
Low-level-Erkennung
Übersicht
Low-Level Discovery (LLD) erkennt automatisch Entitäten (z. B. Dateisysteme, Netzwerkschnittstellen) auf einem Host und erstellt die entsprechenden Datenpunkte, Auslöser und Diagramme ohne manuelle Einrichtung für jede einzelne Entität.
Um LLD zu verwenden, erstellen Sie eine Erkennungsregel, die JSON-Daten mit einer Beschreibung der Entitäten sammelt, sowie Prototypen (Datenpunkt, Auslöser und Diagramm) für jede Entität.
Das von der Regel zurückgegebene JSON muss ein Array von Objekten sein, wobei jedes Objekt eine erkannte Entität mithilfe von Schlüssel-Wert-Paaren darstellt. Beispielsweise kann eine Erkennungsregel mit net.if.discovery Folgendes zurückgeben:
[
{"{#IFNAME}": "lo"},
{"{#IFNAME}": "eth0"}
]Ein entsprechender Satz von Datenpunkten, Auslösern und Diagrammen wird dann aus den Prototypen erstellt - jeweils einer pro Schnittstelle (lo und eth0).
Wenn Objekte Schlüssel im Format {#MACRO} enthalten, werden diese Makros direkt in Prototypen verwendet. Wenn nicht oder wenn zusätzliche/benutzerdefinierte Makros erforderlich sind, können Makros manuell definiert und mithilfe von JSONPath JSON-Feldern zugeordnet werden.
LLD kann auch Hosts erstellen (z. B. für auf einem Hypervisor erkannte virtuelle Maschinen) und unterstützt verschachtelte Erkennungsregeln für mehrstufige Erkennung.
Entitäten, die nicht mehr erkannt werden, können automatisch deaktiviert oder gelöscht werden.
Konfigurieren der Low-Level-Discovery
Wir veranschaulichen die Low-Level-Discovery anhand eines Beispiels für die Erkennung von Dateisystemen.
Gehen Sie wie folgt vor, um die Discovery zu konfigurieren:
- Gehen Sie zu Datenerfassung > Vorlagen oder Hosts.
- Klicken Sie in der Zeile der entsprechenden Vorlage/des entsprechenden Hosts auf Discovery.

- Klicken Sie oben rechts auf dem Bildschirm auf Discovery-Regel erstellen.
- Füllen Sie das Formular für die Discovery-Regel mit den erforderlichen Details aus.
Suchregel
Das Formular für die Suchregel enthält fünf Registerkarten, die von links nach rechts den Datenfluss während der Suche darstellen:
- Suchregel - gibt vor allem den integrierten Datenpunkt oder ein benutzerdefiniertes Skript an, um Suchdaten abzurufen.
- Vorverarbeitung - wendet eine Vorverarbeitung auf die gefundenen Daten an.
- LLD-Makros - ermöglicht das Extrahieren einiger Makrowerte zur Verwendung in gefundenen Datenpunkten, Auslösern usw.
- Filter - ermöglicht das Filtern der gefundenen Werte.
- Überschreibungen - ermöglicht das Ändern von Datenpunkten, Auslösern, Diagrammen oder Host-Prototypen bei der Anwendung auf bestimmte gefundene Objekte.
Die Registerkarte Suchregel enthält den für die Suche zu verwendenden Datenpunktschlüssel (sowie einige allgemeine Attribute der Suchregel):
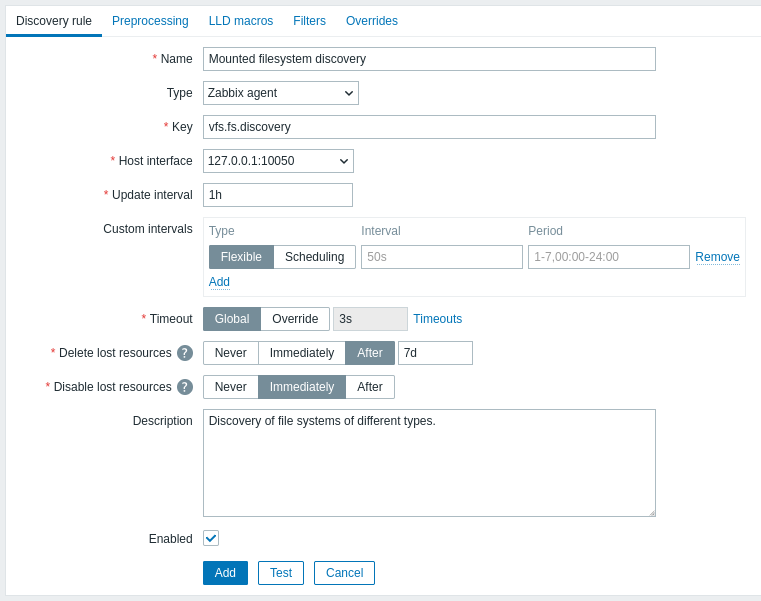
Alle erforderlichen Eingabefelder sind mit einem roten Sternchen markiert.
