
このページで
- #6 ログファイル監視
概要
Zabbixはログローテーションサポートの有無にかかわらずログファイルを集中的に監視し、分析することができます。
ログファイルが特定の文字列または文字列パターンを含む場合、通知レポートを使用してユーザーに警告することができます。
ログファイルを監視するには、次のものが必要です:
- ホスト上で動作する Zabbix エージェント
- ログ監視のアイテムがセットアップされていること
監視されるログファイルのサイズの制限は、大きなファイルをサポートしているかどうかによります。
設定
エージェントの設定ファイルで以下のことを確認してください:
- 「Hostname」パラメータが、Webインターフェースのホスト名と一致していること
- 「ServerActive」パラメータ内のサーバが、アクティブチェックの処理に指定されていること
アイテムの設定
ログ監視のアイテムを設定します:
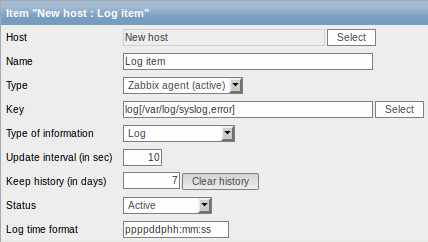
具体的には、ログ監視アイテムには、次のことを入力しなければなりません:
| タイプ ここ | はZabbixエージェント(アクティブ)を選択します |
| キー 次 | どれかを設定します: log[/path/to/file/file_name,<regexp>,<encoding>,<maxlines>,<mode>,<output>] または logrt[/path/to/file/regexp_describing_filename_pattern,<regexp>,<encoding>,<maxlines>,<mode>,<output>] Zabbix エージェントは、ログファイルが存在する場合は、そのエントリを正規表現で検索します。 ファイルが「zabbix」ユーザーに対して読み込み権限を設定していることを確認してください。「zabbix」ユーザーでない場合は、アイテムのステータスが「取得不可」に設定されます。 logとlogrtエントリの詳細については、サポートされているZabbixエージェントのアイテムキーのセクションを参照してください。 |
| データ型 ここで | ログを選択します。 |
| 更新間隔(秒) Zabb | x エージェントがログファイルの変更をチェックする頻度を定義するパラメータです。1秒に設定すると、できるだけ速く新しいレコードを取得することになります。 |
| ログの時間の形式 サポート対象の | レスホルダーは以下のとおりです: * y:// 年 (0001-9999)// * M: 月 (01-12) * d: 日 (01-31) * h: 時 (00-23) * m: 分 (00-59) * s: 秒 (00-59) 空白のままにすると、タイムスタンプは構文解析されません。 例えば、Zabbix エージェントのログファイルから返った次の行の場合 : ” 23480:20100328:154718.045 Zabbix agent started.Zabbix 1.8.2 (revision 11211).” 最初の6桁の文字列はPID、続いて日付、時刻、行の残りとなっています。 この行のログの時間の形式は、「pppppp:yyyyMMdd:hhmmss」となります。 「p」と「:」の文字列は単なるプレスホルダーなので、 「yMdhms」以外の文字が使用できます。 |
重要な注意事項
- サーバとエージェントは、監視するログのサイズとlogrtアイテムの最終更新時間を2種類のカウンタで追跡します。更に、Zabbix 2.2.4以降では:
<!-- --> * エージェントは内部でiノード番号 (UNIX/GNU/Linux)、ファイルインデックス(Microsoft Windows)、ログファイルの最初の512バイトのMD5合計値を基に、ログファイルの切り取りやローテーションを行う際のより良い判断のために使用します。
* UNIX/GNU/Linux システムでは、ログファイルを保存しているファイルシステムがiノード番号をレポートし、これを基にファイルを追跡することを前提としています。
* Microsoft Windows上では、ログファイルが属するファイルシステムのタイプを Zabbixエージェントが決定し、以下の情報を使用します:
* NTFSファイルシステム上では、64ビットのファイルインデックス
* ReFSファイルシステム(Microsft Windowsサーバ2012のみ)上では、128ビットのファイルID
* ファイルインデックスが変化するファイルシステム(例:FAT32、exFAT)上では、ログファイルのローテーションを行なった結果、最終更新時間が同じ複数のログファイルが作成されるような不確定条件下で賢明なアプローチをとることができるよう、縮退アルゴリズムが使用されます。
