
エスカレーション
概要
エスカレーションを使用すると、通知の送信やリモートコマンドの実行のための カスタムシナリオを作成できます。
実際には、これは次のことを意味します。
- ユーザーは新しい障害について即座に通知を受けることができます。
- 障害が解決されるまで通知を繰り返すことができます。
- 通知の送信を遅らせることができます。
- 通知を別の「より上位の」ユーザーグループにエスカレーションできます。
- リモートコマンドは、即座に実行することも、障害が長時間解決されない場合に実行することもできます。
アクションは、エスカレーションステップ に基づいてエスカレーションされます。各ステップには 継続時間があります。
デフォルトの継続時間と、個々のステップのカスタム継続時間の両方を 定義できます。1つのエスカレーションステップの最小継続時間は60秒です。
通知の送信やコマンドの実行などのアクションは、任意のステップから開始できます。 ステップ1は即時アクション用です。アクションを遅らせたい場合は、 後のステップに割り当てることができます。各ステップに対して、 複数のアクションを定義できます。
エスカレーションステップの数に制限はありません。
エスカレーションは、実行内容の設定時に定義します。エスカレーションは 障害時の実行内容でのみサポートされ、復旧時にはサポートされません。
エスカレーション動作のその他の側面
アクションに複数のエスカレーションステップが含まれている場合、さまざまな状況で何が起こるかを見てみましょう。
| 状況 | 動作 |
|---|---|
| 対象のホストが、最初の問題通知の送信後にメンテナンス状態に入る | アクション設定の Pause operations for suppressed problems 設定に応じて、残りのすべてのエスカレーションステップは、メンテナンス期間による遅延付きで実行されるか、遅延なしで実行されます。メンテナンス期間によって操作がキャンセルされることはありません。 |
| Time period アクション条件で定義された期間が、最初の通知の送信後に終了する | 残りのすべてのエスカレーションステップが実行されます。Time period 条件は操作を停止できません。これは、アクションが開始されるかどうかには影響しますが、操作には影響しません。 |
| 問題がメンテナンス中に発生し、メンテナンス終了後も継続する(解決されない) | アクション設定の Pause operations for suppressed problems 設定に応じて、すべてのエスカレーションステップはメンテナンス終了時点から、または直ちに実行されます。 |
| 問題が no-data メンテナンス中に発生し、メンテナンス終了後も継続する(解決されない) | すべてのエスカレーションステップが実行される前に、トリガーが発火するのを待つ必要があります。 |
| 異なるエスカレーションが短い間隔で続き、重なり合う | 新しいエスカレーションが実行されるたびに前のエスカレーションは上書きされますが、少なくとも 1 つのエスカレーションステップは常に前のエスカレーションで実行されます。この動作は、トリガーの EVERY problem evaluation で作成されるイベントに対するアクションで重要です。 |
