora arquivos de log com horário de modificação menor que o horário de modificação mais recente visto pelo agent para o itemlogrt[]sendo verificado.
- O agent começa a ler o arquivo de log do ponto em que parou da última vez.
- O número de bytes já analisados (o contador de tamanho) e o horário da última modificação (o contador de tempo) são armazenados no banco de dados do Zabbix e enviados ao agent para garantir que o agent comece a ler o arquivo de log a partir desse ponto nos casos em que o agent acabou de ser iniciado ou recebeu items que estavam anteriormente desabilitados ou não suportados. No entanto, se o agent recebeu um contador de tamanho diferente de zero do server, mas o item logrt[] ou logrt.count[] não consegue encontrar arquivos correspondentes, o contador de tamanho é redefinido para 0 para analisar desde o início se os arquivos aparecerem posteriormente.
- Sempre que o arquivo de log se torna menor que o contador de tamanho conhecido pelo agent, o contador é redefinido para zero e o agent começa a ler o arquivo de log desde o início, levando em consideração o contador de tempo.
- Se houver vários arquivos correspondentes com o mesmo horário de modificação no diretório, o agent tentará analisar corretamente todos os arquivos de log com o mesmo horário de modificação e evitar pular dados ou analisar os mesmos dados duas vezes, embora isso não possa ser garantido em todas as situações. O agent não assume nenhum esquema específico de rotação de arquivos de log nem determina um. Quando apresentados vários arquivos de log com o mesmo horário de modificação, o agent os processará em ordem lexicográfica decrescente. Assim, para alguns esquemas de rotação, os arquivos de log serão analisados e relatados em sua ordem original. Para outros esquemas de rotação, a ordem original dos arquivos de log não será respeitada, o que pode levar ao relato de registros de arquivos de log correspondentes em ordem alterada (o problema não ocorre se os arquivos de log tiverem horários de modificação diferentes).
- O agent do Zabbix processa novos registros de um arquivo de log uma vez a cada Intervalo de atualização segundos.
- O agent do Zabbix não envia mais do que maxlines de um arquivo de log por segundo. O limite evita a sobrecarga de recursos de rede e CPU e substitui o valor padrão fornecido pelo parâmetro MaxLinesPerSecond no arquivo de configuração do agent.
- Para encontrar a string necessária, o Zabbix processará 10 vezes mais novas linhas do que definido em MaxLinesPerSecond.
Assim, por exemplo, se um item
log[]oulogrt[]tiver Intervalo de atualização de 1 segundo, por padrão o agent analisará no máximo 200 registros de arquivos de log e enviará no máximo 20 registros correspondentes ao server do Zabbix em uma verificação. Aumentando MaxLinesPerSecond no arquivo de configuração do agent ou definindo o parâmetro maxlines na chave do item, o limite pode ser aumentado para até 10000 registros de arquivos de log analisados e 1000 registros correspondentes enviados ao server do Zabbix em uma verificação. Se o Intervalo de atualização for definido como 2 segundos, os limites para uma verificação serão definidos 2 vezes maiores do que com Intervalo de atualização de 1 segundo. - Além disso, os valores de log e log.count são sempre limitados a 50% do tamanho do buffer de envio do agent, mesmo que não haja valores de log nele. Portanto, para que os valores maxlines sejam enviados em uma conexão (e não em várias conexões), o parâmetro BufferSize do agent deve ser pelo menos maxlines x 2. O agent do Zabbix pode fazer upload de dados durante a coleta de logs e, assim, liberar o buffer, enquanto o agent do Zabbix 2 interromperá a coleta de logs até que os dados sejam enviados e o buffer seja liberado, o que é feito de forma assíncrona.
- Na ausência de items de log, todo o tamanho do buffer do agent é usado para valores que não são de log. Quando os valores de log chegam, eles substituem os valores mais antigos que não são de log, conforme necessário, até o limite de 50%.
- Para registros de arquivos de log com mais de 256kB, apenas os primeiros 256kB são comparados com a expressão regular e o restante do registro é ignorado. No entanto, se o agent do Zabbix for interrompido enquanto estiver lidando com um registro longo, o estado interno do agent será perdido e o registro longo poderá ser analisado novamente e de forma diferente após o agent ser iniciado novamente.
