
Odkrywanie niskiego poziomu
Omówienie
Low-level discovery (LLD) automatycznie wykrywa encje (np. systemy plików, interfejsy sieciowe) na host i tworzy odpowiadające im pozycje, wyzwalacze i wykresy bez ręcznej konfiguracji dla każdej z nich.
Aby używać LLD, tworzysz regułę wykrywania, która zbiera dane JSON opisujące encje, oraz prototypy (pozycja, wyzwalacz i wykres) dla każdej encji.
JSON zwracany przez regułę musi być tablicą obiektów, gdzie każdy obiekt reprezentuje jedną wykrytą encję za pomocą par klucz-wartość. Na przykład reguła wykrywania z net.if.discovery może zwrócić:
[
{"{#IFNAME}": "lo"},
{"{#IFNAME}": "eth0"}
]Odpowiedni zestaw pozycji, wyzwalaczy i wykresów jest następnie tworzony na podstawie prototypów — po jednym dla każdego interfejsu (lo i eth0).
Jeśli obiekty zawierają klucze w formacie {#MACRO}, te makra są używane bezpośrednio w prototypach. Jeśli nie, lub jeśli wymagane są dodatkowe/własne makra, można je zdefiniować ręcznie i mapować do pól JSON za pomocą JSONPath.
LLD może również tworzyć hosty (np. dla maszyn wirtualnych wykrytych na hypervisorze) oraz obsługuje zagnieżdżone reguły wykrywania dla wielopoziomowego wykrywania.
Encje, które nie są już wykrywane, mogą być automatycznie wyłączane lub usuwane.
Konfigurowanie wykrywania niskiego poziomu
Przedstawimy wykrywanie niskiego poziomu na przykładzie wykrywania systemu plików.
Aby skonfigurować wykrywanie, wykonaj następujące czynności:
- Przejdź do Data collection > Templates lub Hosts.
- Kliknij Discovery w wierszu odpowiedniego szablonu/hosta.

- Kliknij Create discovery rule w prawym górnym rogu ekranu.
- Wypełnij formularz reguły wykrywania, podając wymagane szczegóły.
Reguła wykrywania
Formularz reguły wykrywania zawiera pięć kart, reprezentujących, od lewej do prawej, przepływ danych podczas wykrywania:
- Reguła wykrywania - określa przede wszystkim wbudowaną pozycję lub niestandardowy skrypt służący do pobierania danych wykrywania.
- Preprocessing - stosuje wstępne przetwarzanie do wykrytych danych.
- Makra LLD - umożliwia wyodrębnienie niektórych wartości makr do użycia w wykrytych pozycjach, wyzwalaczach itp.
- Filtry - umożliwia filtrowanie wykrytych wartości.
- Nadpisania - umożliwia modyfikowanie pozycji, wyzwalaczy, wykresów lub prototypów hostów podczas stosowania do określonych wykrytych obiektów.
Karta Reguła wykrywania zawiera klucz pozycji używany do wykrywania (a także niektóre ogólne atrybuty reguły wykrywania):
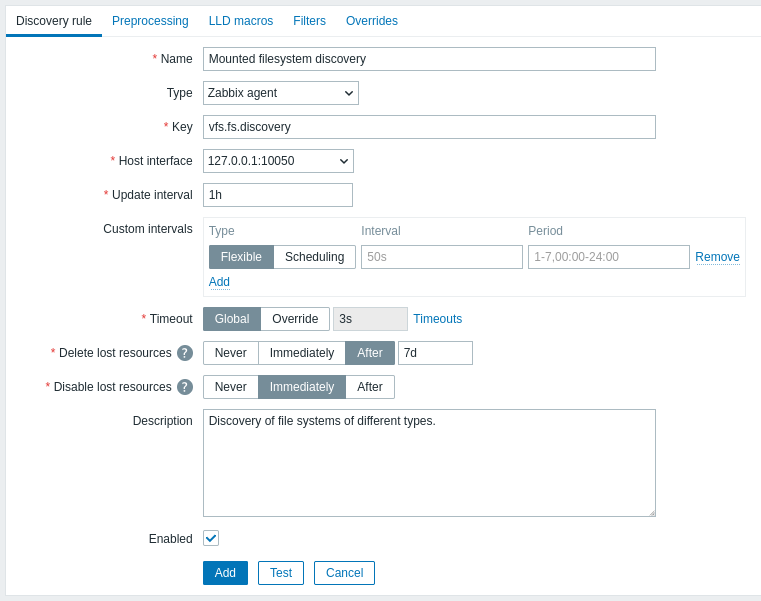
Wszystkie obowiązkowe pola wejściowe są oznaczone czerwoną gwiazdką.
