
- 6 Monitoraggio del file di registro
- Panoramica
- Configurazione
- Note importanti
- Estrazione della parte corrispondente di un'espressione regolare
- Utilizzo del parametro maxdelay
- Note sulla gestione della rotazione dei file di log con 'copytruncate'
- Note sui file persistenti per gli elementi log*[].
- Azioni in caso di errore di comunicazione tra agent e server
- Gestione degli errori di compilazione e di esecuzione delle espressioni regolari
6 Monitoraggio del file di registro
Panoramica
Zabbix può essere utilizzato per il monitoraggio centralizzato e l’analisi dei file di log con o senza supporto per la rotazione dei log.
Le notifiche possono essere utilizzate per avvisare gli utenti quando un file di log contiene determinate stringhe o modelli di stringa.
Per monitorare un file di log è necessario disporre di:
- Zabbix agent in esecuzione sul host
- item di monitoraggio dei log configurato
Il limite di dimensione di un file di log monitorato dipende dal supporto per file di grandi dimensioni.
Configurazione
Verificare i parametri dell'agent
Assicurarsi che nel file di configurazione dell'agent:
- il parametro
Hostnamecorrisponda al nome del host nel frontend. - i server nel parametro
ServerActivesiano specificati per l'elaborazione dei controlli attivi.
Configurazione dell'item
Configurare un item di monitoraggio dei log.
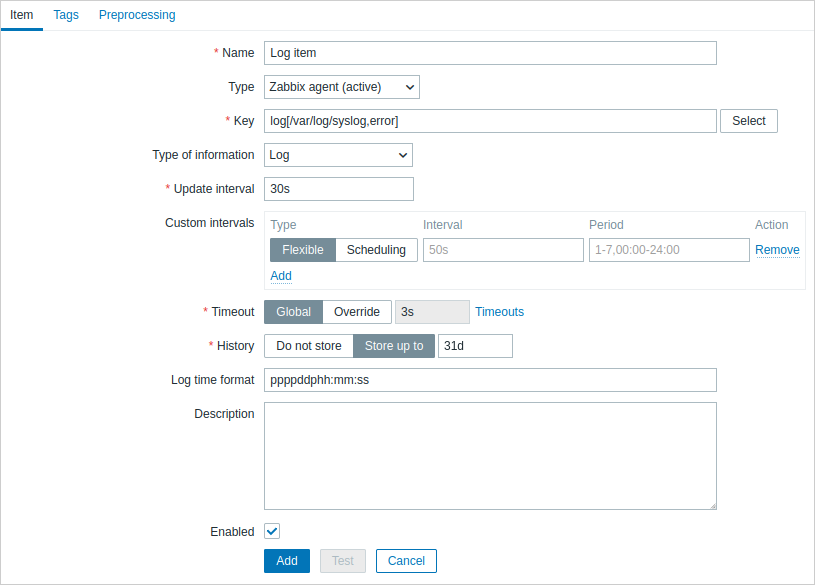
Tutti i campi di input obbligatori sono contrassegnati con un asterisco rosso.
