
3 Individuazione di basso livello
Panoramica
La discovery a basso livello (LLD) rileva automaticamente le entità (ad esempio, file system, interfacce di rete) su un host e crea i corrispondenti item, trigger e grafici senza configurazione manuale per ciascuno.
Per usare LLD, si crea una regola di discovery che raccoglie dati JSON che descrivono le entità e dei prototype (item, trigger e grafico) per ogni entità.
Il JSON restituito dalla regola deve essere un array di oggetti, in cui ogni oggetto rappresenta una singola entità rilevata tramite coppie chiave-valore. Ad esempio, una regola di discovery con net.if.discovery potrebbe restituire:
[
{"{#IFNAME}": "lo"},
{"{#IFNAME}": "eth0"}
]Da questo insieme di prototype viene quindi creato un corrispondente set di item, trigger e grafici: uno per ogni interfaccia (lo e eth0).
Se gli oggetti contengono chiavi nel formato {#MACRO}, tali macro vengono usate direttamente nei prototype. In caso contrario, oppure se sono necessarie macro aggiuntive/personalizzate, le macro possono essere definite manualmente e mappate ai campi JSON tramite JSONPath.
LLD può anche creare host (ad esempio, per macchine virtuali rilevate su un hypervisor) e supporta regole di discovery annidate per la discovery multilivello.
Le entità che non vengono più rilevate possono essere automaticamente disabilitate o eliminate.
Configurazione della discovery a basso livello
Illustreremo la discovery a basso livello con un esempio di discovery del file system.
Per configurare la discovery, procedere come segue:
- Andare in Data collection > Templates o Hosts.
- Fare clic su Discovery nella riga del template/host appropriato.

- Fare clic su Create discovery rule nell'angolo in alto a destra della schermata.
- Compilare il modulo della regola di discovery con i dettagli richiesti.
Regola di individuazione
Il modulo della regola di individuazione contiene cinque schede che rappresentano, da sinistra a destra, il flusso dei dati durante l'individuazione:
- Regola di individuazione - specifica, soprattutto, l'item integrato o lo script personalizzato per recuperare i dati di individuazione.
- Preprocessing - applica un certo preprocessing ai dati individuati.
- Macro LLD - consente di estrarre alcuni valori di macro da utilizzare negli item, trigger, ecc. individuati.
- Filtri - consente di filtrare i valori individuati.
- Override - consente di modificare item, trigger, grafici o prototipi di host quando vengono applicati a specifici oggetti individuati.
La scheda Regola di individuazione contiene la chiave item da utilizzare per l'individuazione (oltre ad alcuni attributi generali della regola di individuazione):
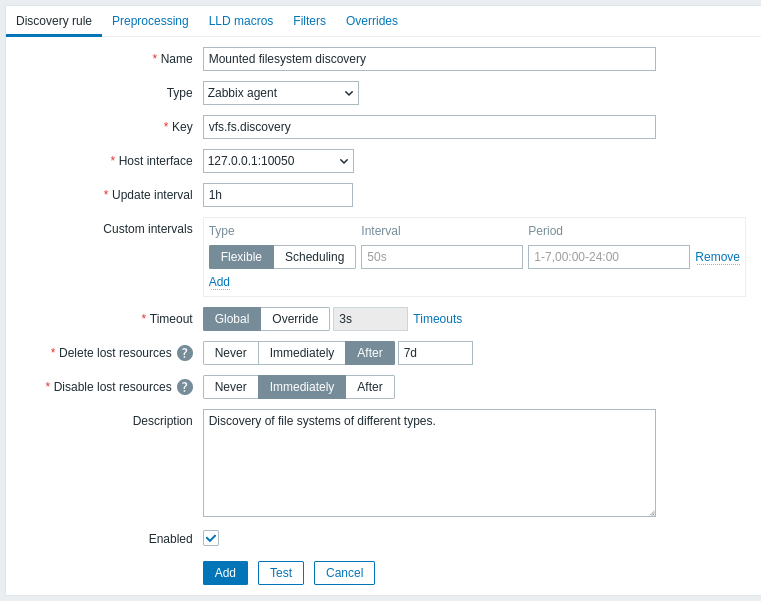
Tutti i campi di input obbligatori sono contrassegnati da un asterisco rosso.