| Parameter | Description |
|---|---|
| Name | Nazwa reguły wykrywania. |
| Type | Typ sprawdzenia wykonywanego podczas wykrywania. W tym przykładzie używamy typu pozycji Zabbix agent. Reguła wykrywania może być również pozycją zależną, opartą na zwykłej pozycji. Nie może zależeć od innej reguły wykrywania. W przypadku pozycji zależnej wybierz odpowiedni typ (Dependent item) i określ pozycję nadrzędną w polu 'Master item'. Pozycja nadrzędna musi istnieć. |
| Key | Wprowadź klucz pozycji wykrywania (do 2048 znaków). Na przykład możesz użyć wbudowanego klucza pozycji "vfs.fs.discovery", aby zwrócić ciąg JSON z listą systemów plików obecnych na komputerze, ich typami i opcjami montowania. Zwróć uwagę, że inną opcją wykrywania systemów plików jest użycie wyników wykrywania przez klucz agenta "vfs.fs.get" (zobacz przykład). |
| Update interval | To pole określa, jak często Zabbix wykonuje wykrywanie. Na początku, gdy dopiero konfigurujesz wykrywanie systemu plików, możesz ustawić krótki interwał, ale gdy już upewnisz się, że działa poprawnie, możesz ustawić go na 30 minut lub więcej, ponieważ systemy plików zwykle nie zmieniają się zbyt często. Obsługiwane są sufiksy czasu, np. 30s, 1m, 2h, 1d. Obsługiwane są makra użytkownika. Uwaga: Interwał aktualizacji można ustawić na '0' tylko wtedy, gdy istnieją niestandardowe interwały z wartością inną niż zero. Jeśli ustawiono '0' i istnieje niestandardowy interwał (elastyczny lub zaplanowany) z wartością inną niż zero, pozycja będzie sprawdzana w czasie trwania niestandardowego interwału. Nowe reguły wykrywania zostaną sprawdzone w ciągu 60 sekund od utworzenia, chyba że mają zaplanowany lub elastyczny interwał aktualizacji, a Update interval jest ustawiony na 0. Uwaga, że dla istniejącej reguły wykrywania wykrywanie może zostać wykonane natychmiast po naciśnięciu przycisku Execute now button. |
| Custom intervals | Możesz utworzyć niestandardowe reguły sprawdzania pozycji: Flexible - tworzy wyjątek od Update interval (interwał o innej częstotliwości) Scheduling - tworzy niestandardowy harmonogram odpytywania. Szczegółowe informacje znajdziesz w sekcji Custom intervals. |
| Timeout | Ustaw limit czasu dla sprawdzenia wykrywania. Wybierz opcję limitu czasu: Global - używany jest limit czasu proxy/globalny (wyświetlany w wyszarzonym polu Timeout); Override - używany jest niestandardowy limit czasu (ustawiany w polu Timeout; dozwolony zakres: 1 - 600s). Obsługiwane są sufiksy czasu, np. 30s, 1m, oraz makra użytkownika. Kliknięcie łącza Timeouts umożliwia skonfigurowanie limitów czasu proxy lub limitów czasu globalnych (jeśli nie jest używany proxy). Zwróć uwagę, że łącze Timeouts jest widoczne tylko dla użytkowników typu Super admin z uprawnieniami do sekcji frontend Administration > General lub Administration > Proxies. |
| Delete lost resources | Określ, jak szybko wykryty obiekt zostanie usunięty po tym, jak jego status wykrycia zmieni się na "Not discovered anymore": Never - nie zostanie usunięty; Immediately - zostanie usunięty natychmiast; After - zostanie usunięty po określonym czasie. Wartość musi być większa niż wartość Disable lost resources. Obsługiwane są sufiksy czasu, np. 2h, 1d. Obsługiwane są makra użytkownika. Uwaga: Nie zaleca się używania opcji "Immediately", ponieważ samo błędne edytowanie filtra może spowodować usunięcie obiektu wraz ze wszystkimi danymi historycznymi. Zwróć uwagę, że zasoby wyłączone ręcznie nie zostaną usunięte przez wykrywanie niskiego poziomu. |
| Disable lost resources | Określ, jak szybko wykryty obiekt zostanie wyłączony po tym, jak jego status wykrycia zmieni się na "Not discovered anymore": Never - nie zostanie wyłączony; Immediately - zostanie wyłączony natychmiast; After - zostanie wyłączony po określonym czasie. Wartość powinna być większa niż interwał aktualizacji reguły wykrywania. Zwróć uwagę, że zasoby wyłączone automatycznie zostaną ponownie włączone, jeśli zostaną ponownie wykryte przez wykrywanie niskiego poziomu. Zasoby wyłączone ręcznie nie zostaną ponownie włączone po ponownym wykryciu. To pole nie jest wyświetlane, jeśli Delete lost resources jest ustawione na "Immediately". Obsługiwane są sufiksy czasu, np. 2h, 1d. Obsługiwane są makra użytkownika. |
| Description | Wprowadź opis. |
| Enabled | Jeśli zaznaczone, reguła będzie przetwarzana. |
Historia reguły wykrywania nie jest zachowywana.
Preprocessing
Zakładka Preprocessing pozwala zdefiniować reguły transformacji stosowane do wyniku discovery. Na tym etapie możliwa jest jedna lub kilka transformacji. Transformacje są wykonywane w kolejności, w jakiej zostały zdefiniowane. Całe preprocessing jest wykonywane przez serwer Zabbix.
