
- 6 Monitorización de archivos de registro
- Descripción general
- Configuración
- Notas importantes
- Extrayendo la parte coincidente de una expresión regular
- Uso del parámetro maxdelay
- Notas sobre el manejo de la rotación de archivos de registro 'copytruncate'
- Notas sobre archivos persistentes para métricas log*[]
- Acciones si falla la comunicación entre el agente y el servidor
- Manejo de errores de compilación y de ejecución de expresiones regulares
6 Monitorización de archivos de registro
Descripción general
Zabbix puede utilizarse para la monitorización centralizada y el análisis de archivos de registro con o sin soporte para rotación de registros.
Se pueden utilizar notificaciones para advertir a los usuarios cuando un archivo de registro contiene ciertas cadenas o patrones de cadenas.
Para monitorizar un archivo de registro debe tener:
- El agente de Zabbix ejecutándose en el equipo
- Un elemento de monitorización de registros configurado
El límite de tamaño de un archivo de registro monitorizado depende del soporte para archivos grandes.
Configuración
Verificar los parámetros del agente
Asegúrese de que en el archivo de configuración del agente:
- El parámetro
Hostnamecoincida con el nombre del equipo en la interfaz web. - Los servidores en el parámetro
ServerActiveestén especificados para el procesamiento de comprobaciones activas.
Configuración del item
Configure un item de monitorización de logs.
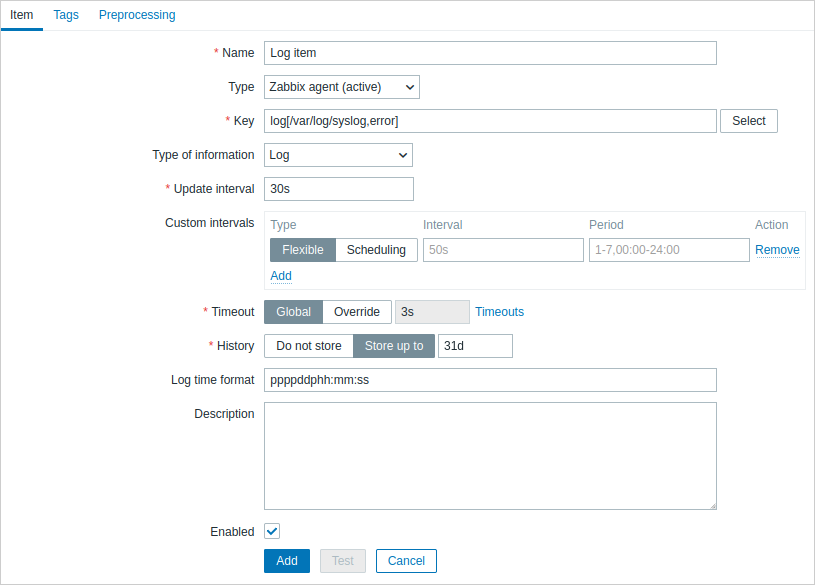
Todos los campos de entrada obligatorios están marcados con un asterisco rojo.