In particolare, per gli item di monitoraggio dei log è necessario inserire:
| Type | Selezionare qui Zabbix agent (active). |
| Key | Utilizzare una delle seguenti chiavi item: log[] oppure logrt[]: Queste due chiavi item consentono di monitorare i log e filtrare le voci di log in base al regexp del contenuto, se presente. Ad esempio: log[/var/log/syslog,error]. Assicurarsi che il file abbia i permessi di lettura per l'utente 'zabbix', altrimenti lo stato dell'item verrà impostato su 'unsupported'.log.count[] oppure logrt.count[]: Queste due chiavi item consentono di restituire solo il numero di righe corrispondenti. Per i dettagli sull'utilizzo di queste chiavi item e dei relativi parametri, vedere la sezione delle chiavi Zabbix agent item supportate. |
| Type of information | Precompilato automaticamente: Per gli item log[] o logrt[] - Log;Per gli item log.count[] o logrt.count[] - Numeric (unsigned).Se si utilizza facoltativamente il parametro output, è possibile selezionare manualmente il tipo di informazioni appropriato diverso da Log.Si noti che la scelta di un tipo di informazioni diverso da Log comporterà la perdita del timestamp locale. |
| Update interval (in sec) | Il parametro definisce con quale frequenza Zabbix agent controllerà eventuali modifiche nel file di log. Impostandolo a 1 secondo si garantisce di ricevere i nuovi record il prima possibile. |
| Log time format | In questo campo è possibile specificare facoltativamente il modello per analizzare il timestamp della riga di log. Segnaposto supportati: * y: Anno (1970-2038) * M: Mese (01-12) * d: Giorno (01-31) * h: Ora (00-23) * m: Minuto (00-59) * s: Secondo (00-59) Se lasciato vuoto, il timestamp verrà impostato a 0 nel tempo Unix, che rappresenta il 1 gennaio 1970. Ad esempio, si consideri la seguente riga del file di log di Zabbix agent: " 23480:20100328:154718.045 Zabbix agent started. Zabbix 1.8.2 (revision 11211)." Inizia con sei posizioni di carattere per il PID, seguite da data, ora e dal resto del messaggio. Il formato dell'ora del log per questa riga sarebbe "pppppp:yyyyMMdd:hhmmss". Si noti che i caratteri "p" e ":" sono segnaposto e possono essere qualsiasi carattere eccetto "yMdhms". |
Note importanti
- Il server e l'agent mantengono traccia della dimensione di un log monitorato e dell'ora dell'ultima modifica (per logrt) in due contatori.
Inoltre:
- L'agent utilizza anche internamente i numeri inode (su UNIX/GNU/Linux), gli indici di file (su Microsoft Windows) e le somme MD5 dei primi 512 byte del file di log per migliorare le decisioni quando i file di log vengono troncati e ruotati.
- Sui sistemi UNIX/GNU/Linux si presume che i file system in cui sono archiviati i file di log riportino i numeri inode, che possono essere usati per tracciare i file.
- Su Microsoft Windows Zabbix agent determina il tipo di file system su cui risiedono i file di log e utilizza:
- Sui file system NTFS, indici di file a 64 bit.
- Sui file system ReFS (solo da Microsoft Windows Server 2012), ID file a 128 bit.
- Sui file system in cui gli indici di file cambiano (ad esempio FAT32, exFAT) viene utilizzato un algoritmo di fallback per adottare un approccio ragionevole in condizioni incerte quando la rotazione dei file di log produce più file di log con la stessa ora di ultima modifica.
- I numeri inode, gli indici di file e le somme MD5 vengono raccolti internamente da Zabbix agent. Non vengono trasmessi a Zabbix server e vengono persi quando Zabbix agent viene arrestato.
- Non modificare l'ora di ultima modifica di un file di log (ad esempio con
touch) e non sostituire un file di log monitorato copiando un file di nuovo nel suo nome originale (questo crea un nuovo inode). In entrambi i casi Zabbix potrebbe trattare il file come un file diverso e rileggerlo dall'inizio, il che può produrre avvisi duplicati. - Se ci sono diversi file di log corrispondenti per l'item
logrt[]e Zabbix agent sta seguendo il più recente tra essi e questo file di log più recente viene eliminato, viene registrato un messaggio di avviso"there are no files matching "<regexp mask>" in "<directory>". Zabbix agent ignora i file di log con ora di modifica inferiore all'ora di modifica più recente vista dall'agent per l'itemlogrt[]controllato.
- L'agent inizia a leggere il file di log dal punto in cui si era fermato la volta precedente.
- Il numero di byte già analizzati (il contatore della dimensione) e l'ora dell'ultima modifica (il contatore del tempo) sono memorizzati nel database Zabbix e vengono inviati all'agent per assicurarsi che l'agent inizi a leggere il file di log da questo punto nei casi in cui l'agent sia stato appena avviato o abbia ricevuto item che erano stati precedentemente disabilitati o non supportati. Tuttavia, se l'agent ha ricevuto dal server un contatore della dimensione diverso da zero, ma l'item logrt[] o logrt.count[] non riesce a trovare file corrispondenti, il contatore della dimensione viene reimpostato a 0 per analizzare dall'inizio se i file compaiono successivamente.