| Parameter | Beschreibung |
|---|---|
| Name | Name der Suchregel. |
| Type | Der Typ der Prüfung, mit der die Suche durchgeführt wird. In diesem Beispiel verwenden wir den Datenpunkttyp Zabbix Agent. Die Suchregel kann auch ein abhängiger Datenpunkt sein, der von einem regulären Datenpunkt abhängt. Sie kann nicht von einer anderen Suchregel abhängen. Wählen Sie für einen abhängigen Datenpunkt den entsprechenden Typ (Dependent item) aus und geben Sie den Master-Datenpunkt im Feld 'Master item' an. Der Master-Datenpunkt muss vorhanden sein. |
| Key | Geben Sie den Schlüssel des Such-Datenpunkts ein (bis zu 2048 Zeichen). Sie können zum Beispiel den integrierten Datenpunktschlüssel "vfs.fs.discovery" verwenden, um eine JSON-Zeichenfolge mit der Liste der auf dem Computer vorhandenen Dateisysteme, ihren Typen und Einhängeoptionen zurückzugeben. Beachten Sie, dass eine weitere Möglichkeit zur Dateisystemsuche darin besteht, Suchergebnisse über den Agent-Schlüssel "vfs.fs.get" zu verwenden (siehe Beispiel). |
| Update interval | Dieses Feld gibt an, wie oft Zabbix die Suche durchführt. Zu Beginn, wenn Sie die Dateisystemsuche gerade einrichten, möchten Sie möglicherweise ein kurzes Intervall festlegen. Sobald Sie jedoch wissen, dass sie funktioniert, können Sie es auf 30 Minuten oder mehr setzen, da sich Dateisysteme normalerweise nicht sehr oft ändern. Zeitsuffixe werden unterstützt, z. B. 30s, 1m, 2h, 1d. Benutzermakros werden unterstützt. Hinweis: Das Aktualisierungsintervall kann nur dann auf '0' gesetzt werden, wenn benutzerdefinierte Intervalle mit einem Wert ungleich null vorhanden sind. Wenn es auf '0' gesetzt ist und ein benutzerdefiniertes Intervall (flexibel oder geplant) mit einem Wert ungleich null vorhanden ist, wird der Datenpunkt während der Dauer des benutzerdefinierten Intervalls abgefragt. Neue Suchregeln werden innerhalb von 60 Sekunden nach ihrer Erstellung geprüft, es sei denn, sie haben Scheduling oder Flexible update interval und das Update interval ist auf 0 gesetzt. Beachten Sie, dass bei einer vorhandenen Suchregel die Suche sofort durchgeführt werden kann, indem Sie die Schaltfläche Execute now button drücken. |
| Custom intervals | Sie können benutzerdefinierte Regeln für die Prüfung des Datenpunkts erstellen: Flexible - erstellt eine Ausnahme zum Update interval (Intervall mit anderer Häufigkeit) Scheduling - erstellt einen benutzerdefinierten Abfragezeitplan. Detaillierte Informationen finden Sie unter Custom intervals. |
| Timeout | Legen Sie das Timeout für die Suchprüfung fest. Wählen Sie die Timeout-Option: Global - es wird das Proxy-/globale Timeout verwendet (angezeigt im ausgegrauten Feld Timeout); Override - es wird ein benutzerdefiniertes Timeout verwendet (im Feld Timeout festgelegt; zulässiger Bereich: 1 - 600s). Zeitsuffixe, z. B. 30s, 1m, und Benutzermakros werden unterstützt. Durch Klicken auf den Link Timeouts können Sie Proxy-Timeouts oder globale Timeouts konfigurieren (wenn kein Proxy verwendet wird). Beachten Sie, dass der Link Timeouts nur für Benutzer vom Typ Super admin sichtbar ist, die Berechtigungen für die Frontend-Bereiche Administration > General oder Administration > Proxies haben. |
| Delete lost resources | Geben Sie an, wie schnell die gefundene Entität gelöscht wird, sobald ihr Suchstatus zu "Not discovered anymore" wird: Never - sie wird nicht gelöscht; Immediately - sie wird sofort gelöscht; After - sie wird nach dem angegebenen Zeitraum gelöscht. Der Wert muss größer sein als der Wert von Disable lost resources. Zeitsuffixe werden unterstützt, z. B. 2h, 1d. Benutzermakros werden unterstützt. Hinweis: Die Verwendung von "Immediately" wird nicht empfohlen, da bereits eine fehlerhafte Bearbeitung des Filters dazu führen kann, dass die Entität zusammen mit allen Verlaufsdaten gelöscht wird. Beachten Sie, dass manuell deaktivierte Ressourcen nicht durch Low-Level-Discovery gelöscht werden. |
| Disable lost resources | Geben Sie an, wie schnell die gefundene Entität deaktiviert wird, sobald ihr Suchstatus zu "Not discovered anymore" wird: Never - sie wird nicht deaktiviert; Immediately - sie wird sofort deaktiviert; After - sie wird nach dem angegebenen Zeitraum deaktiviert. Der Wert sollte größer sein als das Aktualisierungsintervall der Suchregel. Beachten Sie, dass automatisch deaktivierte Ressourcen wieder aktiviert werden, wenn sie durch Low-Level-Discovery erneut gefunden werden. Manuell deaktivierte Ressourcen werden bei erneuter Suche nicht wieder aktiviert. Dieses Feld wird nicht angezeigt, wenn Delete lost resources auf "Immediately" gesetzt ist. Zeitsuffixe werden unterstützt, z. B. 2h, 1d. Benutzermakros werden unterstützt. |
| Description | Geben Sie eine Beschreibung ein. |
| Enabled | Wenn diese Option aktiviert ist, wird die Regel verarbeitet. |
Der Verlauf der Suchregel wird nicht beibehalten.
Vorverarbeitung
Die Registerkarte Vorverarbeitung ermöglicht es, Transformationsregeln zu definieren, die auf das Ergebnis der Erkennung angewendet werden. In diesem Schritt sind eine oder mehrere Transformationen möglich. Die Transformationen werden in der Reihenfolge ausgeführt, in der sie definiert sind. Die gesamte Vorverarbeitung wird vom Zabbix Server durchgeführt.