Específicamente, para los items de monitorización de logs debe introducir:
| Type | Seleccione aquí Zabbix agent (active). |
| Key | Utilice una de las siguientes claves de item: log[] o logrt[]: Estas dos claves de item permiten monitorizar logs y filtrar entradas de log por el contenido regexp, si está presente. Por ejemplo: log[/var/log/syslog,error]. Asegúrese de que el archivo tenga permisos de lectura para el usuario 'zabbix'; de lo contrario, el estado del item se establecerá en 'unsupported'.log.count[] o logrt.count[]: Estas dos claves de item permiten devolver solo el número de líneas coincidentes. Consulte la sección de claves de item de Zabbix agent compatibles para obtener detalles sobre el uso de estas claves de item y sus parámetros. |
| Type of information | Se completa automáticamente: Para los items log[] o logrt[]: Log;Para los items log.count[] o logrt.count[]: Numeric (unsigned).Si utiliza opcionalmente el parámetro output, puede seleccionar manualmente el tipo de información adecuado distinto de Log.Tenga en cuenta que elegir un tipo de información que no sea Log provocará la pérdida de la marca de tiempo local. |
| Update interval (in sec) | El parámetro define con qué frecuencia Zabbix agent comprobará si hay cambios en el archivo de log. Establecerlo en 1 segundo garantizará que reciba nuevos registros lo antes posible. |
| Log time format | En este campo puede especificar opcionalmente el patrón para analizar la marca de tiempo de la línea de log. Marcadores de posición compatibles: * y: Año (1970-2038) * M: Mes (01-12) * d: Día (01-31) * h: Hora (00-23) * m: Minuto (00-59) * s: Segundo (00-59) Si se deja en blanco, la marca de tiempo se establecerá en 0 en tiempo Unix, lo que representa el 1 de enero de 1970. Por ejemplo, considere la siguiente línea del archivo de log de Zabbix agent: " 23480:20100328:154718.045 Zabbix agent started. Zabbix 1.8.2 (revision 11211)." Comienza con seis posiciones de caracteres para el PID, seguidas de la fecha, la hora y el resto del mensaje. El formato de hora de log para esta línea sería "pppppp:yyyyMMdd:hhmmss". Tenga en cuenta que los caracteres "p" y ":" son marcadores de posición y pueden ser cualquier carácter excepto "yMdhms". |
Notas importantes
- El server y el agent mantienen el seguimiento del tamaño de un archivo de registro monitorizado y de la hora de su última modificación (para logrt) en dos contadores.
Además:
- El agent también utiliza internamente números de inodo (en UNIX/GNU/Linux), índices de archivo (en Microsoft Windows) y sumas MD5 de los primeros 512 bytes del archivo de registro para mejorar las decisiones cuando los archivos de registro se truncan y rotan.
- En sistemas UNIX/GNU/Linux se asume que los sistemas de archivos donde se almacenan los archivos de registro informan números de inodo, que pueden utilizarse para rastrear archivos.
- En Microsoft Windows, Zabbix agent determina el tipo de sistema de archivos en el que residen los archivos de registro y utiliza:
- En sistemas de archivos NTFS, índices de archivo de 64 bits.
- En sistemas de archivos ReFS (solo desde Microsoft Windows Server 2012), ID de archivo de 128 bits.
- En sistemas de archivos donde los índices de archivo cambian (por ejemplo, FAT32, exFAT), se utiliza un algoritmo alternativo para adoptar un enfoque razonable en condiciones inciertas cuando la rotación de archivos de registro da como resultado varios archivos de registro con la misma hora de última modificación.
- Los números de inodo, índices de archivo y sumas MD5 son recopilados internamente por Zabbix agent. No se transmiten al Zabbix server y se pierden cuando Zabbix agent se detiene.
- No modifique la hora de última modificación de un archivo de registro (por ejemplo, con
touch) y no sustituya un archivo de registro monitorizado copiando un archivo de vuelta a su nombre original (esto crea un nuevo inodo). En cualquiera de los dos casos, Zabbix puede tratar el archivo como si fuera un archivo diferente y volver a leerlo desde el principio, lo que puede producir alertas duplicadas. - Si hay varios archivos de registro coincidentes para el item
logrt[]y Zabbix agent está siguiendo el más reciente de ellos y este archivo de registro más reciente se elimina, se registra un mensaje de advertencia"there are no files matching "<regexp mask>" in "<directory>". Zabbix agent ignora los archivos de registro con una hora de modificación inferior a la hora de modificación más reciente vista por el agent para el itemlogrt[]que se está comprobando.
- El agent comienza a leer el archivo de registro desde el punto en el que se detuvo la vez anterior.
- El número de bytes ya analizados (el contador de tamaño) y la hora de última modificación (el contador de tiempo) se almacenan en la base de datos de Zabbix y se envían al agent para asegurarse de que el agent comience a leer el archivo de registro desde ese punto en los casos en que el agent acaba de iniciarse o ha recibido items que anteriormente estaban deshabilitados o no eran compatibles. Sin embargo, si el agent ha recibido del server un contador de tamaño distinto de cero, pero el item logrt[] o logrt.count[] no puede encontrar archivos coincidentes, el contador de tamaño se restablece a 0 para analizar desde el principio si los archivos aparecen más tarde.
