
5 Escalados
Resumen
Con las escalaciones puede crear escenarios personalizados para enviar notificaciones o ejecutar comandos remotos.
En términos prácticos, esto significa que:
- Los usuarios pueden ser informados sobre nuevos problemas de inmediato.
- Las notificaciones pueden repetirse hasta que el problema se resuelva.
- El envío de una notificación puede retrasarse.
- Las notificaciones pueden escalarse a otro grupo de usuarios "superior".
- Los comandos remotos pueden ejecutarse de inmediato o cuando un problema no se resuelve durante un período prolongado.
Las acciones se escalan en función del paso de escalación. Cada paso tiene una duración determinada.
Puede definir tanto la duración predeterminada como una duración personalizada de un paso individual. La duración mínima de un paso de escalación es de 60 segundos.
Puede iniciar acciones, como enviar notificaciones o ejecutar comandos, desde cualquier paso. El paso uno es para acciones inmediatas. Si desea retrasar una acción, puede asignarla a un paso posterior. Para cada paso, se pueden definir varias acciones.
El número de pasos de escalación no está limitado.
Las escalaciones se definen al configurar una operación. Las escalaciones son compatibles solo con operaciones de problema, no de recuperación.
Aspectos varios del comportamiento de escalada
Consideremos qué ocurre en distintas circunstancias si una action contiene varios pasos de escalada.
| Situation | Behavior |
|---|---|
| The host in question goes into maintenance after the initial problem notification is sent | Depending on the Pause operations for suppressed problems setting in action configuration, all remaining escalation steps are executed either with a delay caused by the maintenance period or without delay. A maintenance period does not cancel operations. |
| The time period defined in the Time period action condition ends after the initial notification is sent | All remaining escalation steps are executed. The Time period condition cannot stop operations; it has effect with regard to when actions are started/not started, not operations. |
| A problem starts during maintenance and continues (is not resolved) after maintenance ends | Depending on the Pause operations for suppressed problems setting in action configuration, all escalation steps are executed either from the moment maintenance ends or immediately. |
| A problem starts during a no-data maintenance and continues (is not resolved) after maintenance ends | It must wait for the trigger to fire, before all escalation steps are executed. |
| Different escalations follow in close succession and overlap | The execution of each new escalation supersedes the previous escalation, but for at least one escalation step that is always executed on the previous escalation. This behavior is relevant in actions upon events that are created with EVERY problem evaluation of the trigger. |
| During an escalation in progress (like a message being sent), based on any type of event: - the action is disabled Based on trigger event: - the trigger is disabled - the host or item is disabled Based on internal event about triggers: - the trigger is disabled Based on internal event about items/low-level discovery rules: - the item is disabled - the host is disabled |
The message in progress is sent and then one more message on the escalation is sent. The follow-up message will have the cancellation text at the beginning of the message body (NOTE: Escalation canceled) naming the reason (for example, NOTE: Escalation canceled: action '<Action name>' disabled). This way the recipient is informed that the escalation is canceled and no more steps will be executed. This message is sent to all who received the notifications before. The reason of cancellation is also logged to the server log file (starting from Debug Level 3=Warning). Note that the Escalation canceled message is also sent if operations are finished, but recovery operations are configured and are not executed yet. |
| During an escalation in progress (like a message being sent) the action is deleted | No more messages are sent. The information is logged to the server log file (starting from Debug Level 3=Warning), for example: escalation canceled: action id:334 deleted |
Ejemplos de escalado
Ejemplo 1
Envío de una notificación repetida cada 30 minutos (5 veces en total) a un grupo "Administradores de MySQL". Para configurar:
- En la pestaña Operaciones, establezca la Duración por defecto del paso de operación en "30m" (30 minutos).
- Establezca los Pasos de escalado desde "1" hasta "5".
- Seleccione el grupo "Administradores de MySQL" como destinatarios del mensaje.
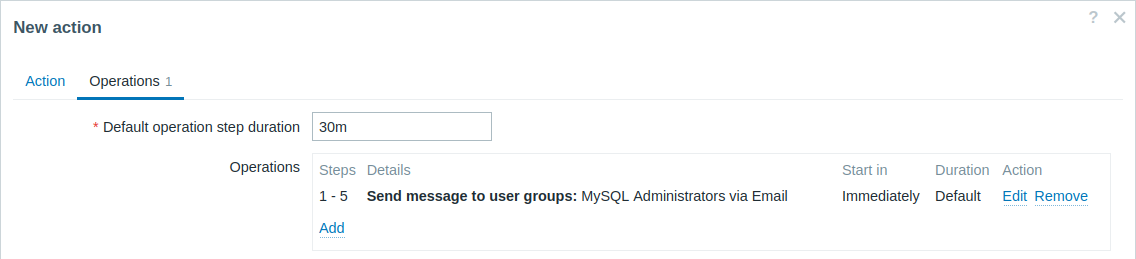
Las notificaciones se enviarán a las 0:00, 0:30, 1:00, 1:30, 2:00 horas después de que comience el problema (a menos que, por supuesto, el problema se resuelva antes).
Si el problema se resuelve y se configura un mensaje de recuperación, se enviará a quienes hayan recibido al menos un mensaje de problema dentro de este escenario de escalado.
Si el disparador que generó una escalada activa es deshabilitado, Zabbix envía un mensaje informativo al respecto a todos aquellos que ya han recibido notificaciones.
Ejemplo 2
Envío de una notificación retrasada sobre un problema prolongado. Para configurar:
- En la pestaña Operaciones, establezca la Duración por defecto del paso de operación en "10h" (10 horas).
- Establezca los Pasos de la escalada desde "2" hasta "2".
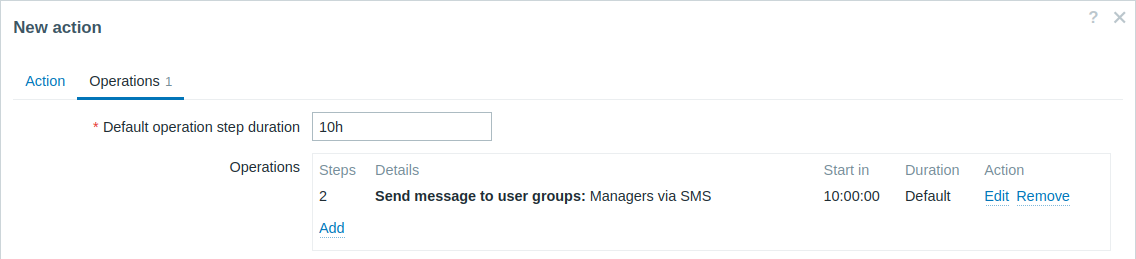
Solo se enviará una notificación en el Paso 2 del escenario de escalada, o 10 horas después de que comience el problema.
Puede personalizar el texto del mensaje a algo como "El problema tiene más de 10 horas".
Ejemplo 3
Escalando el problema al Jefe.
En el primer ejemplo anterior configuramos el envío periódico de mensajes a los administradores de MySQL. En este caso, los administradores recibirán cuatro mensajes antes de que el problema se escale al responsable de la base de datos. Tenga en cuenta que el responsable recibirá un mensaje solo en caso de que el problema aún no haya sido reconocido, suponiendo que nadie está trabajando en él.