Zobacz także:
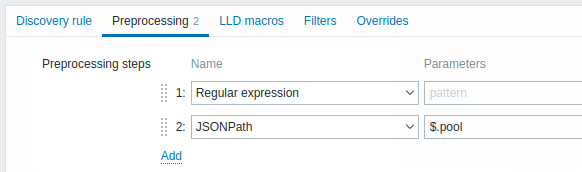
| Type | ||
|---|---|---|
| Transformation | Description | |
| Text | ||
| Regular expression | Dopasuj otrzymaną wartość do wyrażenia regularnego <pattern> i zastąp wartość wyodrębnionym <output>. Wyrażenie regularne obsługuje wyodrębnianie maksymalnie 10 przechwyconych grup za pomocą sekwencji \N. Parameters: pattern - wyrażenie regularne output - szablon formatowania wyjścia. Sekwencja ucieczki \N (gdzie N=1…9) jest zastępowana przez N-tą dopasowaną grupę. Sekwencja ucieczki \0 jest zastępowana przez dopasowany tekst. Jeśli zaznaczysz pole wyboru Custom on fail, możliwe jest określenie niestandardowych opcji obsługi błędów: odrzucenie wartości, ustawienie określonej wartości lub ustawienie określonego komunikatu o błędzie. |
|
| Replace | Znajdź ciąg wyszukiwania i zastąp go innym (lub niczym). Wszystkie wystąpienia ciągu wyszukiwania zostaną zastąpione. Parameters: search string - ciąg do znalezienia i zastąpienia, z uwzględnieniem wielkości liter (wymagane) replacement - ciąg, którym należy zastąpić ciąg wyszukiwania. Ciąg zastępczy może być również pusty, co w praktyce pozwala usunąć znaleziony ciąg. Można używać sekwencji ucieczki do wyszukiwania lub zastępowania znaków nowej linii, powrotu karetki, tabulatorów i spacji "\n \r \t \s"; znak ukośnika odwrotnego można zapisać jako "\\" a sekwencje ucieczki można zapisać jako "\\n". Ucieczka znaków nowej linii, powrotu karetki i tabulatorów jest wykonywana automatycznie podczas low-level discovery. |
|
| Structured data | ||
| JSONPath | Wyodrębnij wartość lub fragment z danych JSON za pomocą funkcjonalności JSONPath. Jeśli zaznaczysz pole wyboru Custom on fail, możliwe jest określenie niestandardowych opcji obsługi błędów: odrzucenie wartości, ustawienie określonej wartości lub ustawienie określonego komunikatu o błędzie. |
|
| XML XPath | Wyodrębnij wartość lub fragment z danych XML za pomocą funkcjonalności XPath. Aby ta opcja działała, serwer Zabbix musi być skompilowany z obsługą libxml. Przykłady: number(/document/item/value) wyodrębni 10 z <document><item><value>10</value></item></document>number(/document/item/@attribute) wyodrębni 10 z <document><item attribute="10"></item></document>/document/item wyodrębni <item><value>10</value></item> z <document><item><value>10</value></item></document>Uwaga: przestrzenie nazw nie są obsługiwane. Jeśli zaznaczysz pole wyboru Custom on fail, możliwe jest określenie niestandardowych opcji obsługi błędów: odrzucenie wartości, ustawienie określonej wartości lub ustawienie określonego komunikatu o błędzie. |
|
| CSV to JSON | Konwertuj dane pliku CSV do formatu JSON. Więcej informacji: CSV to JSON preprocessing. |
|
| XML to JSON | Konwertuj dane w formacie XML do JSON. Więcej informacji: Zasady serializacji. Jeśli zaznaczysz pole wyboru Custom on fail, możliwe jest określenie niestandardowych opcji obsługi błędów: odrzucenie wartości, ustawienie określonej wartości lub ustawienie określonego komunikatu o błędzie. |
|
| SNMP | ||
| SNMP walk value | Wyodrębnij wartość dla określonej nazwy OID/MIB i zastosuj opcje formatowania: Unchanged - zwróć Hex-STRING jako niezmieniony ciąg szesnastkowy (uwaga: wskazówki wyświetlania są nadal stosowane); UTF-8 from Hex-STRING - konwertuj Hex-STRING do ciągu UTF-8; MAC from Hex-STRING - konwertuj Hex-STRING do ciągu adresu MAC (w którym ' ' zostanie zastąpione przez ':');Integer from BITS - konwertuj pierwsze 8 bajtów ciągu bitowego wyrażonego jako sekwencja znaków szesnastkowych (np. "1A 2B 3C 4D") na 64-bitową liczbę całkowitą bez znaku. W ciągach bitowych dłuższych niż 8 bajtów kolejne bajty zostaną zignorowane. Jeśli zaznaczysz pole wyboru Custom on fail, możliwe jest określenie niestandardowych opcji obsługi błędów: odrzucenie wartości, ustawienie określonej wartości lub ustawienie określonego komunikatu o błędzie. |
|
| SNMP walk to JSON | Konwertuj wartości SNMP do JSON. Określ nazwę pola w JSON oraz odpowiadającą jej ścieżkę SNMP OID. Wartości pól zostaną wypełnione wartościami z określonej ścieżki SNMP OID. Ten krok preprocessing można wykorzystać do SNMP OID discovery. Dostępne są podobne opcje formatowania wartości jak w kroku SNMP walk value. Jeśli zaznaczysz pole wyboru Custom on fail, możliwe jest określenie niestandardowych opcji obsługi błędów: odrzucenie wartości, ustawienie określonej wartości lub ustawienie określonego komunikatu o błędzie. |