Siehe auch:
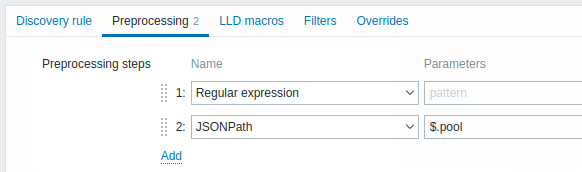
| Type | ||
|---|---|---|
| Transformation | Beschreibung | |
| Text | ||
| Regulärer Ausdruck | Vergleicht den empfangenen Wert mit dem regulären Ausdruck <pattern> und ersetzt den Wert durch den extrahierten <output>. Der reguläre Ausdruck unterstützt die Extraktion von maximal 10 erfassten Gruppen mit der Sequenz \N. Parameter: pattern - regulärer Ausdruck output - Ausgabeformatvorlage. Eine Escape-Sequenz \N (wobei N=1…9) wird durch die N-te übereinstimmende Gruppe ersetzt. Eine Escape-Sequenz \0 wird durch den übereinstimmenden Text ersetzt. Wenn Sie das Kontrollkästchen Custom on fail aktivieren, können benutzerdefinierte Fehlerbehandlungsoptionen angegeben werden: entweder den Wert verwerfen, einen angegebenen Wert setzen oder eine angegebene Fehlermeldung setzen. |
|
| Ersetzen | Sucht nach der Suchzeichenfolge und ersetzt sie durch eine andere Zeichenfolge (oder durch nichts). Alle Vorkommen der Suchzeichenfolge werden ersetzt. Parameter: search string - die zu suchende und zu ersetzende Zeichenfolge, unter Berücksichtigung der Groß-/Kleinschreibung (erforderlich) replacement - die Zeichenfolge, durch die die Suchzeichenfolge ersetzt werden soll. Die Ersetzungszeichenfolge kann auch leer sein, wodurch die Suchzeichenfolge bei Fund effektiv gelöscht wird. Es ist möglich, Escape-Sequenzen zu verwenden, um Zeilenumbrüche, Wagenrücklauf, Tabulatoren und Leerzeichen zu suchen oder zu ersetzen: "\n \r \t \s"; der Backslash kann als "\\" und Escape-Sequenzen können als "\\n" maskiert werden. Das Maskieren von Zeilenumbrüchen, Wagenrücklauf und Tabulatoren erfolgt während der Low-Level-Erkennung automatisch. |
|
| Strukturierte Daten | ||
| JSONPath | Extrahiert einen Wert oder ein Fragment aus JSON-Daten mithilfe der JSONPath-Funktionalität. Wenn Sie das Kontrollkästchen Custom on fail aktivieren, können benutzerdefinierte Fehlerbehandlungsoptionen angegeben werden: entweder den Wert verwerfen, einen angegebenen Wert setzen oder eine angegebene Fehlermeldung setzen. |
|
| XML XPath | Extrahiert einen Wert oder ein Fragment aus XML-Daten mithilfe der XPath-Funktionalität. Damit diese Option funktioniert, muss der Zabbix Server mit libxml-Unterstützung kompiliert sein. Beispiele: number(/document/item/value) extrahiert 10 aus <document><item><value>10</value></item></document>number(/document/item/@attribute) extrahiert 10 aus <document><item attribute="10"></item></document>/document/item extrahiert <item><value>10</value></item> aus <document><item><value>10</value></item></document>Beachten Sie, dass Namespaces nicht unterstützt werden. Wenn Sie das Kontrollkästchen Custom on fail aktivieren, können benutzerdefinierte Fehlerbehandlungsoptionen angegeben werden: entweder den Wert verwerfen, einen angegebenen Wert setzen oder eine angegebene Fehlermeldung setzen. |
|
| CSV zu JSON | Konvertiert CSV-Dateidaten in das JSON-Format. Weitere Informationen finden Sie unter: CSV zu JSON-Vorverarbeitung. |
|
| XML zu JSON | Konvertiert Daten im XML-Format in JSON. Weitere Informationen finden Sie unter: Serialisierungsregeln. Wenn Sie das Kontrollkästchen Custom on fail aktivieren, können benutzerdefinierte Fehlerbehandlungsoptionen angegeben werden: entweder den Wert verwerfen, einen angegebenen Wert setzen oder eine angegebene Fehlermeldung setzen. |
|
| SNMP | ||
| SNMP walk value | Extrahiert einen Wert anhand der angegebenen OID/MIB-Bezeichnung und wendet Formatierungsoptionen an: Unchanged - gibt Hex-STRING als nicht maskierte Hex-Zeichenfolge zurück (Hinweis: Anzeigehinweise werden weiterhin angewendet); UTF-8 from Hex-STRING - konvertiert Hex-STRING in eine UTF-8-Zeichenfolge; MAC from Hex-STRING - konvertiert Hex-STRING in eine MAC-Adresszeichenfolge (wobei ' ' durch ':' ersetzt wird);Integer from BITS - konvertiert die ersten 8 Bytes einer Bitzeichenfolge, die als Folge von Hex-Zeichen ausgedrückt ist (z. B. "1A 2B 3C 4D"), in eine vorzeichenlose 64-Bit-Ganzzahl. Bei Bitzeichenfolgen, die länger als 8 Bytes sind, werden die folgenden Bytes ignoriert. Wenn Sie das Kontrollkästchen Custom on fail aktivieren, können benutzerdefinierte Fehlerbehandlungsoptionen angegeben werden: entweder den Wert verwerfen, einen angegebenen Wert setzen oder eine angegebene Fehlermeldung setzen. |
|
| SNMP walk to JSON | Konvertiert SNMP-Werte in JSON. Geben Sie einen Feldnamen im JSON und den entsprechenden SNMP-OID-Pfad an. Feldwerte werden mit Werten aus dem angegebenen SNMP-OID-Pfad gefüllt. Sie können diesen Vorverarbeitungsschritt für die SNMP OID-Erkennung verwenden. Ähnliche Formatierungsoptionen wie im Schritt SNMP walk value sind verfügbar. Wenn Sie das Kontrollkästchen Custom on fail aktivieren, können benutzerdefinierte Fehlerbehandlungsoptionen angegeben werden: entweder den Wert verwerfen, einen angegebenen Wert setzen oder eine angegebene Fehlermeldung setzen. |