| Parameter | Description |
|---|---|
| Name | Nome della regola di individuazione. |
| Type | Il tipo di controllo per eseguire l'individuazione. In questo esempio stiamo utilizzando un tipo di item Zabbix agent. La regola di individuazione può anche essere un item dipendente, in dipendenza da un item normale. Non può dipendere da un'altra regola di individuazione. Per un item dipendente, selezionare il tipo corrispondente (Item dipendente) e specificare il master item nel campo 'Master item'. Il master item deve esistere. |
| Key | Inserire la chiave item di individuazione (fino a 2048 caratteri). Ad esempio, è possibile utilizzare la chiave item integrata "vfs.fs.discovery" per restituire una stringa JSON con l'elenco dei file system presenti sul computer, i relativi tipi e le opzioni di mount. Si noti che un'altra opzione per l'individuazione del filesystem consiste nell'utilizzare i risultati di individuazione tramite la chiave agent "vfs.fs.get" (vedere esempio). |
| Update interval | Questo campo specifica con quale frequenza Zabbix esegue l'individuazione. All'inizio, quando si sta appena configurando l'individuazione del file system, si potrebbe voler impostare un intervallo breve, ma una volta verificato che funziona è possibile impostarlo a 30 minuti o più, perché i file system di solito non cambiano molto spesso. Sono supportati i suffissi temporali, ad esempio 30s, 1m, 2h, 1d. Sono supportate le macro utente. Nota: l'intervallo di aggiornamento può essere impostato su '0' solo se esistono intervalli personalizzati con un valore diverso da zero. Se impostato su '0' e se esiste un intervallo personalizzato (flessibile o pianificato) con un valore diverso da zero, l'item verrà interrogato durante la durata dell'intervallo personalizzato. Le nuove regole di individuazione verranno controllate entro 60 secondi dalla loro creazione, a meno che non abbiano una pianificazione o un intervallo di aggiornamento flessibile e Update interval sia impostato su 0. Nota che per una regola di individuazione esistente l'individuazione può essere eseguita immediatamente premendo il pulsante Execute now. |
| Custom intervals | È possibile creare regole personalizzate per il controllo dell'item: Flexible - crea un'eccezione a Update interval (intervallo con frequenza diversa) Scheduling - crea una pianificazione di polling personalizzata. Per informazioni dettagliate vedere Intervalli personalizzati. |
| Timeout | Impostare il timeout del controllo di individuazione. Selezionare l'opzione di timeout: Global - viene utilizzato il timeout proxy/globale (visualizzato nel campo Timeout in grigio); Override - viene utilizzato un timeout personalizzato (impostato nel campo Timeout; intervallo consentito: 1 - 600s). Sono supportati i suffissi temporali, ad esempio 30s, 1m, e le macro utente. Facendo clic sul collegamento Timeouts è possibile configurare i timeout del proxy o i timeout globali (se non viene utilizzato un proxy). Si noti che il collegamento Timeouts è visibile solo agli utenti di tipo Super admin con autorizzazioni per le sezioni frontend Administration > General o Administration > Proxies. |
| Delete lost resources | Specificare dopo quanto tempo l'entità individuata verrà eliminata una volta che il suo stato di individuazione diventa "Non più individuata": Never - non verrà eliminata; Immediately - verrà eliminata immediatamente; After - verrà eliminata dopo il periodo di tempo specificato. Il valore deve essere maggiore del valore di Disable lost resources. Sono supportati i suffissi temporali, ad esempio 2h, 1d. Sono supportate le macro utente. Nota: l'uso di "Immediately" non è consigliato, poiché una semplice modifica errata del filtro potrebbe comportare l'eliminazione dell'entità con tutti i dati storici. Si noti che le risorse disabilitate manualmente non verranno eliminate dal low-level discovery. |
| Disable lost resources | Specificare dopo quanto tempo l'entità individuata verrà disabilitata una volta che il suo stato di individuazione diventa "Non più individuata": Never - non verrà disabilitata; Immediately - verrà disabilitata immediatamente; After - verrà disabilitata dopo il periodo di tempo specificato. Il valore deve essere maggiore dell'intervallo di aggiornamento della regola di individuazione. Si noti che le risorse disabilitate automaticamente verranno nuovamente abilitate se vengono riscoperte dal low-level discovery. Le risorse disabilitate manualmente non verranno nuovamente abilitate se riscoperte. Questo campo non viene visualizzato se Delete lost resources è impostato su "Immediately". Sono supportati i suffissi temporali, ad esempio 2h, 1d. Sono supportate le macro utente. |
| Description | Inserire una descrizione. |
| Enabled | Se selezionato, la regola verrà elaborata. |
La cronologia della regola di individuazione non viene conservata.
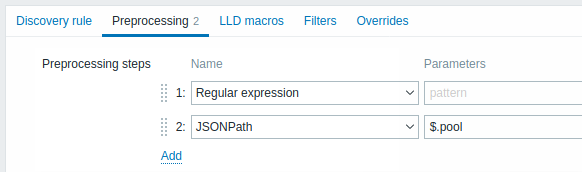
Preprocessing
La scheda Preprocessing consente di definire regole di trasformazione da applicare al risultato della discovery. In questa fase sono possibili una o più trasformazioni. Le trasformazioni vengono eseguite nell'ordine in cui sono definite. Tutto il preprocessing viene eseguito da Zabbix server.