- Siempre que el archivo de registro se vuelva más pequeño que el contador de tamaño del registro conocido por el agent, el contador se restablece a cero y el agent comienza a leer el archivo de registro desde el principio teniendo en cuenta el contador de tiempo.
- Si hay varios archivos coincidentes con la misma hora de última modificación en el directorio, entonces el agent intenta analizar correctamente todos los archivos de registro con la misma hora de modificación y evitar omitir datos o analizar los mismos datos dos veces, aunque esto no puede garantizarse en todas las situaciones. El agent no asume ningún esquema particular de rotación de archivos de registro ni determina uno. Cuando se le presentan varios archivos de registro con la misma hora de última modificación, el agent los procesará en orden lexicográfico descendente. Por lo tanto, para algunos esquemas de rotación, los archivos de registro se analizarán y se informarán en su orden original. Para otros esquemas de rotación, no se respetará el orden original de los archivos de registro, lo que puede llevar a informar registros de archivos de registro coincidentes en un orden alterado (el problema no ocurre si los archivos de registro tienen distintas horas de última modificación).
- Zabbix agent procesa los nuevos registros de un archivo de registro una vez cada Update interval segundos.
- Zabbix agent no envía más de maxlines de un archivo de registro por segundo. El límite evita la sobrecarga de los recursos de red y CPU y prevalece sobre el valor predeterminado proporcionado por el parámetro MaxLinesPerSecond en el archivo de configuración del agent.
- Para encontrar la cadena requerida, Zabbix procesará 10 veces más líneas nuevas de las establecidas en MaxLinesPerSecond.
Así, por ejemplo, si un item
log[]ologrt[]tiene un Update interval de 1 segundo, de forma predeterminada el agent no analizará más de 200 registros del archivo de registro y no enviará más de 20 registros coincidentes al Zabbix server en una comprobación. Al aumentar MaxLinesPerSecond en el archivo de configuración del agent o al establecer el parámetro maxlines en la clave del item, el límite puede aumentarse hasta 10000 registros de archivo de registro analizados y 1000 registros coincidentes enviados al Zabbix server en una comprobación. Si el Update interval se establece en 2 segundos, los límites para una comprobación serán 2 veces mayores que con un Update interval de 1 segundo. - Además, los valores de log y log.count siempre están limitados al 50% del tamaño del búfer de envío del agent, incluso si no hay valores que no sean de log en él. Por lo tanto, para que los valores de maxlines se envíen en una sola conexión (y no en varias conexiones), el parámetro BufferSize del agent debe ser al menos maxlines x 2. Zabbix agent puede cargar datos durante la recopilación de registros y así liberar el búfer, mientras que Zabbix agent 2 detendrá la recopilación de registros hasta que los datos se carguen y el búfer se libere, lo cual se realiza de forma asíncrona.
- En ausencia de items de log, todo el tamaño del búfer del agent se utiliza para valores que no son de log. Cuando llegan valores de log, reemplazan los valores no log más antiguos según sea necesario, hasta el 50% designado.
- Para registros de archivos de registro de más de 256 kB, solo los primeros 256 kB se comparan con la expresión regular y el resto del registro se ignora. Sin embargo, si Zabbix agent se detiene mientras está procesando un registro largo, el estado interno del agent se pierde y el registro largo puede analizarse de nuevo y de forma diferente después de que el agent se inicie otra vez.
- Nota especial para los separadores de ruta "\": si file_format es "file\.log", entonces no debe existir un directorio "file", ya que no es posible definir sin ambigüedad si "." está escapado o si es el primer símbolo del nombre del archivo.
- Las expresiones regulares para
logrtsolo se admiten en el nombre de archivo; no se admite la coincidencia de expresiones regulares en directorios. - En plataformas UNIX, un item
logrt[]pasa a ser NOTSUPPORTED si no existe un directorio donde se espera encontrar los archivos de registro. - En Microsoft Windows, si un directorio no existe, el item no pasará a ser NOTSUPPORTED (por ejemplo, si el directorio está mal escrito en la clave del item).