| 進行中のエスカレーション(メッセージ送信中など)中に、任意の種類のイベントに基づいて: - アクションが無効化される トリガーイベントに基づいて: - トリガーが無効化される - ホストまたはアイテムが無効化される トリガーに関する内部イベントに基づいて: - トリガーが無効化される アイテム/低レベルディスカバリルールに関する内部イベントに基づいて: - アイテムが無効化される - ホストが無効化される |
進行中のメッセージは送信され、その後、エスカレーションでさらに 1 件のメッセージが送信されます。後続のメッセージでは、メッセージ本文の先頭にキャンセル文言(NOTE: Escalation canceled)が入り、理由が示されます(たとえば、NOTE: Escalation canceled: action '<Action name>' disabled)。これにより、受信者はエスカレーションがキャンセルされ、これ以上のステップが実行されないことを知ることができます。このメッセージは、以前に通知を受け取ったすべての相手に送信されます。キャンセル理由はサーバーログファイルにも記録されます(Debug Level 3=Warning から)。 Escalation canceled メッセージは、操作が終了していても、復旧操作が設定されていてまだ実行されていない場合にも送信されることに注意してください。 |
| 進行中のエスカレーション(メッセージ送信中など)中にアクションが削除される | それ以上メッセージは送信されません。この情報はサーバーログファイルに記録されます(Debug Level 3=Warning から)。例: escalation canceled: action id:334 deleted |
エスカレーション例
例1
30分ごとに繰り返し通知を送信する(合計5回)"MySQL Administrators"グループに送信します。設定方法は以下の通りです。
- オペレーションタブで、デフォルトのオペレーションステップの期間を"30m"(30分)に設定します。
- エスカレーションのステップを"1"から"5"までに設定します。
- メッセージの受信者として"MySQL Administrators"グループを選択します。
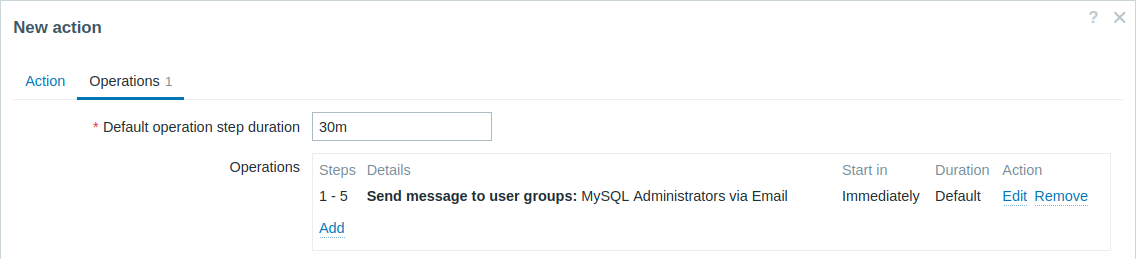
問題が発生してから0:00、0:30、1:00、1:30、2:00の時点で通知が送信されます(もちろん、問題がそれより早く解決された場合は除きます)。
問題が解決され、リカバリーメッセージが設定されている場合、このエスカレーションシナリオで少なくとも1つの問題メッセージを受信した人に送信されます。
アクティブなエスカレーションを生成したトリガーが 無効化された場合、Zabbixはすでに通知を受信したすべてのユーザーにその旨の情報メッセージを送信します。
例2