Vedi anche:
| Type | ||
|---|---|---|
| Transformation | Description | |
| Text | ||
| Regular expression | Confronta il valore ricevuto con l'espressione regolare <pattern> e sostituisce il valore con il <output> estratto. L'espressione regolare supporta l'estrazione di un massimo di 10 gruppi catturati con la sequenza \N. Parameters: pattern - espressione regolare output - template di formattazione dell'output. Una sequenza di escape \N (dove N=1…9) viene sostituita con il gruppo corrispondente N-esimo. Una sequenza di escape \0 viene sostituita con il testo corrispondente. Se si seleziona la casella Custom on fail, è possibile specificare opzioni personalizzate di gestione dell'errore: scartare il valore, impostare un valore specificato oppure impostare un messaggio di errore specificato. |
|
| Replace | Trova la stringa di ricerca e sostituiscila con un'altra (o con nulla). Tutte le occorrenze della stringa di ricerca verranno sostituite. Parameters: search string - la stringa da trovare e sostituire, con distinzione tra maiuscole e minuscole (obbligatorio) replacement - la stringa con cui sostituire la stringa di ricerca. La stringa di sostituzione può anche essere vuota, consentendo di fatto di eliminare la stringa di ricerca quando viene trovata. È possibile usare sequenze di escape per cercare o sostituire interruzioni di riga, ritorni a capo, tabulazioni e spazi "\n \r \t \s"; il backslash può essere escapato come "\\" e le sequenze di escape possono essere escapate come "\\n". L'escape di interruzioni di riga, ritorni a capo e tabulazioni viene eseguito automaticamente durante la low-level discovery. |
|
| Structured data | ||
| JSONPath | Estrae un valore o un frammento dai dati JSON usando la funzionalità JSONPath. Se si seleziona la casella Custom on fail, è possibile specificare opzioni personalizzate di gestione dell'errore: scartare il valore, impostare un valore specificato oppure impostare un messaggio di errore specificato. |
|
| XML XPath | Estrae un valore o un frammento dai dati XML usando la funzionalità XPath. Perché questa opzione funzioni, Zabbix server deve essere compilato con il supporto libxml. Esempi: number(/document/item/value) estrarrà 10 da <document><item><value>10</value></item></document>number(/document/item/@attribute) estrarrà 10 da <document><item attribute="10"></item></document>/document/item estrarrà <item><value>10</value></item> da <document><item><value>10</value></item></document>Nota che i namespace non sono supportati. Se si seleziona la casella Custom on fail, è possibile specificare opzioni personalizzate di gestione dell'errore: scartare il valore, impostare un valore specificato oppure impostare un messaggio di errore specificato. |
|
| CSV to JSON | Converte i dati di un file CSV in formato JSON. Per ulteriori informazioni, vedere: CSV to JSON preprocessing. |
|
| XML to JSON | Converte i dati in formato XML in JSON. Per ulteriori informazioni, vedere: Regole di serializzazione. Se si seleziona la casella Custom on fail, è possibile specificare opzioni personalizzate di gestione dell'errore: scartare il valore, impostare un valore specificato oppure impostare un messaggio di errore specificato. |
|
| SNMP | ||
| SNMP walk value | Estrae il valore tramite l'OID/nome MIB specificato e applica le opzioni di formattazione: Unchanged - restituisce Hex-STRING come stringa esadecimale non escapata (nota che i display hints vengono comunque applicati); UTF-8 from Hex-STRING - converte Hex-STRING in una stringa UTF-8; MAC from Hex-STRING - converte Hex-STRING in una stringa di indirizzo MAC (in cui ' ' viene sostituito da ':');Integer from BITS - converte i primi 8 byte di una stringa di bit espressa come sequenza di caratteri esadecimali (ad esempio "1A 2B 3C 4D") in un intero senza segno a 64 bit. Nelle stringhe di bit più lunghe di 8 byte, i byte successivi verranno ignorati. Se si seleziona la casella Custom on fail, è possibile specificare opzioni personalizzate di gestione dell'errore: scartare il valore, impostare un valore specificato oppure impostare un messaggio di errore specificato. |
|
| SNMP walk to JSON | Converte i valori SNMP in JSON. Specifica un nome di campo nel JSON e il corrispondente percorso SNMP OID. I valori dei campi verranno popolati con i valori nel percorso SNMP OID specificato. Puoi usare questo passaggio di preprocessing per SNMP OID discovery. Sono disponibili opzioni di formattazione del valore simili a quelle del passaggio SNMP walk value. Se si seleziona la casella Custom on fail, è possibile specificare opzioni personalizzate di gestione dell'errore: scartare il valore, impostare un valore specificato oppure impostare un messaggio di errore specificato. |
|