- La ausencia de archivos de registro para el item
logrt[]no hace que pase a ser NOTSUPPORTED. Los errores de lectura de archivos de registro para el itemlogrt[]se registran como advertencias en el archivo de registro de Zabbix agent, pero no hacen que el item pase a ser NOTSUPPORTED. - El archivo de registro de Zabbix agent puede ser útil para averiguar por qué un item
log[]ologrt[]pasó a ser NOTSUPPORTED. Zabbix puede monitorizar el archivo de registro de su agent, excepto cuando DebugLevel=4 o DebugLevel=5. - Buscar un signo de interrogación mediante una expresión regular, por ejemplo
\?, puede dar lugar a falsos positivos si el archivo de texto contiene símbolos NUL, ya que Zabbix los sustituye por "?" para continuar procesando la línea hasta el carácter de nueva línea.
Extrayendo la parte coincidente de una expresión regular
A veces podemos querer extraer solo el valor interesante de un archivo de destino en lugar de devolver toda la línea cuando se encuentra una coincidencia de expresión regular.
Los elementos de registro tienen la capacidad de extraer los valores deseados de las líneas coincidentes.
Esto se logra mediante el parámetro adicional output en los elementos log y logrt.
Usar el parámetro 'output' permite indicar el "grupo de captura" de la coincidencia que nos puede interesar.
Así, por ejemplo
log[/ruta/al/archivo,"large result buffer allocation.*Entries: ([0-9]+)",,,,\1]debería permitir devolver el recuento de entradas tal como se encuentra en el contenido de:
Fr Feb 07 2014 11:07:36.6690 */ Thread Id 1400 (GLEWF) large result
buffer allocation - /Length: 437136/Entries: 5948/Client Ver: >=10/RPC
ID: 41726453/User: AUser/Form: CFG:ServiceLevelAgreementSolo se devolverá el número porque \1 se refiere al primer y único grupo de captura: ([0-9]+).
Y, con la capacidad de extraer y devolver un número, el valor puede usarse para definir disparadores.
Uso del parámetro maxdelay
El parámetro maxdelay en los elementos de registro permite ignorar algunas líneas antiguas de los archivos de registro para que se analicen las líneas más recientes dentro de los segundos especificados en maxdelay.
Especificar 'maxdelay' > 0 puede llevar a ignorar registros importantes del archivo de registro y alertas perdidas. Úselo con cuidado y bajo su propio riesgo solo cuando sea necesario.
Por defecto, los elementos para la monitorización de registros siguen todas las nuevas líneas que aparecen en los archivos de registro.
Sin embargo, hay aplicaciones que en algunas situaciones comienzan a escribir una enorme cantidad de mensajes en sus archivos de registro.
Por ejemplo, si una base de datos o un servidor DNS no están disponibles, dichas aplicaciones saturan los archivos de registro con miles de mensajes de error casi idénticos hasta que se restablece el funcionamiento normal.
Por defecto, todos esos mensajes serán analizados y las líneas coincidentes enviadas al servidor según lo configurado en los elementos log y logrt.
La protección incorporada contra sobrecarga consiste en un parámetro configurable maxlines (protege al servidor de demasiadas líneas de registro coincidentes entrantes) y un límite de 10*'maxlines' (protege la CPU y E/S del host de sobrecargas por parte del agente en una comprobación).
Aun así, existen 2 problemas con la protección incorporada.
Primero, se informan al servidor una gran cantidad de mensajes potencialmente poco informativos que consumen espacio en la base de datos.
Segundo, debido al número limitado de líneas analizadas por segundo, el agente puede quedarse rezagado respecto a los registros más recientes durante horas.
Es muy probable que prefiera ser informado antes sobre la situación actual en los archivos de registro en lugar de revisar registros antiguos durante horas.
La solución a ambos problemas es usar el parámetro maxdelay.
Si se especifica maxdelay > 0, durante cada comprobación se mide el número de bytes procesados, el número de bytes restantes y el tiempo de procesamiento.
A partir de estos números, el agente calcula un retraso estimado: cuántos segundos tomaría analizar todos los registros restantes en un archivo de registro.
Si el retraso no supera maxdelay, el agente procede a analizar el archivo de registro como de costumbre.