- Nota especial para separadores de caminho "\": se file_format for "file\.log", então não deve haver um diretório "file", pois não é possível definir de forma inequívoca se "." está escapado ou é o primeiro símbolo do nome do arquivo.
- Expressões regulares para
logrtsão suportadas apenas no nome do arquivo, a correspondência de expressão regular no diretório não é suportada. - Em plataformas UNIX, um item
logrt[]se torna NOTSUPPORTED se um diretório onde os arquivos de log devem ser encontrados não existir. - No Microsoft Windows, se um diretório não existir, o item não se tornará NOTSUPPORTED (por exemplo, se o diretório estiver com erro de digitação na chave do item).
- A ausência de arquivos de log para o item
logrt[]não o torna NOTSUPPORTED. Erros de leitura de arquivos de log para o itemlogrt[]são registrados como avisos no arquivo de log do agent do Zabbix, mas não tornam o item NOTSUPPORTED. - O arquivo de log do agent do Zabbix pode ser útil para descobrir por que um item
log[]oulogrt[]se tornou NOTSUPPORTED. O Zabbix pode monitorar seu arquivo de log do agent, exceto quando em DebugLevel=4 ou DebugLevel=5. - Pesquisar um ponto de interrogação usando uma expressão regular, por exemplo,
\?pode resultar em falsos positivos se o arquivo de texto contiver símbolos NUL, pois estes são substituídos por "?" pelo Zabbix para continuar processando a linha até o caractere de nova linha.
Extraindo parte correspondente da expressão regular
Às vezes, podemos querer extrair apenas o valor interessante de um arquivo de destino em vez de retornar toda a linha quando uma correspondência de expressão regular for encontrada.
Os items de log têm a capacidade de extrair valores desejados de linhas correspondentes.
Isso é realizado pelo parâmetro adicional output nos items log e logrt.
Usar o parâmetro 'output' permite indicar o "grupo de captura" da correspondência que pode nos interessar.
Assim, por exemplo
log[/path/to/the/file,"large result buffer allocation.*Entries: ([0-9]+)",,,,\1]deve permitir retornar a contagem de entradas conforme encontrada no conteúdo de:
Fr Feb 07 2014 11:07:36.6690 */ Thread Id 1400 (GLEWF) large result
buffer allocation - /Length: 437136/Entries: 5948/Client Ver: >=10/RPC
ID: 41726453/User: AUser/Form: CFG:ServiceLevelAgreementApenas o número será retornado porque \1 refere-se ao primeiro e único grupo de captura: ([0-9]+).
E, com a capacidade de extrair e retornar um número, o valor pode ser usado para definir triggers.
Usando o parâmetro maxdelay
O parâmetro maxdelay em items de log permite ignorar algumas linhas mais antigas dos arquivos de log para que as linhas mais recentes sejam analisadas dentro dos segundos definidos em maxdelay.
Especificar 'maxdelay' > 0 pode levar a ignorar registros importantes do arquivo de log e perder alertas. Use com cuidado, por sua conta e risco, apenas quando necessário.
Por padrão, os items para monitoramento de log acompanham todas as novas linhas que aparecem nos arquivos de log.
No entanto, existem aplicações que, em algumas situações, começam a gravar um número enorme de mensagens em seus arquivos de log.
Por exemplo, se um banco de dados ou servidor DNS estiver indisponível, essas aplicações inundam os arquivos de log com milhares de mensagens de erro quase idênticas até que a operação normal seja restaurada.
Por padrão, todas essas mensagens serão devidamente analisadas e as linhas correspondentes enviadas para o server conforme configurado nos items log e logrt.
A proteção interna contra sobrecarga consiste em um parâmetro configurável maxlines (protege o server de muitas linhas de log correspondentes recebidas) e um limite de 10*'maxlines' (protege a CPU e o I/O do host de sobrecarga pelo agent em uma verificação).
Ainda assim, existem 2 problemas com a proteção interna.
Primeiro, um grande número de mensagens potencialmente pouco informativas são reportadas ao server e consomem espaço no banco de dados.
Segundo, devido ao número limitado de linhas analisadas por segundo, o agent pode ficar atrasado em relação aos registros mais recentes do log por horas.