| SNMP get value | Applica opzioni di formattazione al valore SNMP get: UTF-8 from Hex-STRING - converte Hex-STRING in una stringa UTF-8; MAC from Hex-STRING - converte Hex-STRING in una stringa di indirizzo MAC (in cui ' ' viene sostituito da ':');Integer from BITS - converte i primi 8 byte di una stringa di bit espressa come sequenza di caratteri esadecimali (ad esempio "1A 2B 3C 4D") in un intero senza segno a 64 bit. Nelle stringhe di bit più lunghe di 8 byte, i byte successivi verranno ignorati. Se si seleziona la casella Custom on fail, è possibile specificare opzioni personalizzate di gestione dell'errore: scartare il valore, impostare un valore specificato oppure impostare un messaggio di errore specificato. |
|
| Custom scripts | ||
| JavaScript | Inserisci il codice JavaScript nell'editor modale che si apre facendo clic nel campo del parametro o sull'icona a forma di matita accanto ad esso. Nota che la lunghezza disponibile del JavaScript dipende dal database utilizzato. Per ulteriori informazioni, vedere: Javascript preprocessing |
|
| Validation | ||
| Does not match regular expression | Specifica un'espressione regolare che un valore non deve corrispondere. Ad esempio Error:(.*?)\.Se si seleziona la casella Custom on fail, è possibile specificare opzioni personalizzate di gestione dell'errore: scartare il valore, impostare un valore specificato oppure impostare un messaggio di errore specificato. |
|
| Check for error in JSON | Controlla la presenza di un messaggio di errore a livello applicativo situato in JSONPath. Interrompe l'elaborazione se ha esito positivo e il messaggio non è vuoto; altrimenti continua l'elaborazione con il valore precedente a questo passaggio di preprocessing. Nota che questi errori del servizio esterno vengono segnalati all'utente così come sono, senza aggiungere informazioni sul passaggio di preprocessing. Ad esempio $.errors. Se viene ricevuto un JSON come {"errors":"e1"}, il passaggio di preprocessing successivo non verrà eseguito.Se si seleziona la casella Custom on fail, è possibile specificare opzioni personalizzate di gestione dell'errore: scartare il valore, impostare un valore specificato oppure impostare un messaggio di errore specificato. |
|
| Check for error in XML | Controlla la presenza di un messaggio di errore a livello applicativo situato in Xpath. Interrompe l'elaborazione se ha esito positivo e il messaggio non è vuoto; altrimenti continua l'elaborazione con il valore precedente a questo passaggio di preprocessing. Nota che questi errori del servizio esterno vengono segnalati all'utente così come sono, senza aggiungere informazioni sul passaggio di preprocessing. Nessun errore verrà segnalato in caso di mancata analisi di XML non valido. Se si seleziona la casella Custom on fail, è possibile specificare opzioni personalizzate di gestione dell'errore: scartare il valore, impostare un valore specificato oppure impostare un messaggio di errore specificato. |
|
| Matches regular expression | Specifica un'espressione regolare a cui un valore deve corrispondere. Se si seleziona la casella Custom on fail, è possibile specificare opzioni personalizzate di gestione dell'errore: scartare il valore, impostare un valore specificato oppure impostare un messaggio di errore specificato. |
|
| Throttling | ||
| Discard unchanged with heartbeat | Scarta un valore se non è cambiato entro il periodo di tempo definito (in secondi). Sono supportati valori interi positivi per specificare i secondi (minimo - 1 secondo). In questo campo è possibile usare suffissi di tempo (ad esempio 30s, 1m, 2h, 1d). In questo campo è possibile usare macro utente e macro di low-level discovery. Per un item di discovery è possibile specificare una sola opzione di throttling. Ad esempio 1m. Se lo stesso testo viene passato in questa regola due volte entro 60 secondi, verrà scartato.Nota: la modifica dei prototipi di item non reimposta il throttling. Il throttling viene reimpostato solo quando vengono modificati i passaggi di preprocessing. |
|
| Prometheus | ||
| Prometheus to JSON | Converte le metriche Prometheus richieste in JSON. Per ulteriori dettagli, vedere Controlli Prometheus. |
|
Nota che se la discovery rule è stata applicata all'host tramite template, il contenuto di questa scheda è di sola lettura.
Macro personalizzate
La scheda Macro LLD consente di specificare macro personalizzate per il low-level discovery.
Le macro personalizzate sono utili nei casi in cui il JSON restituito non abbia già definite le macro richieste. Quindi, ad esempio:
- La chiave nativa
vfs.fs.discoveryper il rilevamento dei filesystem restituisce un JSON con alcune macro LLD predefinite come {#FSNAME}, {#FSTYPE}. Queste macro possono essere utilizzate direttamente nei prototipi di item e trigger (vedere le sezioni successive della pagina); non è necessario definire macro personalizzate; - Anche l'item agent
vfs.fs.getrestituisce un JSON con i dati del filesystem, ma senza alcuna macro LLD predefinita. In questo caso è possibile definire personalmente le macro e associarle ai valori nel JSON utilizzando JSONPath:
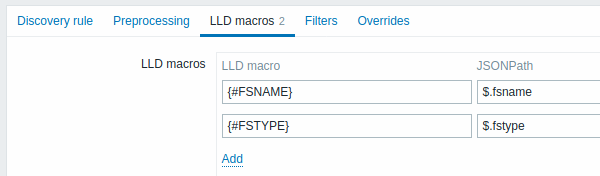
I valori estratti possono essere utilizzati negli item rilevati, nei trigger, ecc. Si noti che i valori verranno estratti dal risultato del rilevamento e da tutti i passaggi di preprocessing eseguiti fino a quel momento.