Si el retraso es mayor que maxdelay, el agente ignora una parte del archivo de registro "saltando" sobre ella a una nueva posición estimada para que las líneas restantes puedan analizarse dentro de los segundos especificados en maxdelay.
Tenga en cuenta que el agente ni siquiera lee las líneas ignoradas en el búfer, sino que calcula una posición aproximada a la que saltar en el archivo.
El hecho de omitir líneas del archivo de registro se registra en el archivo de registro del agente de la siguiente manera:
14287:20160602:174344.206 item:"logrt["/home/zabbix32/test[0-9].log",ERROR,,1000,,,120.0]"
logfile:"/home/zabbix32/test1.log" skipping 679858 bytes
(from byte 75653115 to byte 76332973) to meet maxdelayEl número "to byte" es aproximado porque después del "salto" el agente ajusta la posición en el archivo al comienzo de una línea de registro, que puede estar más adelante o más atrás en el archivo.
Dependiendo de cómo se compare la velocidad de crecimiento con la velocidad de análisis del archivo de registro, puede que no vea "saltos", que los "saltos" sean raros o frecuentes, grandes o pequeños, o incluso un pequeño "salto" en cada comprobación. Las fluctuaciones en la carga del sistema y la latencia de la red también afectan el cálculo del retraso y, por lo tanto, el "salto" hacia adelante para mantenerse al día con el parámetro "maxdelay".
No se recomienda establecer maxdelay < intervalo de actualización (puede resultar en "saltos" pequeños y frecuentes).
Notas sobre el manejo de la rotación de archivos de registro 'copytruncate'
logrt con la opción copytruncate asume que diferentes archivos de registro tienen diferentes registros (al menos sus marcas de tiempo son diferentes), por lo tanto, los valores MD5 de los bloques iniciales (hasta los primeros 512 bytes) serán diferentes.
Dos archivos con los mismos valores MD5 de los bloques iniciales significa que uno de ellos es el original y el otro una copia.
logrt con la opción copytruncate se esfuerza por procesar correctamente las copias de archivos de registro sin informar duplicados.
Sin embargo, no se recomienda producir múltiples copias de archivos de registro con la misma marca de tiempo, rotar el archivo de registro con más frecuencia que el intervalo de actualización del elemento logrt[], o reiniciar el agente con frecuencia.
El agente intenta manejar todas estas situaciones razonablemente bien, pero no se pueden garantizar buenos resultados en todas las circunstancias.
Notas sobre archivos persistentes para métricas log*[]
Propósito de los archivos persistentes
Cuando se inicia el agente Zabbix, recibe una lista de comprobaciones activas del servidor o proxy de Zabbix. Para las métricas log*[], recibe el tamaño del registro procesado y la hora de modificación para determinar desde dónde comenzar la monitorización del archivo de registro. Dependiendo del tamaño real del archivo de registro y la hora de modificación informados por el sistema de archivos, el agente decide si continúa la monitorización del archivo de registro desde el tamaño procesado o si vuelve a analizar el archivo de registro desde el principio.
Un agente en ejecución mantiene un conjunto más amplio de atributos para rastrear todos los archivos de registro monitorizados entre comprobaciones. Este estado en memoria se pierde cuando se detiene el agente.
El nuevo parámetro opcional persistent_dir especifica un directorio para almacenar este estado de los elementos log[], log.count[], logrt[] o logrt.count[] en un archivo. El estado del elemento de registro se restaura desde el archivo persistente después de reiniciar el agente Zabbix.
El caso de uso principal es la monitorización de un archivo de registro ubicado en un sistema de archivos espejado. Hasta cierto momento, el archivo de registro se escribe en ambos espejos. Luego, los espejos se separan. En la copia activa, el archivo de registro sigue creciendo, recibiendo nuevos registros. El agente Zabbix lo analiza y envía el tamaño de los registros procesados y la hora de modificación al servidor. En la copia pasiva, el archivo de registro permanece igual, muy por detrás de la copia activa. Más tarde, el sistema operativo y el agente Zabbix se reinician desde la copia pasiva. El tamaño del registro procesado y la hora de modificación que el agente Zabbix recibe del servidor pueden no ser válidos para la situación en la copia pasiva. Para continuar la monitorización del archivo de registro desde el lugar donde el agente se detuvo en el momento de la separación del espejo del sistema de archivos, el agente restaura su estado desde el archivo persistente.