- Ogni volta che il file di log diventa più piccolo del contatore della dimensione del log noto all'agent, il contatore viene reimpostato a zero e l'agent inizia a leggere il file di log dall'inizio tenendo conto del contatore del tempo.
- Se nella directory ci sono diversi file corrispondenti con la stessa ora di ultima modifica, allora l'agent cerca di analizzare correttamente tutti i file di log con la stessa ora di modifica ed evitare di saltare dati o analizzare gli stessi dati due volte, anche se ciò non può essere garantito in tutte le situazioni. L'agent non presume alcuno schema particolare di rotazione dei file di log né ne determina uno. Quando gli vengono presentati più file di log con la stessa ora di ultima modifica, l'agent li elaborerà in ordine lessicografico decrescente. Pertanto, per alcuni schemi di rotazione i file di log verranno analizzati e segnalati nel loro ordine originale. Per altri schemi di rotazione l'ordine originale dei file di log non verrà rispettato, il che può portare alla segnalazione dei record dei file di log corrispondenti in ordine alterato (il problema non si verifica se i file di log hanno ore di ultima modifica diverse).
- Zabbix agent elabora i nuovi record di un file di log una volta ogni Intervallo di aggiornamento secondi.
- Zabbix agent non invia più di maxlines di un file di log al secondo. Il limite impedisce il sovraccarico delle risorse di rete e CPU e sovrascrive il valore predefinito fornito dal parametro MaxLinesPerSecond nel file di configurazione dell'agent.
- Per trovare la stringa richiesta Zabbix elaborerà 10 volte più nuove righe di quelle impostate in MaxLinesPerSecond.
Pertanto, ad esempio, se un item
log[]ologrt[]ha un Intervallo di aggiornamento di 1 secondo, per impostazione predefinita l'agent analizzerà non più di 200 record del file di log e invierà non più di 20 record corrispondenti a Zabbix server in un controllo. Aumentando MaxLinesPerSecond nel file di configurazione dell'agent o impostando il parametro maxlines nella chiave dell'item, il limite può essere aumentato fino a 10000 record del file di log analizzati e 1000 record corrispondenti inviati a Zabbix server in un controllo. Se l'Intervallo di aggiornamento è impostato su 2 secondi, i limiti per un controllo saranno 2 volte più alti rispetto a un Intervallo di aggiornamento di 1 secondo. - Inoltre, i valori log e log.count sono sempre limitati al 50% della dimensione del buffer di invio dell'agent, anche se non ci sono valori non-log al suo interno. Quindi, affinché i valori maxlines vengano inviati in una connessione (e non in più connessioni), il parametro BufferSize dell'agent deve essere almeno maxlines x 2. Zabbix agent può caricare i dati durante la raccolta dei log e quindi liberare il buffer, mentre Zabbix agent 2 interromperà la raccolta dei log finché i dati non saranno caricati e il buffer non sarà liberato, operazione eseguita in modo asincrono.
- In assenza di item di log, tutta la dimensione del buffer dell'agent viene utilizzata per valori non-log. Quando arrivano valori di log, questi sostituiscono i valori non-log più vecchi secondo necessità, fino al 50% designato.
- Per record di file di log più lunghi di 256kB, solo i primi 256kB vengono confrontati con l'espressione regolare e il resto del record viene ignorato. Tuttavia, se Zabbix agent viene arrestato mentre sta gestendo un record lungo, lo stato interno dell'agent viene perso e il record lungo può essere analizzato di nuovo e in modo diverso dopo il riavvio dell'agent.
- Nota speciale per i separatori di percorso "\": se file_format è "file\.log", allora non dovrebbe esserci una directory "file", poiché non è possibile definire in modo univoco se "." è preceduto da escape o è il primo simbolo del nome del file.
- Le espressioni regolari per
logrtsono supportate solo nel nome file; la corrispondenza tramite espressione regolare della directory non è supportata. - Sulle piattaforme UNIX un item
logrt[]diventa NOTSUPPORTED se una directory in cui si prevede di trovare i file di log non esiste. - Su Microsoft Windows, se una directory non esiste l'item non diventerà NOTSUPPORTED (ad esempio, se il nome della directory è scritto in modo errato nella chiave dell'item).