Detalles de la Operación 2:

Observe el uso de la macro {ESC.HISTORY} en el mensaje personalizado. La macro contendrá información sobre todos los pasos ejecutados previamente en esta escalada, como notificaciones enviadas y comandos ejecutados.
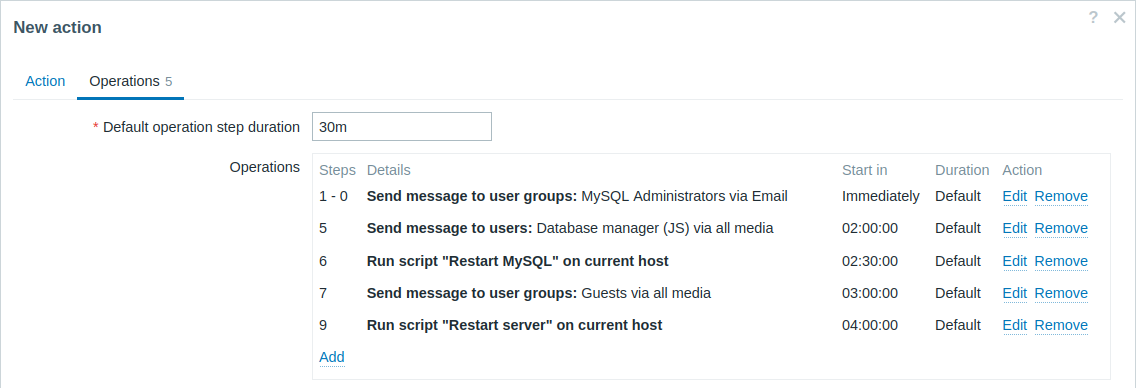
Ejemplo 4
Un escenario más complejo. Después de múltiples mensajes a los administradores de MySQL y la escalada al gerente, Zabbix intentará reiniciar la base de datos MySQL. Esto ocurrirá si el problema existe durante 2:30 horas y no ha sido reconocido.
Si el problema aún existe, después de otros 30 minutos Zabbix enviará un mensaje a todos los usuarios invitados.
Si esto no ayuda, después de otra hora Zabbix reiniciará el servidor con la base de datos MySQL (segundo comando remoto) usando comandos IPMI.
Ejemplo 5
Una escalada con varias operaciones que tienen rangos de pasos superpuestos e intervalos personalizados. La duración por defecto de los pasos de la operación es de 30 minutos.

Las notificaciones se enviarán de la siguiente manera:
- A los administradores de MySQL a las 0:00, 0:30, 1:00 y 1:30 después de que comience el problema.
- Al administrador de la base de datos a las 2:00 y 2:10 (la duración de paso personalizada más corta de 10 minutos definida en la operación posterior anula la duración de paso más larga de 1 hora configurada aquí, como se describe en Detalles de la operación para Duración del paso cuando los pasos se superponen).
- A los administradores de Zabbix a las 2:00, 2:10 y 2:20 después de que comience el problema (se aplica la duración de paso personalizada de 10 minutos).
- A los usuarios invitados a las 4:00 después de que comience el problema (la duración de paso por defecto de 30 minutos entra en vigor entre los pasos 8 y 11).