|
| SNMP get value | Wendet Formatierungsoptionen auf den SNMP-get-Wert an: UTF-8 from Hex-STRING - konvertiert Hex-STRING in eine UTF-8-Zeichenfolge; MAC from Hex-STRING - konvertiert Hex-STRING in eine MAC-Adresszeichenfolge (wobei ' ' durch ':' ersetzt wird);Integer from BITS - konvertiert die ersten 8 Bytes einer Bitzeichenfolge, die als Folge von Hex-Zeichen ausgedrückt ist (z. B. "1A 2B 3C 4D"), in eine vorzeichenlose 64-Bit-Ganzzahl. Bei Bitzeichenfolgen, die länger als 8 Bytes sind, werden die folgenden Bytes ignoriert. Wenn Sie das Kontrollkästchen Custom on fail aktivieren, können benutzerdefinierte Fehlerbehandlungsoptionen angegeben werden: entweder den Wert verwerfen, einen angegebenen Wert setzen oder eine angegebene Fehlermeldung setzen. |
|
| Benutzerdefinierte Skripte | ||
| JavaScript | Geben Sie JavaScript-Code im modalen Editor ein, der sich öffnet, wenn Sie in das Parameterfeld oder auf das Stiftsymbol daneben klicken. Beachten Sie, dass die verfügbare JavaScript-Länge von der verwendeten Datenbank abhängt. Weitere Informationen finden Sie unter: JavaScript-Vorverarbeitung |
|
| Validierung | ||
| Entspricht nicht dem regulären Ausdruck | Geben Sie einen regulären Ausdruck an, dem ein Wert nicht entsprechen darf. Z. B. Error:(.*?)\.Wenn Sie das Kontrollkästchen Custom on fail aktivieren, können benutzerdefinierte Fehlerbehandlungsoptionen angegeben werden: entweder den Wert verwerfen, einen angegebenen Wert setzen oder eine angegebene Fehlermeldung setzen. |
|
| Auf Fehler in JSON prüfen | Prüft auf eine Fehlermeldung auf Anwendungsebene, die sich an der JSONPath befindet. Die Verarbeitung wird beendet, wenn der Vorgang erfolgreich war und die Meldung nicht leer ist; andernfalls wird die Verarbeitung mit dem Wert fortgesetzt, der vor diesem Vorverarbeitungsschritt vorhanden war. Beachten Sie, dass diese Fehler externer Dienste dem Benutzer unverändert gemeldet werden, ohne Informationen zum Vorverarbeitungsschritt hinzuzufügen. Z. B. $.errors. Wenn ein JSON wie {"errors":"e1"} empfangen wird, wird der nächste Vorverarbeitungsschritt nicht ausgeführt.Wenn Sie das Kontrollkästchen Custom on fail aktivieren, können benutzerdefinierte Fehlerbehandlungsoptionen angegeben werden: entweder den Wert verwerfen, einen angegebenen Wert setzen oder eine angegebene Fehlermeldung setzen. |
|
| Auf Fehler in XML prüfen | Prüft auf eine Fehlermeldung auf Anwendungsebene, die sich an der Xpath befindet. Die Verarbeitung wird beendet, wenn der Vorgang erfolgreich war und die Meldung nicht leer ist; andernfalls wird die Verarbeitung mit dem Wert fortgesetzt, der vor diesem Vorverarbeitungsschritt vorhanden war. Beachten Sie, dass diese Fehler externer Dienste dem Benutzer unverändert gemeldet werden, ohne Informationen zum Vorverarbeitungsschritt hinzuzufügen. Im Falle eines Fehlers beim Parsen von ungültigem XML wird kein Fehler gemeldet. Wenn Sie das Kontrollkästchen Custom on fail aktivieren, können benutzerdefinierte Fehlerbehandlungsoptionen angegeben werden: entweder den Wert verwerfen, einen angegebenen Wert setzen oder eine angegebene Fehlermeldung setzen. |
|
| Entspricht dem regulären Ausdruck | Geben Sie einen regulären Ausdruck an, dem ein Wert entsprechen muss. Wenn Sie das Kontrollkästchen Custom on fail aktivieren, können benutzerdefinierte Fehlerbehandlungsoptionen angegeben werden: entweder den Wert verwerfen, einen angegebenen Wert setzen oder eine angegebene Fehlermeldung setzen. |
|
| Drosselung | ||
| Unveränderte Werte mit Heartbeat verwerfen | Verwirft einen Wert, wenn er sich innerhalb des definierten Zeitraums (in Sekunden) nicht geändert hat. Es werden positive Ganzzahlwerte unterstützt, um die Sekunden anzugeben (Minimum - 1 Sekunde). In diesem Feld können Zeitsuffixe verwendet werden (z. B. 30s, 1m, 2h, 1d). In diesem Feld können Benutzermakros und Low-Level-Discovery-Makros verwendet werden. Für einen Erkennungseintrag kann nur eine Drosselungsoption angegeben werden. Z. B. 1m. Wenn derselbe Text innerhalb von 60 Sekunden zweimal an diese Regel übergeben wird, wird er verworfen.Hinweis: Das Ändern von Item-Prototypen setzt die Drosselung nicht zurück. Die Drosselung wird nur zurückgesetzt, wenn Vorverarbeitungsschritte geändert werden. |
|
| Prometheus | ||
| Prometheus zu JSON | Konvertiert die erforderlichen Prometheus-Metriken in JSON. Weitere Informationen finden Sie unter Prometheus-Prüfungen. |
|
Beachten Sie, dass der Inhalt dieser Registerkarte schreibgeschützt ist, wenn die Erkennungsregel über eine Vorlage auf den Host angewendet wurde.
Benutzerdefinierte Makros
Auf der Registerkarte LLD-Makros können Sie benutzerdefinierte LLD-Makros angeben, wenn das zurückgegebene JSON noch keine Schlüssel im Format {#MACRO} enthält.
Beispielsweise gibt der Agent-Datenpunkt-Schlüssel vfs.fs.get JSON-Dateisystemdaten ohne vordefinierte LLD-Makros zurück.