- L'assenza di file di log per l'item
logrt[]non lo rende NOTSUPPORTED. Gli errori di lettura dei file di log per l'itemlogrt[]vengono registrati come avvisi nel file di log di Zabbix agent ma non rendono l'item NOTSUPPORTED. - Il file di log di Zabbix agent può essere utile per capire perché un item
log[]ologrt[]è diventato NOTSUPPORTED. Zabbix può monitorare il proprio file di log dell'agent, tranne quando DebugLevel=4 o DebugLevel=5. - La ricerca di un punto interrogativo usando un'espressione regolare, ad esempio
\?, può produrre falsi positivi se il file di testo contiene simboli NUL, poiché questi vengono sostituiti con "?" da Zabbix per continuare l'elaborazione della riga fino al carattere di nuova riga.
Estrazione della parte corrispondente di un'espressione regolare
A volte potremmo voler estrarre solo il valore di interesse da un file di destinazione invece di restituire l'intera riga quando viene trovata una corrispondenza con un'espressione regolare.
Gli item di log hanno la capacità di estrarre i valori desiderati dalle righe corrispondenti.
Ciò viene ottenuto tramite il parametro aggiuntivo output negli item log e logrt.
L'uso del parametro 'output' consente di indicare il "gruppo di cattura" della corrispondenza che potrebbe interessarci.
Quindi, per esempio
log[/path/to/the/file,"large result buffer allocation.*Entries: ([0-9]+)",,,,\1]dovrebbe consentire di restituire il conteggio delle voci come trovato nel contenuto di:
Fr Feb 07 2014 11:07:36.6690 */ Thread Id 1400 (GLEWF) large result
buffer allocation - /Length: 437136/Entries: 5948/Client Ver: >=10/RPC
ID: 41726453/User: AUser/Form: CFG:ServiceLevelAgreementVerrà restituito solo il numero perché \1 si riferisce al primo e unico gruppo di cattura: ([0-9]+).
Inoltre, grazie alla possibilità di estrarre e restituire un numero, il valore può essere utilizzato per definire trigger.
Utilizzo del parametro maxdelay
Il parametro maxdelay negli item di log consente di ignorare alcune righe meno recenti dei file di log per fare in modo che vengano analizzate le righe più recenti entro i maxdelay secondi.
Specificare maxdelay > 0 può portare a ignorare record importanti del file di log e a perdere avvisi.
Usarlo con cautela, a proprio rischio, solo quando necessario.
Per impostazione predefinita, gli item per il monitoraggio dei log seguono tutte le nuove righe che compaiono nei file di log.
Tuttavia, esistono applicazioni che in alcune situazioni iniziano a scrivere un numero enorme di messaggi nei propri file di log.
Ad esempio, se un database o un server DNS non è disponibile, tali applicazioni inondano i file di log con migliaia di messaggi di errore quasi identici finché il normale funzionamento non viene ripristinato.
Per impostazione predefinita, tutti questi messaggi verranno diligentemente analizzati e le righe corrispondenti verranno inviate al server come configurato negli item log e logrt.
La protezione integrata contro il sovraccarico consiste in un parametro maxlines configurabile (protegge il server da troppe righe di log corrispondenti in arrivo) e in un limite di 10*maxlines (protegge CPU e I/O dell'host dal sovraccarico causato dall'agent in un singolo controllo).
Tuttavia, la protezione integrata presenta ancora 2 problemi.
Primo, un gran numero di messaggi potenzialmente poco informativi viene segnalato al server e occupa spazio nel database.
Secondo, a causa del numero limitato di righe analizzate al secondo, l'agent può rimanere indietro rispetto ai record di log più recenti per ore.
Molto probabilmente, si preferisce essere informati prima sulla situazione corrente nei file di log invece di scorrere vecchi record per ore.
La soluzione a entrambi i problemi è usare il parametro maxdelay.
Se viene specificato maxdelay > 0, durante ogni controllo vengono misurati il numero di byte elaborati, il numero di byte rimanenti e il tempo di elaborazione.
Da questi valori l'agent calcola un ritardo stimato, cioè quanti secondi sarebbero necessari per analizzare tutti i record rimanenti in un file di log.