Muito provavelmente, você pode preferir ser informado mais rapidamente sobre a situação atual nos arquivos de log em vez de analisar registros antigos por horas.
A solução para ambos os problemas é usar o parâmetro maxdelay.
Se maxdelay > 0 for especificado, durante cada verificação o número de bytes processados, o número de bytes restantes e o tempo de processamento são medidos.
A partir desses números, o agent calcula um atraso estimado - quantos segundos levaria para analisar todos os registros restantes em um arquivo de log.
Se o atraso não exceder maxdelay, o agent prossegue com a análise do arquivo de log normalmente.
Se o atraso for maior que maxdelay, o agent ignora um trecho do arquivo de log "pulando" sobre ele para uma nova posição estimada, de modo que as linhas restantes possam ser analisadas dentro dos segundos definidos em maxdelay.
Observe que o agent nem mesmo lê as linhas ignoradas para o buffer, mas calcula uma posição aproximada para pular no arquivo.
O fato de pular linhas do arquivo de log é registrado no arquivo de log do agent assim:
14287:20160602:174344.206 item:"logrt["/home/zabbix32/test[0-9].log",ERROR,,1000,,,120.0]"
logfile:"/home/zabbix32/test1.log" skipping 679858 bytes
(from byte 75653115 to byte 76332973) to meet maxdelayO número "to byte" é aproximado porque, após o "pulo", o agent ajusta a posição no arquivo para o início de uma linha de log, que pode estar mais à frente ou mais atrás no arquivo.
Dependendo de como a velocidade de crescimento se compara com a velocidade de análise do arquivo de log, você pode não ver "pulos", ver "pulos" raros ou frequentes, "pulos" grandes ou pequenos, ou até mesmo um pequeno "pulo" em cada verificação. Flutuações na carga do sistema e na latência da rede também afetam o cálculo do atraso e, portanto, o "pulo" à frente para acompanhar o parâmetro "maxdelay".
Definir maxdelay < intervalo de atualização não é recomendado (pode resultar em "pulos" pequenos e frequentes).
Notas sobre o tratamento da rotação de arquivos de log 'copytruncate'
logrt com a opção copytruncate assume que arquivos de log diferentes possuem registros diferentes (pelo menos seus timestamps são diferentes), portanto, os hashes MD5 dos blocos iniciais (até os primeiros 512 bytes) serão diferentes.
Dois arquivos com os mesmos hashes MD5 dos blocos iniciais significam que um deles é o original e o outro é uma cópia.
logrt com a opção copytruncate faz um esforço para processar corretamente as cópias dos arquivos de log sem relatar duplicatas.
No entanto, ações como produzir várias cópias de arquivos de log com o mesmo timestamp, rotacionar o arquivo de log com mais frequência do que o intervalo de atualização do item logrt[], reiniciar o agent frequentemente não são recomendadas.
O agent tenta lidar com todas essas situações de forma razoável, mas bons resultados não podem ser garantidos em todas as circunstâncias.
Notas sobre arquivos persistentes para itens log*[]
Objetivo dos arquivos persistentes
Quando o agent do Zabbix é iniciado, ele recebe uma lista de verificações ativas do server ou proxy do Zabbix. Para métricas log[], ele recebe o tamanho do log processado e o horário de modificação para determinar de onde começar o monitoramento do arquivo de log. Dependendo do tamanho real do arquivo de log e do horário de modificação relatados pelo sistema de arquivos, o agent decide se continua o monitoramento do arquivo de log a partir do tamanho processado ou se reanalisa o arquivo de log desde o início.
Um agent em execução mantém um conjunto maior de atributos para rastrear todos os arquivos de log monitorados entre as verificações. Esse estado em memória é perdido quando o agent é interrompido.
O novo parâmetro opcional persistent_dir especifica um diretório para armazenar esse estado dos itens log[], log.count[], logrt[] ou logrt.count[] em um arquivo. O estado do item de log é restaurado a partir do arquivo persistente após o agent do Zabbix ser reiniciado.