Hier definieren Sie die Makros manuell und ordnen sie mithilfe von JSONPath-Ausdrücken Werten im JSON zu:
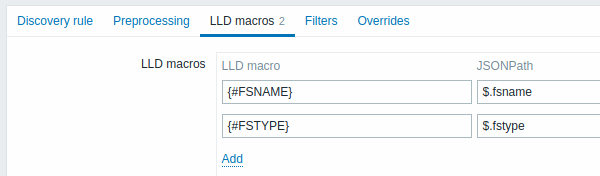
| Parameter | Beschreibung |
|---|---|
| LLD macro | Name des LLD-Makros im Format {#MACRO}. |
| JSONPath | Ausdruck, der festlegt, welcher Wert aus jeder erkannten Entität im JSON-Array extrahiert werden soll. Beispielsweise extrahiert $.foo "bar" und "baz" aus[{"foo":"bar"}, {"foo":"baz"}].JSONPath unterstützt sowohl Punkt- als auch Klammernotation. Die Klammernotation muss für Schlüssel mit Sonderzeichen oder Unicode verwendet werden, z. B. $['unicode + special chars #1']['unicode + special chars #2']. |
Die Erkennungsregel muss ein JSON-Array auf der Wurzelebene ($.) zurückgeben.
Aus Gründen der Abwärtskompatibilität wird auch ein JSON-Objekt akzeptiert, das ein einzelnes "data"-Array enthält. In diesem Fall wird das "data"-Array automatisch entpackt:
{"data":[{"foo":"bar"}, {"foo":"baz"}]}Filter
Ein Filter kann verwendet werden, um echte Datenpunkte, Auslöser und Diagramme nur für Entitäten zu erzeugen, die die Kriterien erfüllen. Die Registerkarte Filters enthält Filterdefinitionen für Erkennungsregeln und ermöglicht das Filtern von Erkennungswerten:
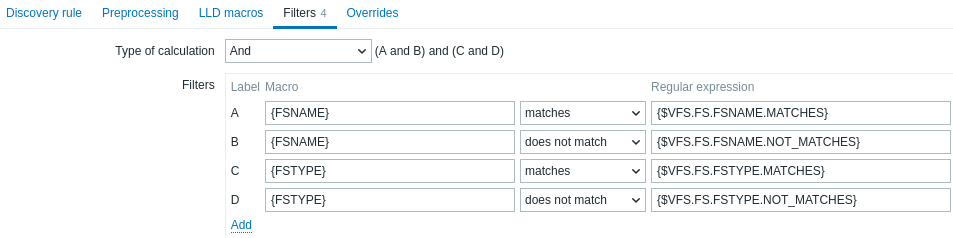
| Parameter | Beschreibung |
|---|---|
| Type of calculation | Für die Berechnung von Filtern stehen die folgenden Optionen zur Verfügung: And - alle Filter müssen erfüllt sein; Or - es reicht aus, wenn ein Filter erfüllt ist; And/Or - verwendet And bei unterschiedlichen Makronamen und Or beim gleichen Makronamen; Custom expression - bietet die Möglichkeit, eine benutzerdefinierte Berechnung der Filter zu definieren. Die Formel muss alle Filter in der Liste enthalten. Auf 255 Zeichen begrenzt. |
| Filters | Die folgenden Filterbedingungsoperatoren sind verfügbar: matches, does not match, exists, does not exist. Die Operatoren matches und does not match erwarten einen Perl Compatible Regular Expression (PCRE). Sie können im Feld Regular expression einen regulären Ausdruck eingeben oder auf einen globalen regular expression verweisen. Die Operatoren exists und does not exist ermöglichen das Filtern von Entitäten anhand des Vorhandenseins oder Fehlens des angegebenen LLD-Makros in der Antwort. Beachten Sie, dass eine gefundene Entität ignoriert wird, wenn ein Makro aus dem Filter in der Antwort fehlt, sofern für dieses Makro keine Bedingung "does not exist" angegeben ist. Es wird eine Warnung angezeigt, wenn das Fehlen eines Makros das Ergebnis des Ausdrucks beeinflusst. Wenn beispielsweise {#B} fehlt in:{#A} matches 1 and {#B} matches 2 - wird eine Warnung ausgegeben{#A} matches 1 or {#B} matches 2 - keine Warnung. |
Wenn Sie beispielsweise nur an den Dateisystemen C:, D: und E: interessiert sind, können Sie {#FSNAME} in das Feld Macro und ^C|^D|^E in das Feld Regular expression eintragen.
Eine Filterung ist auch nach Dateisystemtypen mithilfe des Makros {#FSTYPE} möglich (z. B. ^ext|^reiserfs) sowie nach Laufwerkstypen (nur vom Windows-Agent unterstützt) mithilfe des Makros {#FSDRIVETYPE} (z. B. fixed).
Um einen regulären Ausdruck zu testen, können Sie beispielsweise grep -E verwenden:
for f in ext2 nfs reiserfs smbfs;
do echo $f | grep -E '^ext|^reiserfs' || echo "SKIP: $f";
doneEin Fehler oder ein Tippfehler im regulären Ausdruck, der in der LLD-Regel verwendet wird (z. B. ein falscher regulärer Ausdruck für "File systems for discovery"), kann dazu führen, dass Tausende von Konfigurationselementen, historischen Werten und Ereignissen für viele Hosts gelöscht werden.
Die Zabbix-Datenbank in MySQL muss mit Berücksichtigung der Groß- und Kleinschreibung erstellt werden, damit sich nur durch die Groß-/Kleinschreibung unterscheidende Dateisystemnamen korrekt erkannt werden können.
Override
Die Registerkarte Overrides ermöglicht das Festlegen von Regeln, um die Liste der Datenpunkt-, Auslöser-, Diagramm-, Host- und Discovery-Prototypen oder deren Attribute für erkannte Objekte zu ändern, die die angegebenen Kriterien erfüllen.
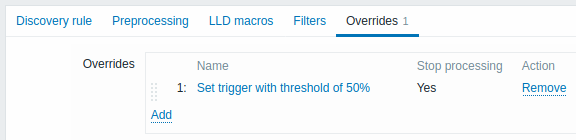
Overrides werden, sofern vorhanden, in einer per Drag-and-drop neu anordbaren Liste angezeigt und in der Reihenfolge ausgeführt, in der sie definiert sind. Um Details eines neuen Overrides zu konfigurieren, klicken Sie im Block Overrides auf  .