| Parameter | Description |
|---|---|
| LLD macro | Nome della macro di low-level discovery, utilizzando la seguente sintassi: {#MACRO}. |
| JSONPath | Percorso utilizzato per estrarre il valore della macro LLD da una riga LLD, usando la sintassi JSONPath. I valori estratti dal JSON restituito vengono utilizzati per sostituire le macro LLD nei campi dei prototipi di item, trigger, ecc. JSONPath può essere specificato utilizzando la notazione con punto oppure la notazione con parentesi. La notazione con parentesi deve essere utilizzata in presenza di caratteri speciali e Unicode, come $['unicode + special chars #1']['unicode + special chars #2'].Ad esempio, $.foo estrarrà "bar" e "baz" da questo JSON: [{"foo":"bar"}, {"foo":"baz"}]Si noti che $.foo estrarrà "bar" e "baz" anche da questo JSON: {"data":[{"foo":"bar"}, {"foo":"baz"}]} perché un singolo oggetto "data" viene elaborato automaticamente (per retrocompatibilità con l'implementazione del low-level discovery nelle versioni di Zabbix precedenti alla 4.2). |
Filtro
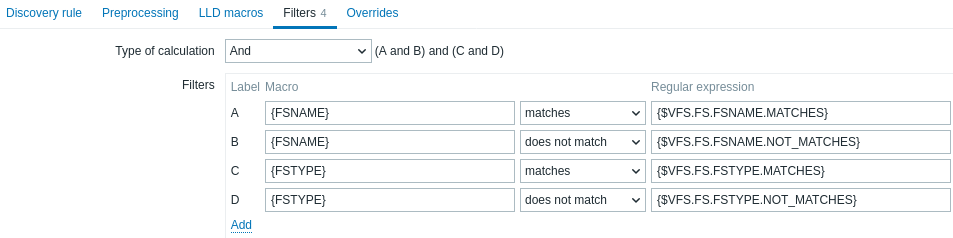
Un filtro può essere utilizzato per generare item, trigger e grafici reali solo per le entità che corrispondono ai criteri. La scheda Filters contiene le definizioni dei filtri della regola di discovery, consentendo di filtrare i valori di discovery:
| Parameter | Description |
|---|---|
| Type of calculation | Sono disponibili le seguenti opzioni per il calcolo dei filtri: And - tutti i filtri devono essere superati; Or - è sufficiente che un filtro sia superato; And/Or - usa And con nomi macro diversi e Or con lo stesso nome macro; Custom expression - offre la possibilità di definire un calcolo personalizzato dei filtri. La formula deve includere tutti i filtri nell'elenco. Limitato a 255 simboli. |
| Filters | Sono disponibili i seguenti operatori per le condizioni di filtro: matches, does not match, exists, does not exist. Gli operatori Matches e does not match si aspettano una Perl Compatible Regular Expression (PCRE). È possibile inserire un'espressione regolare o fare riferimento a una espressione regolare globale nel campo Regular expression. Gli operatori Exists e does not exist consentono di filtrare le entità in base alla presenza o all'assenza della macro LLD specificata nella risposta. Nota che, se una macro del filtro è assente nella risposta, l'entità trovata verrà ignorata, a meno che per questa macro non sia specificata una condizione "does not exist". Verrà visualizzato un avviso se l'assenza di una macro influisce sul risultato dell'espressione. Ad esempio, se {#B} manca in:{#A} matches 1 and {#B} matches 2 - verrà mostrato un avviso{#A} matches 1 or {#B} matches 2 - nessun avviso. |
Ad esempio, se sei interessato solo ai file system C:, D: ed E:, puoi inserire {#FSNAME} nel campo Macro e ^C|^D|^E nel campo Regular expression.
Il filtraggio è possibile anche in base ai tipi di file system usando la macro {#FSTYPE} (ad esempio ^ext|^reiserfs) e in base ai tipi di unità disco (supportato solo da Windows agent) usando la macro {#FSDRIVETYPE} (ad esempio fixed).
Per testare un'espressione regolare puoi usare grep -E, ad esempio:
for f in ext2 nfs reiserfs smbfs;
do echo $f | grep -E '^ext|^reiserfs' || echo "SKIP: $f";
doneUn errore o un refuso nell'espressione regolare usata nella regola LLD (ad esempio, un'espressione regolare non corretta per "File systems for discovery") può causare l'eliminazione di migliaia di elementi di configurazione, valori storici ed eventi per molti host.
Il database Zabbix in MySQL deve essere creato con distinzione tra maiuscole e minuscole se i nomi dei file system che differiscono solo per maiuscole/minuscole devono essere rilevati correttamente.
Override
La scheda Overrides consente di impostare regole per modificare l'elenco dei prototipi di item, trigger, graph, host e discovery, oppure i relativi attributi, per gli oggetti scoperti che soddisfano determinati criteri.
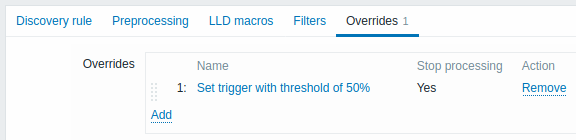
Gli override, se presenti, vengono visualizzati in un elenco riordinabile tramite trascinamento e rilascio ed eseguiti nell'ordine in cui sono definiti. Per configurare i dettagli di un nuovo override, fare clic su  nel blocco Overrides.