|
| SNMP get value | Zastosuj opcje formatowania do wartości SNMP get: UTF-8 from Hex-STRING - konwertuj Hex-STRING do ciągu UTF-8; MAC from Hex-STRING - konwertuj Hex-STRING do ciągu adresu MAC (w którym ' ' zostanie zastąpione przez ':');Integer from BITS - konwertuj pierwsze 8 bajtów ciągu bitowego wyrażonego jako sekwencja znaków szesnastkowych (np. "1A 2B 3C 4D") na 64-bitową liczbę całkowitą bez znaku. W ciągach bitowych dłuższych niż 8 bajtów kolejne bajty zostaną zignorowane. Jeśli zaznaczysz pole wyboru Custom on fail, możliwe jest określenie niestandardowych opcji obsługi błędów: odrzucenie wartości, ustawienie określonej wartości lub ustawienie określonego komunikatu o błędzie. |
|
| Custom scripts | ||
| JavaScript | Wprowadź kod JavaScript w edytorze modalnym, który otwiera się po kliknięciu w pole parametru lub ikonę ołówka obok niego. Pamiętaj, że dostępna długość JavaScript zależy od używanej bazy danych. Więcej informacji: Javascript preprocessing |
|
| Validation | ||
| Does not match regular expression | Określ wyrażenie regularne, z którym wartość nie może się zgadzać. Np. Error:(.*?)\.Jeśli zaznaczysz pole wyboru Custom on fail, możliwe jest określenie niestandardowych opcji obsługi błędów: odrzucenie wartości, ustawienie określonej wartości lub ustawienie określonego komunikatu o błędzie. |
|
| Check for error in JSON | Sprawdź komunikat o błędzie na poziomie aplikacji znajdujący się pod JSONPath. Zatrzymaj przetwarzanie, jeśli operacja się powiedzie, a komunikat nie jest pusty; w przeciwnym razie kontynuuj przetwarzanie z wartością, która była przed tym krokiem preprocessing. Pamiętaj, że te błędy usług zewnętrznych są zgłaszane użytkownikowi bez zmian, bez dodawania informacji o kroku preprocessing. Np. $.errors. Jeśli zostanie odebrany JSON taki jak {"errors":"e1"}, następny krok preprocessing nie zostanie wykonany.Jeśli zaznaczysz pole wyboru Custom on fail, możliwe jest określenie niestandardowych opcji obsługi błędów: odrzucenie wartości, ustawienie określonej wartości lub ustawienie określonego komunikatu o błędzie. |
|
| Check for error in XML | Sprawdź komunikat o błędzie na poziomie aplikacji znajdujący się pod Xpath. Zatrzymaj przetwarzanie, jeśli operacja się powiedzie, a komunikat nie jest pusty; w przeciwnym razie kontynuuj przetwarzanie z wartością, która była przed tym krokiem preprocessing. Pamiętaj, że te błędy usług zewnętrznych są zgłaszane użytkownikowi bez zmian, bez dodawania informacji o kroku preprocessing. W przypadku niepowodzenia parsowania nieprawidłowego XML nie zostanie zgłoszony żaden błąd. Jeśli zaznaczysz pole wyboru Custom on fail, możliwe jest określenie niestandardowych opcji obsługi błędów: odrzucenie wartości, ustawienie określonej wartości lub ustawienie określonego komunikatu o błędzie. |
|
| Matches regular expression | Określ wyrażenie regularne, z którym wartość musi się zgadzać. Jeśli zaznaczysz pole wyboru Custom on fail, możliwe jest określenie niestandardowych opcji obsługi błędów: odrzucenie wartości, ustawienie określonej wartości lub ustawienie określonego komunikatu o błędzie. |
|
| Throttling | ||
| Discard unchanged with heartbeat | Odrzuć wartość, jeśli nie zmieniła się w zdefiniowanym okresie czasu (w sekundach). Obsługiwane są dodatnie wartości całkowite określające liczbę sekund (minimum - 1 sekunda). W tym polu można używać sufiksów czasu (np. 30s, 1m, 2h, 1d). W tym polu można używać makr użytkownika i makr low-level discovery. Dla jednej pozycji discovery można określić tylko jedną opcję throttling. Np. 1m. Jeśli identyczny tekst zostanie przekazany do tej reguły dwa razy w ciągu 60 sekund, zostanie odrzucony.Uwaga: Zmiana prototypów pozycji nie resetuje throttling. Throttling jest resetowany tylko wtedy, gdy zmieniane są kroki preprocessing. |
|
| Prometheus | ||
| Prometheus to JSON | Konwertuj wymagane metryki Prometheus do JSON. Więcej szczegółów: Sprawdzenia Prometheus. |
|
Pamiętaj, że jeśli reguła discovery została zastosowana do hosta za pośrednictwem szablonu, zawartość tej zakładki jest tylko do odczytu.
Niestandardowe makra
Karta LLD macros umożliwia określenie niestandardowych makr LLD, gdy zwrócony JSON nie zawiera jeszcze kluczy w formacie {#MACRO}.
Na przykład klucz pozycji agenta vfs.fs.get zwraca dane JSON systemu plików bez żadnych predefiniowanych makr LLD.