Um einen vorhandenen Override zu bearbeiten, klicken Sie auf den Namen des Overrides.
Es wird ein Popup-Fenster geöffnet, in dem Sie die Details der Override-Regel bearbeiten können.
.
Um einen vorhandenen Override zu bearbeiten, klicken Sie auf den Namen des Overrides.
Es wird ein Popup-Fenster geöffnet, in dem Sie die Details der Override-Regel bearbeiten können.
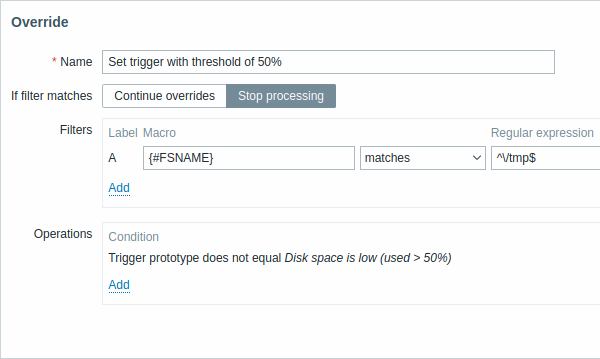
Alle Pflichtparameter sind mit roten Sternchen markiert.
| Parameter | Beschreibung |
|---|---|
| Name | Ein eindeutiger Override-Name (pro LLD-Regel). |
| If filter matches | Legt fest, ob die nächsten Overrides verarbeitet werden sollen, wenn die Filterbedingungen erfüllt sind: Continue overrides - nachfolgende Overrides werden verarbeitet. Stop processing - Operationen aus vorherigen Overrides (falls vorhanden) und diesem Override werden ausgeführt, nachfolgende Overrides werden für passende LLD-Zeilen ignoriert. |
| Filters | Bestimmt, auf welche erkannten Entitäten der Override angewendet werden soll. Override-Filter werden nach den Filtern der Discovery-Regel verarbeitet und haben dieselbe Funktionalität. |
| Operations | Override-Operationen werden mit folgenden Details angezeigt: Condition - ein Objekttyp und eine Bedingung, die für den Objektnamen erfüllt sein muss; zum Beispiel: Trigger prototype ist nicht gleich Disk space is low (used > 50%). Actions - Links zum Bearbeiten und Entfernen einer Operation werden angezeigt. |
Konfigurieren einer Operation
Um Details einer neuen Operation zu konfigurieren, klicken Sie im Block Operations auf .
Um eine vorhandene Operation zu bearbeiten, klicken Sie neben der Operation auf  .
Es wird ein Popup-Fenster geöffnet, in dem Sie die Details der Operation bearbeiten können.
.
Es wird ein Popup-Fenster geöffnet, in dem Sie die Details der Operation bearbeiten können.
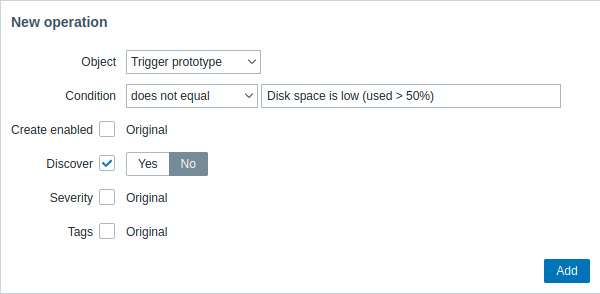
| Parameter | Beschreibung | ||
|---|---|---|---|
| Object | Es stehen fünf Objekttypen zur Verfügung: Datenpunkt-Prototyp Trigger prototype Graph prototype Host-Prototyp Discovery prototype |
||
| Condition | Ermöglicht das Filtern von Entitäten, auf die die Operation angewendet werden soll. | ||
| Operator | Unterstützte Operatoren: equals - auf diesen Prototyp anwenden does not equal - auf alle Prototypen außer diesem anwenden contains - anwenden, wenn der Prototypname diesen String enthält does not contain - anwenden, wenn der Prototypname diesen String nicht enthält matches - anwenden, wenn der Prototypname dem regulären Ausdruck entspricht does not match - anwenden, wenn der Prototypname dem regulären Ausdruck nicht entspricht |
||
| Pattern | Ein regulärer Ausdruck oder ein zu suchender String. | ||
| Object: Item prototype | |||
| Create enabled | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen die ursprünglichen Einstellungen des Datenpunkt-Prototyps überschrieben werden können: Yes - der Datenpunkt wird im aktivierten Zustand hinzugefügt. No - der Datenpunkt wird einer erkannten Entität hinzugefügt, jedoch im deaktivierten Zustand. |
||
| Discover | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen die ursprünglichen Einstellungen des Datenpunkt-Prototyps überschrieben werden können: Yes - der Datenpunkt wird hinzugefügt. No - der Datenpunkt wird nicht hinzugefügt. |
||
| Update interval | Wenn das Kontrollkästchen aktiviert ist, werden zwei Optionen angezeigt, mit denen ein anderes Intervall für den Datenpunkt festgelegt werden kann: Delay - Aktualisierungsintervall des Datenpunkts. Benutzermakros, LLD-Makros und Zeitsuffixe (z. B. 30s, 1m, 2h, 1d) werden unterstützt. Sollte auf 0 gesetzt werden, wenn Custom interval verwendet wird. Custom interval - klicken Sie auf , um flexible/geplante Intervalle anzugeben. Weitere Informationen finden Sie unter Custom intervals. |
||
| History | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen ein anderer Aufbewahrungszeitraum für den Datenpunkt festgelegt werden kann: Do not store - wenn ausgewählt, wird der Verlauf nicht gespeichert. Store up to - wenn ausgewählt, wird rechts ein Eingabefeld zur Angabe des Aufbewahrungszeitraums angezeigt. Benutzermakros und LLD-Makros werden unterstützt. |
||
| Trends | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen ein anderer Aufbewahrungszeitraum für die Trends des Datenpunkts festgelegt werden kann: Do not store - wenn ausgewählt, werden die Trends nicht gespeichert. Store up to - wenn ausgewählt, wird rechts ein Eingabefeld zur Angabe des Aufbewahrungszeitraums angezeigt. Benutzermakros und LLD-Makros werden unterstützt. |