Per modificare un override esistente, fare clic sul nome dell'override.
Si aprirà una finestra popup che consente di modificare i dettagli della regola di override.
nel blocco Overrides.
Per modificare un override esistente, fare clic sul nome dell'override.
Si aprirà una finestra popup che consente di modificare i dettagli della regola di override.
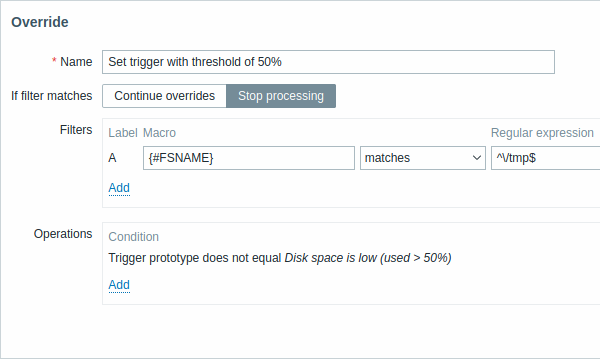
Tutti i parametri obbligatori sono contrassegnati da asterischi rossi.
| Parameter | Description |
|---|---|
| Name | Un nome univoco dell'override (per regola LLD). |
| If filter matches | Definisce se gli override successivi devono essere elaborati quando le condizioni del filtro sono soddisfatte: Continue overrides - gli override successivi verranno elaborati. Stop processing - verranno eseguite le operazioni degli override precedenti (se presenti) e di questo override; gli override successivi verranno ignorati per le righe LLD corrispondenti. |
| Filters | Determina a quali entità scoperte deve essere applicato l'override. I filtri dell'override vengono elaborati dopo i filtri della regola di discovery e hanno la stessa funzionalità. |
| Operations | Le operazioni di override vengono visualizzate con questi dettagli: Condition - un tipo di oggetto e una condizione che il nome dell'oggetto deve soddisfare; ad esempio: Trigger prototype non è uguale a Disk space is low (used > 50%). Actions - vengono visualizzati i collegamenti per modificare e rimuovere un'operazione. |
Configurazione di un'operazione
Per configurare i dettagli di una nuova operazione, fare clic su nel blocco Operations.
Per modificare un'operazione esistente, fare clic su  accanto all'operazione.
Si aprirà una finestra popup in cui è possibile modificare i dettagli dell'operazione.
accanto all'operazione.
Si aprirà una finestra popup in cui è possibile modificare i dettagli dell'operazione.
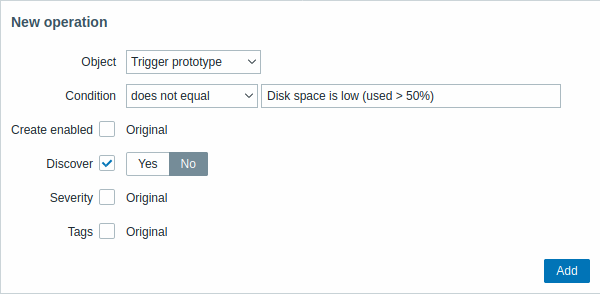
| Parameter | Description | ||
|---|---|---|---|
| Object | Sono disponibili cinque tipi di oggetti: Item prototype Trigger prototype Graph prototype Host prototype Discovery prototype |
||
| Condition | Consente di filtrare le entità a cui deve essere applicata l'operazione. | ||
| Operator | Operatori supportati: equals - applica a questo prototype does not equal - applica a tutti i prototype, tranne questo contains - applica se il nome del prototype contiene questa stringa does not contain - applica se il nome del prototype non contiene questa stringa matches - applica se il nome del prototype corrisponde all'espressione regolare does not match - applica se il nome del prototype non corrisponde all'espressione regolare |
||
| Pattern | Una espressione regolare o una stringa da cercare. | ||
| Object: Item prototype | |||
| Create enabled | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di sovrascrivere le impostazioni originali del prototype dell'item: Yes - l'item verrà aggiunto in stato abilitato. No - l'item verrà aggiunto a un'entità scoperta, ma in stato disabilitato. |
||
| Discover | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di sovrascrivere le impostazioni originali del prototype dell'item: Yes - l'item verrà aggiunto. No - l'item non verrà aggiunto. |
||
| Update interval | Quando la casella di controllo è selezionata, verranno visualizzate due opzioni che consentono di impostare un intervallo diverso per l'item: Delay - intervallo di aggiornamento dell'item. Sono supportati user macros, LLD macros e time suffixes (ad esempio 30s, 1m, 2h, 1d) (il supporto per LLD macro è stato ripristinato in Zabbix 7.4.11). Deve essere impostato a 0 se viene usato Custom interval. Custom interval - fare clic su per specificare intervalli flessibili/pianificati. Per informazioni dettagliate, vedere Custom intervals. |
||
| History | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di impostare un diverso periodo di conservazione della history per l'item: Do not store - se selezionato, la history non verrà memorizzata. Store up to - se selezionato, a destra verrà visualizzato un campo di input per specificare il periodo di conservazione. Sono supportati user macros e LLD macros (il supporto per LLD macro è stato ripristinato in Zabbix 7.4.11). |
||