Funcionamiento del agente con archivo persistente
Al iniciar, el agente Zabbix no sabe nada sobre archivos persistentes. Solo después de recibir una lista de comprobaciones activas del servidor Zabbix (proxy), el agente ve que algunos elementos de registro deben estar respaldados por archivos persistentes en los directorios especificados.
Durante el funcionamiento del agente, los archivos persistentes se abren para escritura (con fopen(nombre_archivo, "w")) y se sobrescriben con los datos más recientes. La posibilidad de perder datos del archivo persistente si la sobrescritura y la separación del espejo del sistema de archivos ocurren al mismo tiempo es muy pequeña, no se realiza un manejo especial para ello. La escritura en el archivo persistente NO va seguida de una sincronización forzada con el medio de almacenamiento (no se llama a fsync()).
La sobrescritura con los datos más recientes se realiza después de informar con éxito el registro de archivo de registro coincidente o los metadatos (tamaño del registro procesado y hora de modificación) al servidor Zabbix. Eso puede ocurrir con tanta frecuencia como cada comprobación de elemento si el archivo de registro sigue cambiando.
No se realizan acciones especiales durante el apagado del agente.
Después de recibir una lista de comprobaciones activas, el agent marca los archivos persistentes obsoletos para su eliminación. Un archivo persistente se vuelve obsoleto si:
- El item de log correspondiente ya no se monitoriza.
- Un item de log se reconfigura con una ubicación persistent_dir diferente a la anterior.
La eliminación se realiza con un retraso de 24 horas porque los archivos de log en estado NOTSUPPORTED no se incluyen en la lista de comprobaciones activas, pero pueden pasar a ser SUPPORTED más tarde y sus archivos persistentes serán útiles.
Si el agent se detiene antes de que transcurran las 24 horas, los archivos obsoletos no se eliminarán, ya que el agent de Zabbix ya no recibe información sobre su ubicación desde el server de Zabbix.
Reconfigurar el persistent_dir de un item de log de nuevo a la ubicación anterior mientras el agent está detenido, sin eliminar el archivo persistente antiguo por parte del usuario, provocará que se restaure el estado del agent desde el archivo persistente antiguo, lo que dará lugar a mensajes perdidos o alertas falsas.
Nomenclatura y ubicación de archivos persistentes
El agente de Zabbix distingue las comprobaciones activas por sus claves. Por ejemplo, logrt[/home/zabbix/test.log] y logrt[/home/zabbix/test.log,] son elementos diferentes. Modificar el elemento logrt[/home/zabbix/test.log,,,10] en la interfaz a logrt[/home/zabbix/test.log,,,20] resultará en la eliminación del elemento logrt[/home/zabbix/test.log,,,10] de la lista de comprobaciones activas del agente y la creación del elemento logrt[/home/zabbix/test.log,,,20] (algunos atributos se mantienen durante la modificación en la interfaz/servidor, no en el agente).
El nombre del archivo se compone de la suma MD5 de la clave del elemento con la longitud de la clave del elemento añadida para reducir la posibilidad de colisiones. Por ejemplo, el estado del elemento logrt[/home/zabbix50/test.log,,,,,,,,/home/zabbix50/agent_private] se mantendrá en el archivo persistente c963ade4008054813bbc0a650bb8e09266.
Varios elementos de registro pueden usar el mismo valor de persistent_dir.
persistent_dir se especifica teniendo en cuenta diseños específicos del sistema de archivos, puntos de montaje y opciones de montaje y la configuración de replicación de almacenamiento: el archivo persistente debe estar en el mismo sistema de archivos replicado que el archivo de registro monitorizado.
Si el directorio persistent_dir no puede ser creado o no existe, o los derechos de acceso para el agente de Zabbix no permiten crear/escribir/leer/eliminar archivos, el elemento de registro se convierte en NO SOPORTADO.
Si se eliminan los derechos de acceso a los archivos de almacenamiento persistente durante el funcionamiento del agente o se producen otros errores (por ejemplo, disco lleno), los errores se registran en el archivo de registro del agente, pero el elemento de registro no pasa a ser NO SOPORTADO.