||
| Tags | Wenn das Kontrollkästchen aktiviert ist, wird ein neuer Block angezeigt, in dem Tag-Wert-Paare angegeben werden können. Benutzermakros und LLD-Makros werden unterstützt. Diese Tags werden den im Datenpunkt-Prototyp angegebenen Tags angehängt, auch wenn die Tag-Namen übereinstimmen. |
||
| Object: Trigger prototype | |||
| Create enabled | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen die ursprünglichen Einstellungen des Trigger-Prototyps überschrieben werden können: Yes - der Auslöser wird im aktivierten Zustand hinzugefügt. No - der Auslöser wird einer erkannten Entität hinzugefügt, jedoch im deaktivierten Zustand. |
||
| Discover | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen die ursprünglichen Einstellungen des Trigger-Prototyps überschrieben werden können: Yes - der Auslöser wird hinzugefügt. No - der Auslöser wird nicht hinzugefügt. |
||
| Severity | Wenn das Kontrollkästchen aktiviert ist, werden Schaltflächen für die Auslöser-Schweregrade angezeigt, mit denen die Schwere geändert werden kann. | ||
| Tags | Wenn das Kontrollkästchen aktiviert ist, wird ein neuer Block angezeigt, in dem Tag-Wert-Paare angegeben werden können. Benutzermakros und LLD-Makros werden unterstützt. Diese Tags werden den im Trigger-Prototyp angegebenen Tags angehängt, auch wenn die Tag-Namen übereinstimmen. |
||
| Object: Graph prototype | |||
| Discover | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen die ursprünglichen Einstellungen des Graph-Prototyps überschrieben werden können: Yes - das Diagramm wird hinzugefügt. No - das Diagramm wird nicht hinzugefügt. |
||
| Object: Host prototype | |||
| Create enabled | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen die ursprünglichen Einstellungen des Host-Prototyps überschrieben werden können: Yes - der Host wird im aktivierten Zustand erstellt. No - der Host wird im deaktivierten Zustand erstellt. |
||
| Discover | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen die ursprünglichen Einstellungen des Host-Prototyps überschrieben werden können: Yes - der Host wird erkannt. No - der Host wird nicht erkannt. |
||
| Link templates | Wenn das Kontrollkästchen aktiviert ist, wird ein Eingabefeld zur Angabe von Vorlagen angezeigt. Beginnen Sie mit der Eingabe des Vorlagennamens oder klicken Sie neben dem Feld auf Select und wählen Sie Vorlagen aus der Liste im Popup-Fenster aus. Vorlagen aus diesem Override werden allen bereits mit dem Host-Prototyp verknüpften Vorlagen hinzugefügt. |
||
| Tags | Wenn das Kontrollkästchen aktiviert ist, wird ein neuer Block angezeigt, in dem Tag-Wert-Paare angegeben werden können. Benutzermakros und LLD-Makros werden unterstützt. Diese Tags werden den im Host-Prototyp angegebenen Tags angehängt, auch wenn die Tag-Namen übereinstimmen. |
||
| Host inventory | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen ein anderer Modus für das Host-Prototyp-Inventar ausgewählt werden kann: Disabled - Host-Inventar nicht befüllen Manual - Details manuell angeben Automated - Host-Inventardaten automatisch auf Basis der gesammelten Metriken ausfüllen. |
||
| Object: Discovery prototype | |||
| Create enabled | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen die ursprünglichen Einstellungen des Discovery-Prototyps überschrieben werden können: Yes - die Discovery-Regel wird im aktivierten Zustand hinzugefügt. No - die Discovery-Regel wird im deaktivierten Zustand hinzugefügt. |
||
| Discover | Wenn das Kontrollkästchen aktiviert ist, werden die Schaltflächen angezeigt, mit denen die ursprünglichen Einstellungen des Discovery-Prototyps überschrieben werden können: Yes - die Discovery-Regel wird hinzugefügt. No - die Discovery-Regel wird nicht hinzugefügt. |
||
| Update interval | Wenn das Kontrollkästchen aktiviert ist, werden zwei Optionen angezeigt, mit denen ein anderes Intervall für die Discovery-Regel festgelegt werden kann: Delay - Aktualisierungsintervall der Regel. Benutzermakros, LLD-Makros und Zeitsuffixe (z. B. 30s, 1m, 2h, 1d) werden unterstützt. Sollte auf 0 gesetzt werden, wenn Custom interval verwendet wird. Custom interval - klicken Sie auf , um flexible/geplante Intervalle anzugeben. Weitere Informationen finden Sie unter Custom intervals. |
||
Formularschaltflächen
Mit den Schaltflächen am unteren Rand des Formulars können mehrere Operationen ausgeführt werden.