Se il ritardo non supera maxdelay, l'agent procede con l'analisi del file di log come di consueto.
Se il ritardo è maggiore di maxdelay, allora l'agent ignora una porzione del file di log "saltandola" fino a una nuova posizione stimata, in modo che le righe rimanenti possano essere analizzate entro maxdelay secondi.
Si noti che l'agent non legge nemmeno le righe ignorate nel buffer, ma calcola una posizione approssimativa a cui saltare nel file.
Il fatto che vengano saltate righe del file di log viene registrato nel file di log dell'agent in questo modo:
14287:20160602:174344.206 item:"logrt["/home/zabbix32/test[0-9].log",ERROR,,1000,,,120.0]"
logfile:"/home/zabbix32/test1.log" skipping 679858 bytes
(from byte 75653115 to byte 76332973) to meet maxdelayIl numero "to byte" è approssimativo perché dopo il "salto" l'agent regola la posizione nel file all'inizio di una riga di log, che può trovarsi più avanti nel file oppure prima.
A seconda di come la velocità di crescita si confronta con la velocità di analisi del file di log, si possono osservare nessun "salto", "salti" rari o frequenti, "salti" grandi o piccoli, oppure persino un piccolo "salto" a ogni controllo.
Anche le fluttuazioni del carico di sistema e della latenza di rete influiscono sul calcolo del ritardo e quindi sul "saltare" in avanti per rispettare il parametro maxdelay.
Non è consigliato impostare maxdelay < update interval (potrebbe causare frequenti piccoli "salti").
Note sulla gestione della rotazione dei file di log con 'copytruncate'
logrt con l'opzione copytruncate presuppone che file di log diversi contengano record diversi (almeno i loro timestamp siano diversi), pertanto le somme MD5 dei blocchi iniziali (fino ai primi 512 byte) saranno diverse.
Due file con le stesse somme MD5 dei blocchi iniziali significano che uno di essi è l'originale, l'altro è una copia.
logrt con l'opzione copytruncate cerca di elaborare correttamente le copie dei file di log senza segnalare duplicati.
Tuttavia, non è consigliato, ad esempio, produrre più copie del file di log con lo stesso timestamp, eseguire la rotazione del file di log più frequentemente dell'intervallo di aggiornamento dell'item logrt[], o riavviare spesso l'agent.
L'agent cerca di gestire tutte queste situazioni in modo ragionevolmente corretto, ma non è possibile garantire buoni risultati in tutte le circostanze.
Note sui file persistenti per gli elementi log*[].
Scopo dei file persistenti
Quando Zabbix agent viene avviato, riceve un elenco di controlli attivi da Zabbix server o proxy. Per le metriche log*[] riceve la dimensione del log elaborato e l'ora di modifica per determinare da dove iniziare il monitoraggio del file di log. In base alla dimensione effettiva del file di log e all'ora di modifica riportata dal file system, l'agent decide se continuare il monitoraggio del file di log dalla dimensione del log elaborato oppure riesaminare il file di log dall'inizio.
Un agent in esecuzione mantiene un insieme più ampio di attributi per tracciare tutti i file di log monitorati tra un controllo e l'altro. Questo stato in memoria viene perso quando l'agent viene arrestato.
Il nuovo parametro opzionale persistent_dir specifica una directory in cui memorizzare in un file questo stato dell'item log[], log.count[], logrt[] o logrt.count[]. Lo stato dell'item di log viene ripristinato dal file persistente dopo il riavvio di Zabbix agent.
Il caso d'uso principale è il monitoraggio di un file di log situato su un file system mirrorato. Fino a un certo momento, il file di log viene scritto su entrambe le copie mirrorate. Successivamente, i mirror vengono separati. Sulla copia attiva il file di log continua a crescere, ricevendo nuovi record. Zabbix agent lo analizza e invia a server la dimensione dei log elaborati e l'ora di modifica. Sulla copia passiva il file di log rimane invariato, molto indietro rispetto alla copia attiva. In seguito, il sistema operativo e Zabbix agent vengono riavviati dalla copia passiva. La dimensione del log elaborato e l'ora di modifica che Zabbix agent riceve da server potrebbero non essere validi per la situazione sulla copia passiva. Per continuare il monitoraggio del file di log dal punto in cui l'agent si era fermato al momento della separazione del mirror del file system, l'agent ripristina il proprio stato dal file persistente.