Tutaj definiujesz makra ręcznie i mapujesz je na wartości w JSON za pomocą wyrażeń JSONPath:
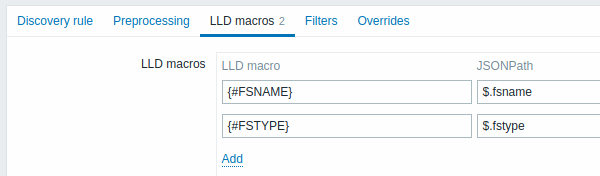
| Parameter | Description |
|---|---|
| LLD macro | Nazwa makra LLD w formacie {#MACRO}. |
| JSONPath | Wyrażenie określające, jaką wartość należy wyodrębnić z każdej wykrytej encji w tablicy JSON. Na przykład $.foo wyodrębnia "bar" i "baz" z[{"foo":"bar"}, {"foo":"baz"}].JSONPath obsługuje zarówno notację kropkową, jak i nawiasową. Notacji nawiasowej należy używać dla kluczy zawierających znaki specjalne lub Unicode, np. $['unicode + special chars #1']['unicode + special chars #2']. |
Reguła wykrywania musi zwracać tablicę JSON w korzeniu ($.).
Ze względu na zgodność wsteczną akceptowany jest również obiekt JSON zawierający pojedynczą tablicę "data". W takim przypadku tablica "data" jest automatycznie rozwijana:
{"data":[{"foo":"bar"}, {"foo":"baz"}]}Filtr
Filtr może być używany do generowania rzeczywistych pozycji, wyzwalaczy i wykresów tylko dla encji, które spełniają kryteria. Karta Filtry zawiera definicje filtrów reguły wykrywania, umożliwiające filtrowanie wartości wykrywania:
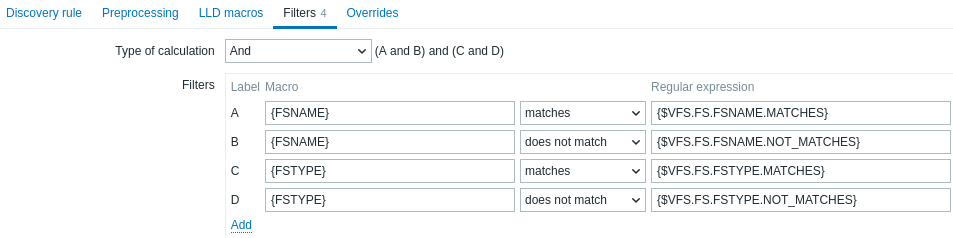
| Parameter | Description |
|---|---|
| Type of calculation | Dostępne są następujące opcje obliczania filtrów: And - wszystkie filtry muszą zostać spełnione; Or - wystarczy, że jeden filtr zostanie spełniony; And/Or - używa And dla różnych nazw makr oraz Or dla tej samej nazwy makra; Custom expression - umożliwia zdefiniowanie własnego sposobu obliczania filtrów. Formuła musi zawierać wszystkie filtry z listy. Ograniczenie do 255 znaków. |
| Filters | Dostępne są następujące operatory warunków filtra: matches, does not match, exists, does not exist. Operatory matches i does not match oczekują wyrażenia regularnego zgodnego z Perl Compatible Regular Expression (PCRE). W polu Regular expression można wprowadzić wyrażenie regularne lub odwołać się do globalnego regular expression. Operatory exists i does not exist umożliwiają filtrowanie encji na podstawie obecności lub braku określonego makra LLD w odpowiedzi. Należy pamiętać, że jeśli makro z filtra nie występuje w odpowiedzi, odnaleziona encja zostanie zignorowana, chyba że dla tego makra określono warunek "does not exist". Jeśli brak makra wpływa na wynik wyrażenia, zostanie wyświetlone ostrzeżenie. Na przykład, jeśli {#B} nie występuje w:{#A} matches 1 and {#B} matches 2 - zostanie wyświetlone ostrzeżenie{#A} matches 1 or {#B} matches 2 - bez ostrzeżenia. |
Na przykład, jeśli interesują Cię tylko systemy plików C:, D: i E:, możesz wpisać {#FSNAME} w polu Macro oraz ^C|^D|^E w polu Regular expression.
Filtrowanie jest również możliwe według typów systemów plików przy użyciu makra {#FSTYPE} (np. ^ext|^reiserfs) oraz według typów dysków (obsługiwane tylko przez agent Windows) przy użyciu makra {#FSDRIVETYPE} (np. fixed).
Aby przetestować wyrażenie regularne, możesz użyć grep -E, na przykład:
for f in ext2 nfs reiserfs smbfs;
do echo $f | grep -E '^ext|^reiserfs' || echo "SKIP: $f";
doneBłąd lub literówka w wyrażeniu regularnym używanym w regule LLD (na przykład nieprawidłowe wyrażenie regularne „File systems for discovery”) może spowodować usunięcie tysięcy elementów konfiguracji, wartości historycznych i zdarzeń dla wielu hostów.
Baza danych Zabbix w MySQL musi zostać utworzona jako uwzględniająca wielkość liter, jeśli systemy plików różniące się tylko wielkością liter mają być wykrywane poprawnie.
Nadpisywanie
Karta Overrides umożliwia definiowanie reguł służących do modyfikowania listy prototypów pozycji, wyzwalaczy, wykresów, hostów i wykrywania lub ich atrybutów dla wykrytych obiektów spełniających podane kryteria.