 |
Eine Discovery-Regel hinzufügen. Diese Schaltfläche ist nur für neue Discovery-Regeln verfügbar. |
 |
Die Eigenschaften einer Discovery-Regel aktualisieren. Diese Schaltfläche ist nur für vorhandene Discovery-Regeln verfügbar. |
 |
Eine weitere Discovery-Regel auf Grundlage der Eigenschaften der aktuellen Discovery-Regel erstellen. |
 |
Die Discovery sofort auf Grundlage der Discovery-Regel ausführen. Die Discovery-Regel muss bereits vorhanden sein. Siehe weitere Details. Hinweis: Wenn die Discovery sofort ausgeführt wird, wird der Konfigurations-Cache nicht aktualisiert; daher spiegelt das Ergebnis keine sehr aktuellen Änderungen an der Konfiguration der Discovery-Regel wider. |
 |
Die Konfiguration der Discovery-Regel testen. Verwenden Sie diese Schaltfläche, um die Konfigurationseinstellungen (z. B. Konnektivität und Korrektheit der Parameter) zu überprüfen, ohne Änderungen dauerhaft anzuwenden. |
 |
Die Discovery-Regel löschen. |
 |
Die Bearbeitung der Eigenschaften der Discovery-Regel abbrechen. |
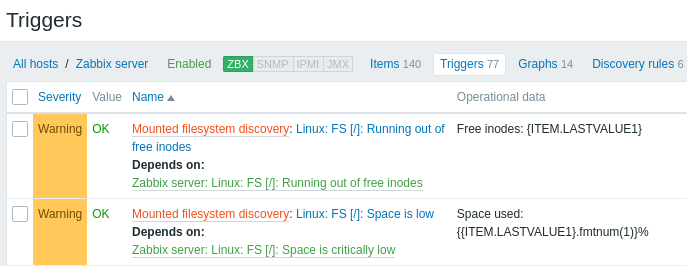
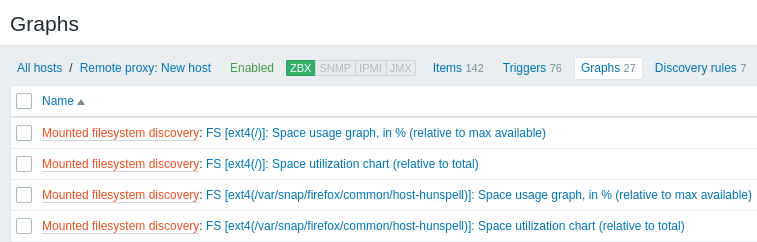
Erkannte Entitäten
Die folgenden Screenshots veranschaulichen, wie erkannte Datenpunkte, Auslöser und Diagramme in der Konfiguration des Hosts aussehen. Erkannte Entitäten sind mit einem orangefarbenen Link zu der Discovery-Regel versehen, aus der sie stammen.
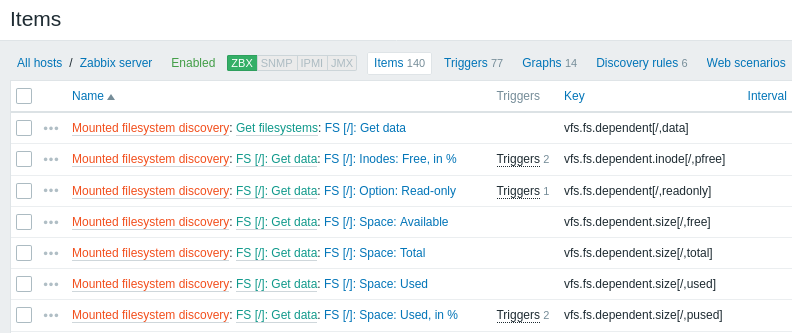
Beachten Sie, dass erkannte Entitäten nicht erstellt werden, wenn bereits vorhandene Entitäten mit denselben Eindeutigkeitskriterien existieren, zum Beispiel ein Datenpunkt mit demselben Schlüssel oder ein Diagramm mit demselben Namen. In diesem Fall wird im Frontend eine Fehlermeldung angezeigt, dass die Low-Level-Discovery-Regel bestimmte Entitäten nicht erstellen konnte. Die Discovery-Regel selbst wird jedoch nicht auf „nicht unterstützt“ gesetzt, nur weil eine Entität nicht erstellt werden konnte und übersprungen werden musste. Die Discovery-Regel fährt mit dem Erstellen/Aktualisieren anderer Entitäten fort.
Wenn eine erkannte Entität (Host, Dateisystem, Schnittstelle usw.) nicht mehr erkannt wird (oder den Filter nicht mehr erfüllt), können die auf ihrer Grundlage erstellten Entitäten automatisch deaktiviert und schließlich gelöscht werden.
Verlorene Ressourcen können basierend auf dem Wert des Parameters Disable lost resources automatisch deaktiviert werden. Dies betrifft verlorene Hosts, Datenpunkte und Auslöser.
Verlorene Ressourcen können basierend auf dem Wert des Parameters Delete lost resources automatisch gelöscht werden. Dies betrifft verlorene Hosts, Hostgruppen, Datenpunkte, Auslöser und Diagramme.
Wenn erkannte Entitäten den Status „Nicht mehr erkannt“ erhalten, wird in der Entitätenliste ein Lebensdauerindikator angezeigt. Bewegen Sie den Mauszeiger darüber, und es wird eine Meldung mit Details zu ihrem Status angezeigt.

Wenn Entitäten zum Löschen markiert wurden, aber nicht zum erwarteten Zeitpunkt gelöscht wurden (deaktivierte Discovery-Regel oder Datenpunkt-Host), werden sie beim nächsten Verarbeiten der Discovery-Regel gelöscht.
Entitäten, die andere Entitäten enthalten und zum Löschen markiert sind, werden nicht aktualisiert, wenn sie auf Ebene der Discovery-Regel geändert werden. Zum Beispiel werden LLD-basierte Auslöser nicht aktualisiert, wenn sie Datenpunkte enthalten, die zum Löschen markiert sind.
Andere Arten der Discovery
Weitere Details und Anleitungen zu anderen Arten der sofort einsatzbereiten Discovery finden Sie in den folgenden Abschnitten:
- Discovery von Netzwerkschnittstellen
- Discovery von CPUs und CPU-Kernen
- Discovery von SNMP-OIDs
- Discovery von JMX-Objekten;
- Discovery mit ODBC-SQL-Abfragen
- Discovery von Windows-Diensten
- Discovery von Host-Schnittstellen in Zabbix
Weitere Details zum JSON-Format für Discovery-Datenpunkte sowie ein Beispiel dafür, wie Sie Ihren eigenen Dateisystem-Discoverer als Perl-Skript implementieren, finden Sie unter Erstellen benutzerdefinierter LLD-Regeln.