Funzionamento dell'agent con file persistente
All'avvio, Zabbix agent non sa nulla dei file persistenti. Solo dopo aver ricevuto un elenco di controlli attivi da Zabbix server (proxy), l'agent vede che alcuni item di log devono essere supportati da file persistenti nelle directory specificate.
Durante il funzionamento dell'agent, i file persistenti vengono aperti in scrittura (con fopen(filename, "w")) e sovrascritti con i dati più recenti. La probabilità di perdere i dati del file persistente se la sovrascrittura e la separazione del mirror del file system avvengono contemporaneamente è molto bassa; non è prevista alcuna gestione speciale per questo caso. La scrittura nel file persistente NON è seguita da una sincronizzazione forzata sul supporto di memorizzazione (fsync() non viene chiamato).
La sovrascrittura con i dati più recenti viene eseguita dopo la corretta segnalazione a Zabbix server del record del file di log corrispondente o dei metadati (dimensione del log elaborato e ora di modifica). Ciò può avvenire con una frequenza pari a ogni controllo dell'item, se il file di log continua a cambiare.
Non sono previste azioni speciali durante l'arresto dell'agent.
Dopo aver ricevuto un elenco di controlli attivi, l'agent contrassegna i file persistenti obsoleti per la rimozione. Un file persistente diventa obsoleto se:
- Il corrispondente item di log non è più monitorato.
- Un item di log viene riconfigurato con una posizione persistent_dir diversa da quella precedente.
La rimozione viene eseguita con un ritardo di 24 ore perché i file di log nello stato NOTSUPPORTED non sono inclusi nell'elenco dei controlli attivi, ma potrebbero diventare SUPPORTED in seguito e i loro file persistenti potrebbero risultare utili.
Se l'agent viene arrestato prima che siano trascorse 24 ore, i file obsoleti non verranno eliminati, poiché Zabbix agent non riceve più dal Zabbix server informazioni sulla loro posizione.
Riconfigurare persistent_dir di un item di log riportandolo alla vecchia posizione persistent_dir mentre l'agent è arrestato, senza che l'utente elimini il vecchio file persistente, causerà il ripristino dello stato dell'agent dal vecchio file persistente, con conseguenti messaggi mancati o falsi avvisi.
Denominazione e posizione dei file persistenti
Zabbix agent distingue i controlli attivi in base alle loro chiavi. Ad esempio, logrt[/home/zabbix/test.log] e logrt[/home/zabbix/test.log,] sono item diversi. La modifica dell'item logrt[/home/zabbix/test.log,,,10] nel frontend in logrt[/home/zabbix/test.log,,,20] comporterà l'eliminazione dell'item logrt[/home/zabbix/test.log,,,10] dall'elenco dei controlli attivi dell'agent e la creazione dell'item logrt[/home/zabbix/test.log,,,20] (alcuni attributi vengono mantenuti durante la modifica nel frontend/server, non nell'agent).
Il nome del file è composto dalla somma MD5 della chiave dell'item con la lunghezza della chiave dell'item aggiunta per ridurre la possibilità di collisioni. Ad esempio, lo stato dell'item logrt[/home/zabbix50/test.log,,,,,,,,/home/zabbix50/agent_private] verrà mantenuto nel file persistente c963ade4008054813bbc0a650bb8e09266.
Più item di log possono utilizzare lo stesso valore di persistent_dir.
persistent_dir viene specificato tenendo conto di layout specifici del file system, punti di mount, opzioni di mount e configurazione del mirroring dello storage: il file persistente deve trovarsi nello stesso file system con mirroring del file di log monitorato.
Se la directory persistent_dir non può essere creata o non esiste, oppure se i diritti di accesso per Zabbix agent non consentono di creare/scrivere/leggere/eliminare file, l'item di log diventa NOTSUPPORTED.
Se i diritti di accesso ai file di archiviazione persistente vengono rimossi durante il funzionamento dell'agent o si verificano altri errori (ad esempio, disco pieno), gli errori vengono registrati nel file di log dell'agent, ma il log item non diventa NOTSUPPORTED.