| Trends | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di impostare un diverso periodo di conservazione dei trends per l'item: Do not store - se selezionato, i trends non verranno memorizzati. Store up to - se selezionato, a destra verrà visualizzato un campo di input per specificare il periodo di conservazione. Sono supportati user macros e LLD macros (il supporto per LLD macro è stato ripristinato in Zabbix 7.4.11). |
||
| Tags | Quando la casella di controllo è selezionata, verrà visualizzato un nuovo blocco che consente di specificare coppie tag-valore. Sono supportati user macros e LLD macros. Questi tag verranno aggiunti ai tag specificati nel prototype dell'item, anche se i nomi dei tag coincidono. |
||
| Object: Trigger prototype | |||
| Create enabled | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di sovrascrivere le impostazioni originali del prototype del trigger: Yes - il trigger verrà aggiunto in stato abilitato. No - il trigger verrà aggiunto a un'entità scoperta, ma in stato disabilitato. |
||
| Discover | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di sovrascrivere le impostazioni originali del prototype del trigger: Yes - il trigger verrà aggiunto. No - il trigger non verrà aggiunto. |
||
| Severity | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti di severità del trigger, che consentono di modificarne la severità. | ||
| Tags | Quando la casella di controllo è selezionata, verrà visualizzato un nuovo blocco che consente di specificare coppie tag-valore. Sono supportati user macros e LLD macros. Questi tag verranno aggiunti ai tag specificati nel prototype del trigger, anche se i nomi dei tag coincidono. |
||
| Object: Graph prototype | |||
| Discover | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di sovrascrivere le impostazioni originali del prototype del graph: Yes - il graph verrà aggiunto. No - il graph non verrà aggiunto. |
||
| Object: Host prototype | |||
| Create enabled | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di sovrascrivere le impostazioni originali del prototype dell'host: Yes - l'host verrà creato in stato abilitato. No - l'host verrà creato in stato disabilitato. |
||
| Discover | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di sovrascrivere le impostazioni originali del prototype dell'host: Yes - l'host verrà scoperto. No - l'host non verrà scoperto. |
||
| Link templates | Quando la casella di controllo è selezionata, verrà visualizzato un campo di input per specificare i template. Iniziare a digitare il nome del template oppure fare clic su Select accanto al campo e selezionare i template dall'elenco in una finestra popup. I template di questo override vengono aggiunti a tutti i template già collegati al prototype dell'host. |
||
| Tags | Quando la casella di controllo è selezionata, verrà visualizzato un nuovo blocco che consente di specificare coppie tag-valore. Sono supportati user macros e LLD macros. Questi tag verranno aggiunti ai tag specificati nel prototype dell'host, anche se i nomi dei tag coincidono. |
||
| Host inventory | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di selezionare un diverso mode di inventory per il prototype dell'host: Disabled - non compilare l'inventory dell'host Manual - fornire i dettagli manualmente Automated - compilare automaticamente i dati dell'inventory dell'host in base alle metriche raccolte. |
||
| Object: Discovery prototype | |||
| Create enabled | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di sovrascrivere le impostazioni originali del prototype della discovery: Yes - la regola di discovery verrà aggiunta in stato abilitato. No - la regola di discovery verrà aggiunta in stato disabilitato. |
||
| Discover | Quando la casella di controllo è selezionata, verranno visualizzati i pulsanti che consentono di sovrascrivere le impostazioni originali del prototype della discovery: Yes - la regola di discovery verrà aggiunta. No - la regola di discovery non verrà aggiunta. |
||
| Update interval | Quando la casella di controllo è selezionata, verranno visualizzate due opzioni che consentono di impostare un intervallo diverso per la regola di discovery: Delay - intervallo di aggiornamento della regola. Sono supportati user macros, LLD macros e time suffixes (ad esempio 30s, 1m, 2h, 1d). Deve essere impostato a 0 se viene usato Custom interval. Custom interval - fare clic su per specificare intervalli flessibili/pianificati. Per informazioni dettagliate, vedere Custom intervals. |
||
Pulsanti del modulo
I pulsanti nella parte inferiore del modulo consentono di eseguire diverse operazioni.