Carga en E/S
El archivo persistente del elemento se actualiza después de enviar con éxito cada lote de datos (que contiene los datos del elemento) al servidor.
Por ejemplo, el valor predeterminado de BufferSize es 100.
Si un elemento de registro ha encontrado 70 registros coincidentes, los primeros 50 registros se enviarán en un lote, se actualizará el archivo persistente, luego los 20 registros restantes se enviarán (tal vez con algún retraso cuando se acumule más información) en el segundo lote, y el archivo persistente se actualizará nuevamente.
Acciones si falla la comunicación entre el agente y el servidor
Cada línea coincidente de los elementos log[] y logrt[] y el resultado de cada comprobación de los elementos log.count[] y logrt.count[] requieren un espacio libre en el área designada del 50% en el búfer de envío del agente.
Los elementos del búfer se envían regularmente al servidor (o proxy) y los espacios del búfer vuelven a estar libres.
Mientras haya espacios libres en el área designada de registros en el búfer de envío del agente y falle la comunicación entre el agente y el servidor (o proxy), los resultados de la monitorización de registros se acumulan en el búfer de envío. Esto ayuda a mitigar fallos de comunicación breves.
Durante fallos de comunicación prolongados, todos los espacios de registro se ocupan y se toman las siguientes acciones:
- Se detienen las comprobaciones de los elementos
log[]ylogrt[]. Cuando se restablece la comunicación y hay espacios libres en el búfer, las comprobaciones se reanudan desde la posición anterior. No se pierden líneas coincidentes, simplemente se informan más tarde. - Las comprobaciones de
log.count[]ylogrt.count[]se detienen simaxdelay = 0(por defecto). El comportamiento es similar al de los elementoslog[]ylogrt[]como se describe arriba. Tenga en cuenta que esto puede afectar a los resultados delog.count[]ylogrt.count[]: por ejemplo, una comprobación cuenta 100 líneas coincidentes en un archivo de registro, pero como no hay espacios libres en el búfer, la comprobación se detiene. Cuando se restablece la comunicación, el agente cuenta las mismas 100 líneas coincidentes y también 70 nuevas líneas coincidentes. El agente ahora envía count = 170 como si se hubieran encontrado en una sola comprobación. - Comprobaciones de
log.count[]ylogrt.count[]conmaxdelay > 0: si no hubo un "salto" durante la comprobación, entonces el comportamiento es similar al descrito anteriormente. Si se produjo un "salto" sobre líneas del archivo de registro, entonces se mantiene la posición después del "salto" y se descarta el resultado contado. Por lo tanto, el agente intenta mantenerse al día con un archivo de registro en crecimiento incluso en caso de fallo de comunicación.
Manejo de errores de compilación y de ejecución de expresiones regulares
Si una expresión regular utilizada en los elementos log[], logrt[], log.count[] o logrt.count[] no puede ser compilada por la biblioteca PCRE o PCRE2, el elemento pasa al estado
NO SOPORTADO con un mensaje de error.
Para continuar monitoreando el elemento de log, se debe corregir la expresión regular.
Si la expresión regular se compila correctamente, pero falla en tiempo de ejecución (en algunos o en todos los registros de log), entonces el elemento de log permanece soportado y el monitoreo continúa. El error de ejecución se registra en el archivo de log del agente Zabbix (sin el registro del archivo de log).
La tasa de registro está limitada a un error de ejecución por verificación para permitir que el agente Zabbix monitoree su propio archivo de log. Por ejemplo, si se analizan 10 registros y 3 registros fallan con un error de ejecución de expresión regular, se produce un registro en el log del agente.
Excepción: si MaxLinesPerSecond=1 y el intervalo de actualización=1 (solo se permite analizar 1 registro por verificación), entonces los errores de ejecución de expresiones regulares no se registran.
zabbix_agentd registra la clave del elemento en caso de un error de ejecución, zabbix_agent2 registra el ID del elemento para ayudar a identificar qué elemento de log tiene errores de ejecución. Se recomienda rediseñar la expresión regular en caso de errores de ejecución.