
5 发现原型
概述
发现原型是在“父”发现规则中的嵌套低级别发现规则,可用于创建对象的多级发现,并为这些对象创建各自的监控项、触发器等。例如,您可能希望先发现数据库服务器上的所有数据库实例,然后为每个实例发现表空间,再为每个表空间发现数据表。
发现原型拥有各自的监控项、触发器、图形、主机和发现原型。如果您指定 Nested 类型,则嵌套发现原型将使用与父规则相同的 JSON 值。
发现原型的嵌套层级没有限制。
配置
要创建发现原型:
- 在现有发现规则所在行中单击 Discovery prototypes

- 单击 Create discovery prototype
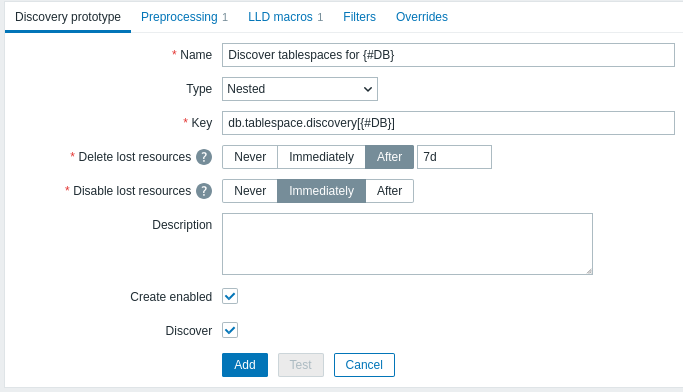
此表单中的配置字段与常规的 低级发现 共享。
如果你在打开的发现原型表单中将 Type 选择为 "Nested",则会基于与父发现规则相同的 JSON 值中的一个 JSON 对象生成发现规则(来自发现原型)。例如,如果原始 JSON 为 [<object A>, <object B>],并且只有一个嵌套发现规则原型,那么将分别基于 object A 和 object B 的数据生成两个发现规则。
在这种情况下,发现原型会与父规则同时激活。因此,嵌套规则可以使用预处理,对父规则已获取的同一数据的另一个“切片”进行处理。
父 LLD 规则中的 LLD 宏可用于嵌套发现规则。
已发现主机上的嵌套 LLD 规则
嵌套低级别发现规则可用于分配给主机原型的主机模板。如果在已发现主机上存在 嵌套 发现规则,则用于发现该主机的 JSON 对象也会发送到该主机上所有嵌套类型的 LLD 规则。更多详细信息,请参见示例。
创建该主机的发现规则中的 LLD 宏可用于嵌套发现规则。
示例
让我们基于接收到的以下多级 JSON 示例,说明发现原型的一种可能应用。
[
{
"database": "db1",
"created_at": "2024-02-01T12:30:00Z",
"encoding": "UTF8",
"tablespaces": [
{ "name": "ts1", "max_size": "10GB" },
{ "name": "ts2", "max_size": "20GB" },
{ "name": "ts3", "max_size": "15GB" }
]
},
{
"database": "db2",
"created_at": "2023-11-15T08:45:00Z",
"encoding": "UTF16",
"tablespaces": [
{ "name": "ts1", "max_size": "5GB" },
{ "name": "ts2", "max_size": "25GB" },
{ "name": "ts3", "max_size": "30GB" }
]
},
{
"database": "db3",
"created_at": "2024-01-05T15:10:00Z",
"encoding": "UTF8",
"tablespaces": [
{ "name": "ts1", "max_size": "12GB" },
{ "name": "ts2", "max_size": "18GB" },
{ "name": "ts3", "max_size": "22GB" }
]
}
]案例 1
发现数据库服务器上的数据库实例,然后发现每个实例的表空间。
-
您至少有一个与数据库服务器发现相关的主机。
-
为该主机创建一个名为 发现数据库和表空间 的 LLD 规则。
-
切换到该规则的 LLD 宏 选项卡,添加宏
{#DB}=$.database。 -
为该规则添加一个名为 {#DB} 的活动连接数 的监控项原型(类型:Agent,键值:
db.connections[{#DB}])。 -
发现与每个数据库相关的监控项:
Active connections to db1, Active connections to db2, Active connections to db3.-
为该规则创建一个名为 发现 {#DB} 的表空间 的发现原型(类型:Nested,键值:
db.tablespace.discovery[{#DB}])。 -
切换到该发现原型的 预处理 选项卡,并添加步骤
JSONPath=$.tablespaces。 -
切换到该发现原型的 LLD 宏 选项卡,添加宏
{#TSNAME}=$.name。 -
为该发现原型创建一个名为 {#DB} 的表空间 {#TSNAME} 的大小 的监控项原型(类型:Agent,键值:
db.ts.size[{#DB}, {#TSNAME}])。 -
发现与每个数据库的每个表空间相关的监控项:
Size of tablespace ts1 for db1, Size of tablespace ts2 for db1, Size of tablespace ts3 for db1,
Size of tablespace ts1 for db2, Size of tablespace ts2 for db2, Size of tablespace ts3 for db2,
Size of tablespace ts1 for db3, Size of tablespace ts2 for db3, Size of tablespace ts3 for db3.其键值为 db.ts.size[db1,ts1]、db.ts.size[db1,ts2]、... db.ts.size[db3,ts3]。
情况 2
通过将数据库服务器上的数据库实例表示为已发现的主机来发现这些实例,然后发现每个实例的表空间。
-
您至少有一个与数据库服务器发现相关的主机(根主机)。
-
创建一个模板,用于发现每个数据库的表空间。
-
在此模板中创建一个名为 到 {#DB} 的活动连接数 的监控项(类型:agent,键值:
db.connections[{#DB}])。 -
为此模板创建一个名为 发现表空间 的 LLD 规则(类型:嵌套)。
-
切换到此规则的 预处理 选项卡,并添加步骤
JSONPath=$.tablespaces。 -
切换到此规则的 LLD 宏 选项卡,添加宏
{#TSNAME}=$.name。 -
为此规则创建一个名为 {#DB} 的表空间 {#TSNAME} 的大小 的监控项原型(类型:agent,键值:
db.ts.size[{#DB}, {#TSNAME}])。 -
回到根主机,为此主机创建一个名为 发现数据库和表空间 的 LLD 规则。
-
切换到此规则的 LLD 宏 选项卡,添加宏
{#DB}=$.database。 -
为此规则添加一个名为 数据库 {#DB} 的主机 的主机原型。
-
切换到此主机原型的 宏 选项卡,添加宏
{$DB}={#DB}(用于步骤 3 中监控项的名称和键值)。 -
将步骤 2 中的模板链接到此主机原型。
-
已发现的主机包含与每个数据库及其表空间相关的已发现监控项:
| 主机 | 监控项 |
|---|---|
| 数据库 db1 的主机 | 到 db1 的活动连接数 db1 的表空间 ts1 的大小 db1 的表空间 ts2 的大小 db1 的表空间 ts3 的大小 |
| 数据库 db2 的主机 | 到 db2 的活动连接数 db2 的表空间 ts1 的大小 db2 的表空间 ts2 的大小 db2 的表空间 ts3 的大小 |
| 数据库 db3 的主机 | 到 db3 的活动连接数 db3 的表空间 ts1 的大小 db3 的表空间 ts2 的大小 db3 的表空间 ts3 的大小 |