 |
Aggiungi una regola di individuazione. Questo pulsante è disponibile solo per le nuove regole di individuazione. |
 |
Aggiorna le proprietà di una regola di individuazione. Questo pulsante è disponibile solo per le regole di individuazione esistenti. |
 |
Crea un'altra regola di individuazione basata sulle proprietà della regola di individuazione corrente. |
 |
Esegui immediatamente l'individuazione in base alla regola di individuazione. La regola di individuazione deve già esistere. Vedi maggiori dettagli. Nota: quando si esegue immediatamente l'individuazione, la cache di configurazione non viene aggiornata, pertanto il risultato non rifletterà modifiche molto recenti alla configurazione della regola di individuazione. |
 |
Verifica la configurazione della regola di individuazione. Usa questo pulsante per verificare le impostazioni di configurazione (come la connettività e la correttezza dei parametri) senza applicare permanentemente alcuna modifica. |
 |
Elimina la regola di individuazione. |
 |
Annulla la modifica delle proprietà della regola di individuazione. |
Entità rilevate
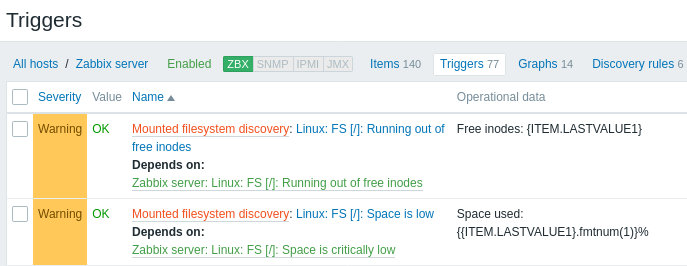
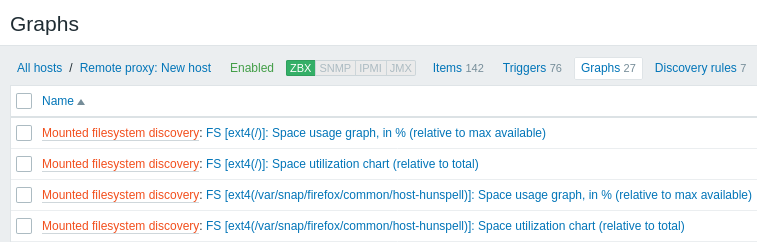
Le schermate seguenti illustrano come appaiono item, trigger e grafici rilevati nella configurazione dell'host. Le entità rilevate sono precedute da un collegamento arancione alla regola di discovery da cui provengono.
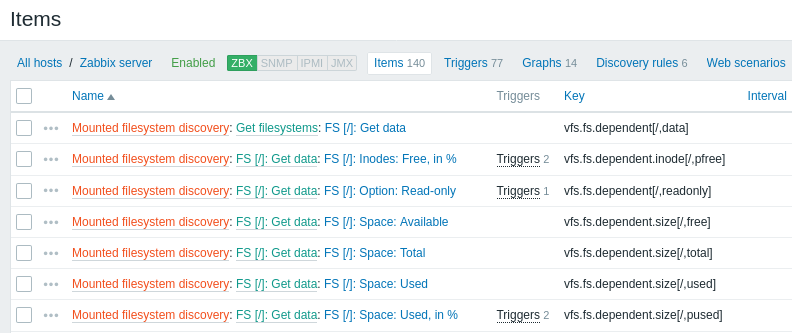
Si noti che le entità rilevate non verranno create nel caso in cui esistano già entità con gli stessi criteri di unicità, ad esempio un item con la stessa chiave o un grafico con lo stesso nome. In questo caso, nel frontend viene visualizzato un messaggio di errore che indica che la regola di low-level discovery non ha potuto creare determinate entità. La regola di discovery stessa, tuttavia, non diventerà unsupported perché alcune entità non hanno potuto essere create e hanno dovuto essere saltate. La regola di discovery continuerà a creare/aggiornare altre entità.
Se un'entità rilevata (host, file system, interfaccia, ecc.) smette di essere rilevata (o non supera più il filtro), le entità create sulla sua base possono essere automaticamente disabilitate ed eventualmente eliminate.
Le risorse perse possono essere automaticamente disabilitate in base al valore del parametro Disable lost resources. Questo riguarda host, item e trigger persi.
Le risorse perse possono essere automaticamente eliminate in base al valore del parametro Delete lost resources. Questo riguarda host, gruppi di host, item, trigger e grafici persi.
Quando le entità rilevate diventano 'Not discovered anymore', nell'elenco delle entità viene visualizzato un indicatore di durata. Spostando il puntatore del mouse su di esso, verrà visualizzato un messaggio che ne indica i dettagli di stato.

Se le entità sono state contrassegnate per l'eliminazione, ma non sono state eliminate nel momento previsto (regola di discovery o host dell'item disabilitati), verranno eliminate la volta successiva in cui la regola di discovery verrà elaborata.
Le entità che contengono altre entità contrassegnate per l'eliminazione non verranno aggiornate se modificate a livello di regola di discovery. Ad esempio, i trigger basati su LLD non verranno aggiornati se contengono item contrassegnati per l'eliminazione.
Altri tipi di discovery
Maggiori dettagli e istruzioni su altri tipi di discovery pronti all'uso sono disponibili nelle sezioni seguenti:
- discovery di interfacce di rete
- discovery di CPU e core della CPU
- discovery di OID SNMP
- discovery di oggetti JMX;
- discovery tramite query SQL ODBC
- discovery di servizi Windows
- discovery di interfacce host in Zabbix
Per maggiori dettagli sul formato JSON per gli item di discovery e un esempio su come implementare il proprio rilevatore di file system come script Perl, vedere creazione di regole LLD personalizzate.