長時間継続している問題について遅延通知を送信します。設定方法:
- オペレーションタブで、デフォルトのオペレーションステップの期間を「10h」(10時間)に設定します。
- エスカレーションのステップを「2」から「2」に設定します。
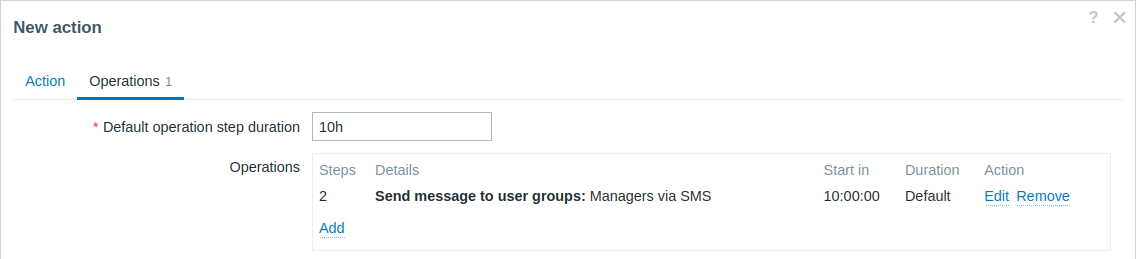
通知は、エスカレーションシナリオのステップ2、つまり問題発生から10時間後にのみ送信されます。
メッセージテキストを「問題が10時間以上継続しています」などにカスタマイズすることもできます。
例3
問題を上司にエスカレーションする。
上記の最初の例では、MySQL管理者への定期的なメッセージ送信を設定しました。この場合、管理者は問題がデータベースマネージャーにエスカレーションされる前に4回メッセージを受け取ります。マネージャーは、問題がまだ確認されていない場合、つまり誰も対応していない場合にのみメッセージを受け取ることに注意してください。
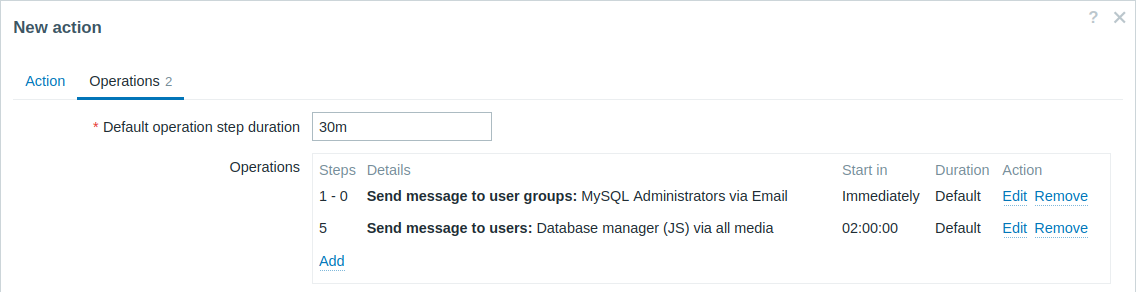
操作2の詳細:
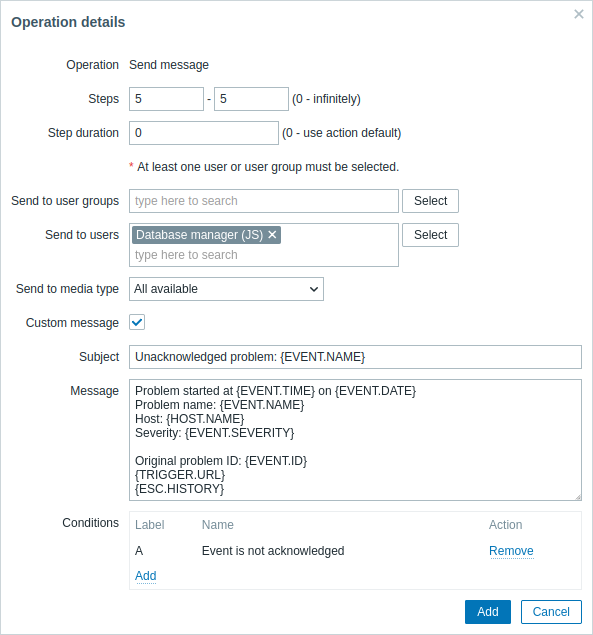
カスタマイズされたメッセージで{ESC.HISTORY}マクロを使用していることに注意してください。このマクロには、このエスカレーションで以前に実行されたすべてのステップ(送信された通知や実行されたコマンドなど)に関する情報が含まれます。
例 4
より複雑なシナリオ。 MySQL 管理者への複数のメッセージとマネージャーへのエスカレーションの後、Zabbix は MySQL データベースの再起動を試みます。 障害が 2:30 時間存在し、確認されていない場合に発生します。
それでも障害が解決しない場合は、さらに 30 分後に Zabbix がすべてのゲスト ユーザーにメッセージを送信します。
これで障害が解決しない場合は、さらに 1 時間後に、Zabbix は IPMI コマンドを使用して MySQL データベース (2 番目のリモート コマンド) でサーバーを再起動します。
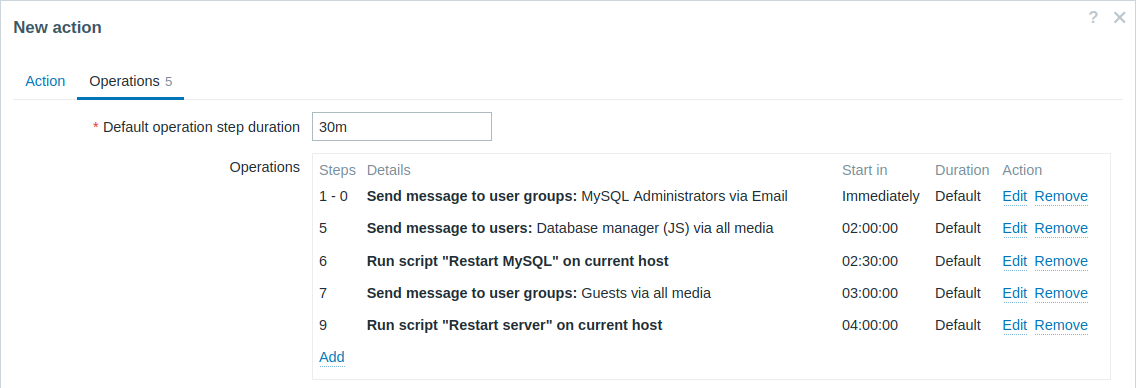
例5
重複するステップ範囲とカスタム間隔を持つ複数のオペレーションを含むエスカレーション。デフォルトのオペレーションステップの継続時間は30分です。

通知は以下のように送信されます。
- 問題発生後、MySQL管理者には0:00、0:30、1:00、1:30に通知されます。
- データベースマネージャーには2:00と2:10に通知されます(後続のオペレーションで定義された短いカスタムステップ継続時間10分が、ここで設定された長いステップ継続時間1時間を上書きします。これは、オペレーションの詳細のステップ継続時間で、ステップが重複する場合の動作として説明されています)。
- Zabbix管理者には、問題発生後2:00、2:10、2:20に通知されます(カスタムステップ継続時間10分が適用されます)。
- ゲストユーザーには、問題発生後4:00に通知されます(ステップ8と11の間はデフォルトのステップ継続時間30分が有効になります)。