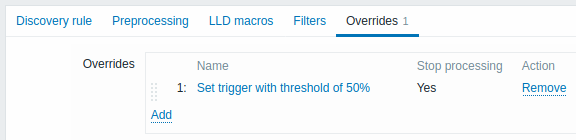
Nadpisania, jeśli istnieją, są wyświetlane na liście z możliwością zmiany kolejności metodą przeciągnij i upuść oraz wykonywane w kolejności, w jakiej zostały zdefiniowane. Aby skonfigurować szczegóły nowego nadpisania, kliknij  w bloku Overrides.
Aby edytować istniejące nadpisanie, kliknij jego nazwę.
Zostanie otwarte okno podręczne umożliwiające edycję szczegółów reguły nadpisania.
w bloku Overrides.
Aby edytować istniejące nadpisanie, kliknij jego nazwę.
Zostanie otwarte okno podręczne umożliwiające edycję szczegółów reguły nadpisania.
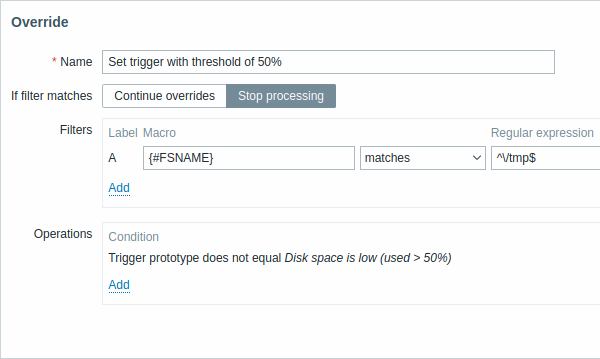
Wszystkie wymagane parametry są oznaczone czerwonymi gwiazdkami.
| Parameter | Description |
|---|---|
| Name | Unikalna nazwa nadpisania (w obrębie danej reguły LLD). |
| If filter matches | Określa, czy kolejne nadpisania mają być przetwarzane po spełnieniu warunków filtra: Continue overrides - kolejne nadpisania będą przetwarzane. Stop processing - zostaną wykonane operacje z poprzedzających nadpisań (jeśli istnieją) oraz z tego nadpisania, a kolejne nadpisania zostaną zignorowane dla dopasowanych wierszy LLD. |
| Filters | Określa, do których wykrytych encji ma zostać zastosowane nadpisanie. Filtry nadpisania są przetwarzane po filtrach reguły wykrywania i mają taką samą funkcjonalność. |
| Operations | Operacje nadpisania są wyświetlane z następującymi szczegółami: Condition - typ obiektu i warunek, jaki ma zostać spełniony przez nazwę obiektu; na przykład: Trigger prototype nie jest równe Disk space is low (used > 50%). Actions - wyświetlane są łącza do edycji i usuwania operacji. |
Konfigurowanie operacji
Aby skonfigurować szczegóły nowej operacji, kliknij w bloku Operations.
Aby edytować istniejącą operację, kliknij  obok operacji.
Zostanie otwarte okno podręczne, w którym można edytować szczegóły operacji.
obok operacji.
Zostanie otwarte okno podręczne, w którym można edytować szczegóły operacji.
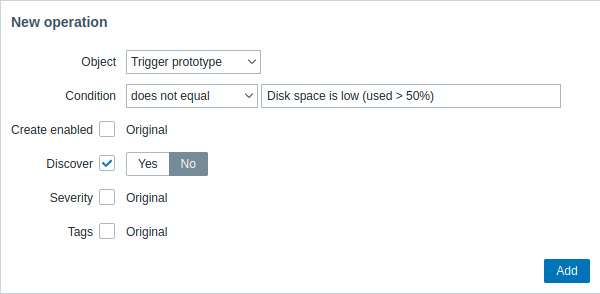
| Parameter | Description | ||
|---|---|---|---|
| Object | Dostępne są pięć typów obiektów: Item prototype Trigger prototype Graph prototype Host prototype Discovery prototype |
||
| Condition | Umożliwia filtrowanie encji, do których ma zostać zastosowana operacja. | ||
| Operator | Obsługiwane operatory: equals - zastosuj do tego prototypu does not equal - zastosuj do wszystkich prototypów z wyjątkiem tego contains - zastosuj, jeśli nazwa prototypu zawiera ten ciąg does not contain - zastosuj, jeśli nazwa prototypu nie zawiera tego ciągu matches - zastosuj, jeśli nazwa prototypu pasuje do wyrażenia regularnego does not match - zastosuj, jeśli nazwa prototypu nie pasuje do wyrażenia regularnego |
||
| Pattern | Wyrażenie regularne lub ciąg do wyszukania. | ||
| Object: Item prototype | |||
| Create enabled | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające nadpisanie oryginalnych ustawień prototypu pozycji: Yes - pozycja zostanie dodana w stanie włączonym. No - pozycja zostanie dodana do wykrytej encji, ale w stanie wyłączonym. |
||
| Discover | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające nadpisanie oryginalnych ustawień prototypu pozycji: Yes - pozycja zostanie dodana. No - pozycja nie zostanie dodana. |
||
| Update interval | Gdy pole wyboru jest zaznaczone, pojawią się dwie opcje umożliwiające ustawienie innego interwału dla pozycji: Delay - interwał aktualizacji pozycji. Obsługiwane są makra użytkownika, makra LLD oraz sufiksy czasu (np. 30s, 1m, 2h, 1d). Należy ustawić 0, jeśli używany jest Custom interval. Custom interval - kliknij , aby określić elastyczne/interwały harmonogramu. Szczegółowe informacje znajdują się w sekcji Custom intervals. |
||
| History | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające ustawienie innego okresu przechowywania historii dla pozycji: Do not store - jeśli wybrano, historia nie będzie przechowywana. Store up to - jeśli wybrano, po prawej stronie pojawi się pole do określenia okresu przechowywania. Obsługiwane są makra użytkownika i makra LLD. |
||