Carico su I/O
Il file persistente dell'item viene aggiornato dopo l'invio riuscito di ogni batch di dati (contenente i dati dell'item) al server.
Ad esempio, il valore predefinito di BufferSize è 100.
Se un item di log trova 70 record corrispondenti, i primi 50 record verranno inviati in un batch, il file persistente verrà aggiornato, quindi i restanti 20 record verranno inviati (eventualmente con un certo ritardo, quando verranno accumulati più dati) nel secondo batch, e il file persistente verrà aggiornato di nuovo.
Azioni in caso di errore di comunicazione tra agent e server
Ogni riga corrispondente degli item log[] e logrt[] e ogni risultato di controllo degli item log.count[] e logrt.count[] richiede uno slot libero nell'area dedicata del 50% nel buffer di invio dell'agent.
Gli elementi del buffer vengono inviati regolarmente al server (o proxy) e gli slot del buffer tornano nuovamente liberi.
Finché ci sono slot liberi nell'area log designata del buffer di invio dell'agent e la comunicazione tra agent e server (o proxy) non riesce, i risultati del monitoraggio dei log vengono accumulati nel buffer di invio. Questo aiuta a mitigare brevi interruzioni della comunicazione.
Durante interruzioni della comunicazione più lunghe, tutti gli slot log vengono occupati e vengono intraprese le seguenti azioni:
- I controlli degli item
log[]elogrt[]vengono arrestati. Quando la comunicazione viene ripristinata e sono disponibili slot liberi nel buffer, i controlli riprendono dalla posizione precedente. Nessuna riga corrispondente viene persa, viene solo segnalata più tardi. - I controlli
log.count[]elogrt.count[]vengono arrestati semaxdelay = 0(predefinito). Il comportamento è simile a quello degli itemlog[]elogrt[]come descritto sopra. Si noti che questo può influire sui risultati dilog.count[]elogrt.count[]: ad esempio, un controllo conta 100 righe corrispondenti in un file di log, ma poiché non ci sono slot liberi nel buffer il controllo viene arrestato. Quando la comunicazione viene ripristinata, l'agent conta le stesse 100 righe corrispondenti e anche 70 nuove righe corrispondenti. L'agent ora invia count = 170 come se fossero state trovate in un unico controllo. - Controlli
log.count[]elogrt.count[]conmaxdelay > 0: se durante il controllo non si è verificato alcun "salto", il comportamento è simile a quello descritto sopra. Se si è verificato un "salto" sulle righe del file di log, allora viene mantenuta la posizione successiva al "salto" e il risultato conteggiato viene scartato. In questo modo, l'agent cerca di stare al passo con un file di log in crescita anche in caso di errore di comunicazione.
Gestione degli errori di compilazione e di esecuzione delle espressioni regolari
Se un'espressione regolare utilizzata in un item log[], logrt[], log.count[] o logrt.count[] non può essere compilata dalla libreria PCRE o PCRE2, l'item passa allo stato
NOTSUPPORTED con un messaggio di errore.
Per continuare il monitoraggio dell'item di log, l'espressione regolare deve essere corretta.
Se l'espressione regolare viene compilata correttamente, ma fallisce in fase di esecuzione (su alcuni o su tutti i record di log), allora l'item di log rimane supportato e il monitoraggio continua. L'errore di esecuzione viene registrato nel file di log dello Zabbix agent (senza il record del file di log).
La frequenza di registrazione è limitata a un errore di esecuzione per controllo, per consentire allo Zabbix agent di monitorare il proprio file di log. Ad esempio, se vengono analizzati 10 record e 3 record falliscono con un errore di esecuzione della regexp, nel log dell'agent viene prodotto un record.
Eccezione: se MaxLinesPerSecond=1 e l'intervallo di aggiornamento=1 (è consentito analizzare un solo record per controllo), gli errori di esecuzione della regexp non vengono registrati.
zabbix_agentd registra la chiave dell'item in caso di errore di esecuzione, zabbix_agent2 registra l'ID dell'item per aiutare a identificare quale item di log presenta errori di esecuzione. In caso di errori di esecuzione, si consiglia di riprogettare l'espressione regolare.