O principal caso de uso é o monitoramento de um arquivo de log localizado em um sistema de arquivos espelhado. Até certo momento, o arquivo de log é gravado em ambos os espelhos. Depois, os espelhos são separados. Na cópia ativa, o arquivo de log continua crescendo, recebendo novos registros. O agent do Zabbix o analisa e envia o tamanho dos logs processados e o horário de modificação para o server. Na cópia passiva, o arquivo de log permanece o mesmo, bem atrás da cópia ativa. Mais tarde, o sistema operacional e o agent do Zabbix são reiniciados a partir da cópia passiva. O tamanho do log processado e o horário de modificação que o agent do Zabbix recebe do server podem não ser válidos para a situação na cópia passiva. Para continuar o monitoramento do arquivo de log a partir do ponto em que o agent parou no momento da separação do espelho do sistema de arquivos, o agent restaura seu estado a partir do arquivo persistente.
Operação do agent com arquivo persistente
Na inicialização, o agent do Zabbix não sabe nada sobre arquivos persistentes. Somente após receber uma lista de verificações ativas do Zabbix server (proxy), o agent percebe que alguns itens de log devem ser respaldados por arquivos persistentes em diretórios especificados.
Durante a operação do agent, os arquivos persistentes são abertos para escrita (com fopen(filename, "w")) e sobrescritos com os dados mais recentes. A chance de perder dados do arquivo persistente se a sobrescrita e a divisão do espelhamento do sistema de arquivos acontecerem ao mesmo tempo é muito pequena, não há tratamento especial para isso. A gravação no arquivo persistente NÃO é seguida por sincronização forçada com a mídia de armazenamento (fsync() não é chamado).
A sobrescrita com os dados mais recentes é feita após o relatório bem-sucedido do registro correspondente do arquivo de log ou dos metadados (tamanho do log processado e hora da modificação) para o Zabbix server. Isso pode acontecer com a mesma frequência de cada verificação de item se o arquivo de log continuar mudando.
Nenhuma ação especial durante o desligamento do agent.
Após receber uma lista de verificações ativas, o agent marca arquivos persistentes obsoletos para remoção. Um arquivo persistente se torna obsoleto se:
- O item de log correspondente não é mais monitorado.
- Um item de log é reconfigurado com um local persistent_dir diferente do anterior.
A remoção é feita com um atraso de 24 horas porque arquivos de log em estado NOTSUPPORTED não estão incluídos na lista de verificações ativas, mas podem se tornar SUPPORTED posteriormente e seus arquivos persistentes serão úteis.
Se o agent for parado antes de expirar as 24 horas, os arquivos obsoletos não serão excluídos, pois o agent Zabbix não está mais recebendo informações sobre sua localização do server Zabbix.
Reconfigurar o persistent_dir de um item de log de volta para o local antigo enquanto o agent está parado, sem excluir o arquivo persistente antigo pelo usuário - fará com que o estado do agent seja restaurado a partir do arquivo persistente antigo, resultando em mensagens perdidas ou alertas falsos.
Nomeação e localização de arquivos persistentes
O agent do Zabbix diferencia as verificações ativas por suas chaves. Por exemplo, logrt[/home/zabbix/test.log] e logrt[/home/zabbix/test.log,] são itens diferentes. Modificar o item logrt[/home/zabbix/test.log,,,10] no frontend para logrt[/home/zabbix/test.log,,,20] resultará na exclusão do item logrt[/home/zabbix/test.log,,,10] da lista de verificações ativas do agent e na criação do item logrt[/home/zabbix/test.log,,,20] (alguns atributos são mantidos durante a modificação no frontend/server, mas não no agent).
O nome do arquivo é composto pela soma MD5 da chave do item com o comprimento da chave do item anexado para reduzir a possibilidade de colisões. Por exemplo, o estado do item logrt[/home/zabbix50/test.log,,,,,,,,/home/zabbix50/agent_private] será mantido no arquivo persistente c963ade4008054813bbc0a650bb8e09266.
Vários itens de log podem usar o mesmo valor de persistent_dir.
persistent_dir é especificado levando em consideração layouts específicos de sistemas de arquivos, pontos de montagem e opções de montagem e configuração de espelhamento de armazenamento - o arquivo persistente deve estar no mesmo sistema de arquivos espelhado que o arquivo de log monitorado.
Se o diretório persistent_dir não puder ser criado ou não existir, ou se os direitos de acesso para o agent do Zabbix não permitirem criar/gravar/ler/excluir arquivos, o item de log se tornará NÃO SUPORTADO.