| Trends | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające ustawienie innego okresu przechowywania trendów dla pozycji: Do not store - jeśli wybrano, trendy nie będą przechowywane. Store up to - jeśli wybrano, po prawej stronie pojawi się pole do określenia okresu przechowywania. Obsługiwane są makra użytkownika i makra LLD. |
||
| Tags | Gdy pole wyboru jest zaznaczone, pojawi się nowy blok umożliwiający określenie par tag-wartość. Obsługiwane są makra użytkownika i makra LLD. Te tagi zostaną dołączone do tagów określonych w prototypie pozycji, nawet jeśli nazwy tagów są takie same. |
||
| Object: Trigger prototype | |||
| Create enabled | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające nadpisanie oryginalnych ustawień prototypu wyzwalacza: Yes - wyzwalacz zostanie dodany w stanie włączonym. No - wyzwalacz zostanie dodany do wykrytej encji, ale w stanie wyłączonym. |
||
| Discover | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające nadpisanie oryginalnych ustawień prototypu wyzwalacza: Yes - wyzwalacz zostanie dodany. No - wyzwalacz nie zostanie dodany. |
||
| Severity | Gdy pole wyboru jest zaznaczone, pojawią się przyciski poziomu ważności wyzwalacza, umożliwiające jego zmianę. | ||
| Tags | Gdy pole wyboru jest zaznaczone, pojawi się nowy blok umożliwiający określenie par tag-wartość. Obsługiwane są makra użytkownika i makra LLD. Te tagi zostaną dołączone do tagów określonych w prototypie wyzwalacza, nawet jeśli nazwy tagów są takie same. |
||
| Object: Graph prototype | |||
| Discover | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające nadpisanie oryginalnych ustawień prototypu wykresu: Yes - wykres zostanie dodany. No - wykres nie zostanie dodany. |
||
| Object: Host prototype | |||
| Create enabled | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające nadpisanie oryginalnych ustawień prototypu hosta: Yes - host zostanie utworzony w stanie włączonym. No - host zostanie utworzony w stanie wyłączonym. |
||
| Discover | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające nadpisanie oryginalnych ustawień prototypu hosta: Yes - host zostanie wykryty. No - host nie zostanie wykryty. |
||
| Link templates | Gdy pole wyboru jest zaznaczone, pojawi się pole do określenia szablonów. Zacznij wpisywać nazwę szablonu lub kliknij Select obok pola i wybierz szablony z listy w oknie podręcznym. Szablony z tego nadpisania są dodawane do wszystkich szablonów już powiązanych z prototypem hosta. |
||
| Tags | Gdy pole wyboru jest zaznaczone, pojawi się nowy blok umożliwiający określenie par tag-wartość. Obsługiwane są makra użytkownika i makra LLD. Te tagi zostaną dołączone do tagów określonych w prototypie hosta, nawet jeśli nazwy tagów są takie same. |
||
| Host inventory | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające wybranie innego trybu inwentarza hosta dla prototypu hosta: Disabled - nie wypełniaj inwentarza hosta Manual - podaj szczegóły ręcznie Automated - automatycznie wypełnij dane inwentarza hosta na podstawie zebranych metryk. |
||
| Object: Discovery prototype | |||
| Create enabled | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające nadpisanie oryginalnych ustawień prototypu wykrywania: Yes - reguła wykrywania zostanie dodana w stanie włączonym. No - reguła wykrywania zostanie dodana w stanie wyłączonym. |
||
| Discover | Gdy pole wyboru jest zaznaczone, pojawią się przyciski umożliwiające nadpisanie oryginalnych ustawień prototypu wykrywania: Yes - reguła wykrywania zostanie dodana. No - reguła wykrywania nie zostanie dodana. |
||
| Update interval | Gdy pole wyboru jest zaznaczone, pojawią się dwie opcje umożliwiające ustawienie innego interwału dla reguły wykrywania: Delay - interwał aktualizacji reguły. Obsługiwane są makra użytkownika, makra LLD oraz sufiksy czasu (np. 30s, 1m, 2h, 1d). Należy ustawić 0, jeśli używany jest Custom interval. Custom interval - kliknij , aby określić elastyczne/interwały harmonogramu. Szczegółowe informacje znajdują się w sekcji Custom intervals. |
||
Przyciski formularza
Przyciski na dole formularza umożliwiają wykonanie kilku operacji.
 |
Dodaj regułę wykrywania. Ten przycisk jest dostępny tylko dla nowych reguł wykrywania. |
 |
Zaktualizuj właściwości reguły wykrywania. Ten przycisk jest dostępny tylko dla istniejących reguł wykrywania. |
 |
Utwórz kolejną regułę wykrywania na podstawie właściwości bieżącej reguły wykrywania. |
 |
Wykonaj wykrywanie natychmiast na podstawie reguły wykrywania. Reguła wykrywania musi już istnieć. Zobacz więcej szczegółów. Uwaga: podczas natychmiastowego wykonywania wykrywania pamięć podręczna konfiguracji nie jest aktualizowana, dlatego wynik nie będzie odzwierciedlał bardzo niedawnych zmian w konfiguracji reguły wykrywania. |
 |
Przetestuj konfigurację reguły wykrywania. Użyj tego przycisku, aby zweryfikować ustawienia konfiguracji (takie jak łączność i poprawność parametrów) bez trwałego stosowania jakichkolwiek zmian. |
 |
Usuń regułę wykrywania. |
 |
Anuluj edycję właściwości reguły wykrywania. |
Odkryte encje
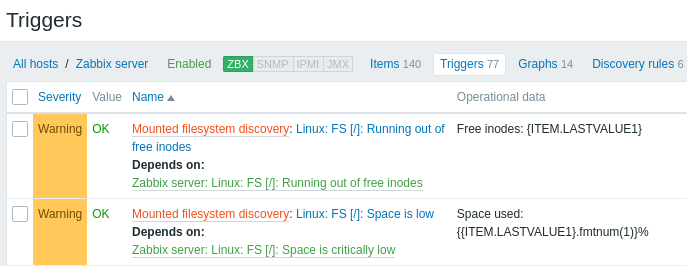
Poniższe zrzuty ekranu ilustrują, jak odkryte pozycje, wyzwalacze i wykresy wyglądają w konfiguracji hosta. Odkryte encje są poprzedzone pomarańczowym odnośnikiem do reguły wykrywania, z której pochodzą.
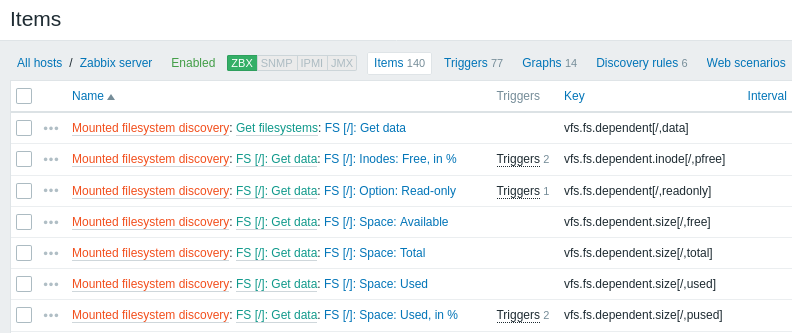
Należy pamiętać, że odkryte encje nie zostaną utworzone, jeśli istnieją już encje o tych samych kryteriach unikalności, na przykład pozycja z takim samym kluczem lub wykres o tej samej nazwie. W takim przypadku w frontend jest wyświetlany komunikat o błędzie informujący, że reguła wykrywania niskiego poziomu nie mogła utworzyć niektórych encji. Sama reguła wykrywania nie stanie się jednak nieobsługiwana tylko dlatego, że nie udało się utworzyć jakiejś encji i trzeba było ją pominąć. Reguła wykrywania będzie nadal tworzyć/aktualizować inne encje.
Jeśli odkryta encja (host, system plików, interfejs itp.) przestanie być wykrywana (lub nie przejdzie już filtra), encje utworzone na jej podstawie mogą zostać automatycznie wyłączone, a ostatecznie usunięte.
Utracone zasoby mogą być automatycznie wyłączane na podstawie wartości parametru Disable lost resources. Dotyczy to utraconych hostów, pozycji i wyzwalaczy.
Utracone zasoby mogą być automatycznie usuwane na podstawie wartości parametru Delete lost resources. Dotyczy to utraconych hostów, grup hostów, pozycji, wyzwalaczy i wykresów.
Gdy odkryte encje przechodzą do stanu „Not discovered anymore”, na liście encji wyświetlany jest wskaźnik czasu życia. Po najechaniu na niego kursorem myszy zostanie wyświetlony komunikat zawierający szczegóły statusu.

Jeśli encje zostały oznaczone do usunięcia, ale nie zostały usunięte w oczekiwanym czasie (wyłączona reguła wykrywania lub host pozycji), zostaną usunięte przy następnym przetwarzaniu reguły wykrywania.
Encje zawierające inne encje oznaczone do usunięcia nie będą aktualizowane, jeśli zostaną zmienione na poziomie reguły wykrywania. Na przykład wyzwalacze oparte na LLD nie będą aktualizowane, jeśli zawierają pozycje oznaczone do usunięcia.
Inne typy wykrywania
Więcej szczegółów oraz instrukcje dotyczące innych gotowych typów wykrywania są dostępne w następujących sekcjach:
- wykrywanie interfejsów sieciowych
- wykrywanie procesorów i rdzeni CPU
- wykrywanie OID-ów SNMP
- wykrywanie obiektów JMX;
- wykrywanie przy użyciu zapytań SQL ODBC
- wykrywanie usług Windows
- wykrywanie interfejsów hosta w Zabbix
Więcej szczegółów na temat formatu JSON dla pozycji wykrywania oraz przykład implementacji własnego mechanizmu wykrywania systemu plików jako skryptu Perl można znaleźć w sekcji tworzenie niestandardowych reguł LLD.