Se os direitos de acesso aos arquivos de armazenamento persistente forem removidos durante a operação do agent ou outros erros ocorrerem (por exemplo, disco cheio), os erros serão registrados no arquivo de log do agent, mas o item de log não se tornará NOTSUPPORTED.
Carga em I/O
O arquivo persistente do item é atualizado após o envio bem-sucedido de cada lote de dados (contendo os dados do item) para o server.
Por exemplo, o BufferSize padrão é 100.
Se um item de log encontrou 70 registros correspondentes, os primeiros 50 registros serão enviados em um lote, o arquivo persistente será atualizado, então os 20 registros restantes serão enviados (talvez com algum atraso quando mais dados forem acumulados) no segundo lote, e o arquivo persistente será atualizado novamente.
Ações se a comunicação falhar entre o agent e o server
Cada linha correspondente dos itens log[] e logrt[] e o resultado de cada verificação dos itens log.count[] e logrt.count[] requerem um slot livre na área designada de 50% no buffer de envio do agent.
Os elementos do buffer são enviados regularmente para o server (ou proxy) e os slots do buffer ficam livres novamente.
Enquanto houver slots livres na área designada de log no buffer de envio do agent e a comunicação falhar entre o agent e o server (ou proxy), os resultados do monitoramento de log são acumulados no buffer de envio. Isso ajuda a mitigar falhas de comunicação de curta duração.
Durante falhas de comunicação mais longas, todos os slots de log são ocupados e as seguintes ações são tomadas:
- As verificações dos itens
log[]elogrt[]são interrompidas. Quando a comunicação é restabelecida e há slots livres no buffer, as verificações são retomadas a partir da posição anterior. Nenhuma linha correspondente é perdida, elas apenas são relatadas posteriormente. - As verificações dos itens
log.count[]elogrt.count[]são interrompidas semaxdelay = 0(padrão). O comportamento é semelhante aos itenslog[]elogrt[]conforme descrito acima. Observe que isso pode afetar os resultados delog.count[]elogrt.count[]: por exemplo, uma verificação conta 100 linhas correspondentes em um arquivo de log, mas como não há slots livres no buffer, a verificação é interrompida. Quando a comunicação é restabelecida, o agent conta as mesmas 100 linhas correspondentes e também 70 novas linhas correspondentes. O agent agora envia count = 170 como se fossem encontradas em uma única verificação. - As verificações dos itens
log.count[]elogrt.count[]commaxdelay > 0: se não houve "salto" durante a verificação, o comportamento é semelhante ao descrito acima. Se ocorreu um "salto" sobre as linhas do arquivo de log, então a posição após o "salto" é mantida e o resultado contado é descartado. Assim, o agent tenta acompanhar o crescimento do arquivo de log mesmo em caso de falha de comunicação.
Manipulação de erros de compilação e execução de expressões regulares
Se uma expressão regular usada nos itens log[], logrt[], log.count[] ou logrt.count[] não puder ser compilada pela biblioteca PCRE ou PCRE2, o item entra no estado NOTSUPPORTED com uma mensagem de erro.
Para continuar monitorando o item de log, a expressão regular deve ser corrigida.
Se a expressão regular for compilada com sucesso, mas falhar em tempo de execução (em alguns ou em todos os registros de log), o item de log permanece suportado e o monitoramento continua. O erro de tempo de execução é registrado no arquivo de log do agent Zabbix (sem o registro do arquivo de log).
A taxa de registro é limitada a um erro de tempo de execução por verificação para permitir que o agent Zabbix monitore seu próprio arquivo de log. Por exemplo, se 10 registros forem analisados e 3 registros falharem com um erro de tempo de execução de expressão regular, um registro será produzido no log do agent.
Exceção: se MaxLinesPerSecond=1 e o intervalo de atualização=1 (apenas 1 registro é permitido analisar por verificação), então erros de tempo de execução de expressão regular não são registrados.
O zabbix_agentd registra a chave do item em caso de erro de tempo de execução, o zabbix_agent2 registra o ID do item para ajudar a identificar qual item de log possui erros de tempo de execução. É recomendável redesenhar a expressão regular em caso de erros de tempo de execução.