* iノード番号、ファイルインデックス、MD5合計値は、Zabbix エージェントが内部で収集します。これらは 、Zabbixサーバへは送信されないので、 Zabbix エージェントが停止するとなくなります。
* ログファイルの最終更新時間を「touch」ユーティリティで変更しないでください。また、後続のログファイルをコピーする際、元の名称に戻さないでください(ファイルのiノード番号が変更されます)。両方のケースで、ファイルは異なるものとしてカウントされ、最初から分析されます。この結果、警告が重複して出力されます。
* エージェントがログファイルを読み込む場合、前回の続きから読み始めます。
* エージェントがログファイルを前回の続きから読み始めることができるように、分析済みのバイト数(サイズカウンタ)と最終更新時間(タイムカウンタ)がZabbixデータベースに保存され、エージェントに送信されます。
* エージェントが認識するログサイズカウンタ値よりもログファイルが小さい場合は必ず、カウンタが0にリセットされ、エージェントは、タイムカウンタを考慮して、ログファイルの先頭から読み始めます。
* logrtアイテムにおいて、条件に一致したファイルで最終更新時間が同じものがディレクトリ内に複数存在する場合:
* Zabbix **2.2.4**以前では、エージェントは辞書順で最も値が小さいものを読み込みます。
* Zabbix **2.2.4**以降:
* エージェントは、すべての状況で保証できるとは限らないものの、更新時間が同じログファイルすべてを正しく解析することで、データのスキップや同じデータを2回分析することを避けようとします。
* エージェントは、特定のログファイルローテーションスキームを仮定せず、決定もしません。最終更新時間が同じ複数のログファイルがある場合、エージェントは辞書順(降順)にそれらを処理します。したがって、ログファイルの解析とレポートが元々の順番で行なわれるローテーションスキームもありますが、それ以外のローテーションスキームでは、ログファイルの元々の順番は尊重されず、一致したログファイルレコードが元の順番とは異なる順番でレポートされる可能性があります。(ログファイルごとに最終更新時間が異なれば、障害は発生しません)。
* Zabbixエージェントは、//更新間隔//(秒)ごとに、ログファイルの新しいレコードを1回処理します。
* Zabbixエージェントは、1秒あたりにログファイルの**maxlines**を超えて送信することはありません。この制限によってネットワークやCPUの各リソースが過負荷になることを防ぎ、[[:jp/manual/appendix/config/zabbix_agentd|エージェントの設定ファイル]]の**MaxLinesPerSecond**パラメータでデフォルト値を書き換えます。
* Zabbixは、必要な文字列を見つけるため、MaxLinesPerSecondで設定される量の4倍の新しい行を処理します。例えば、log[]またはlogrt[]アイテムの//更新間隔//が1秒の場合、エージェントがデフォルトで分析できるログファイルレコードは最大400個までであり、1回のチェックでZabbixサーバへ送信できる一致レコードは最大100個までです。エージェント設定ファイル中の**MaxLinesPerSecond**を上げることにより、または、アイテムキー中の**maxlines**パラメータを設定することにより、分析できるログファイルレコードは最大4000個まで、1回のチェックでZabbixサーバへ送信できる一致レコードは最大1000個まで限界を上げることができます。//更新間隔//を2秒に設定した場合、1回のチェックの限界は、//更新間隔//が1秒の場合の2倍に設定されます。
* ログの値は、非ログ値が存在する場合でも、常にエージェント送信バッファサイズの50%に制限されます。そのため、(複数回の接続ではなく)1回の接続で送信される**maxlines**の値として、エージェントの[[jp/manual/appendix/config/zabbix_agentd|BufferSize]]パラメータは、maxlinesの2倍以上の値に設定しなければなりません。
* ログアイテムが存在しない場合は、エージェントのバッファサイズはすべて非ログ値に使用されます。ログ値が生じた場合には、指定されているバッファサイズの50%に達するまで、必要に応じて、古い方の非ログ値からログ値に置き換えられます。
* ログファイルレコードが256kBよりも長い場合、最初の256kBのみが正規表現と照合され、レコードの残りは無視されます。ところが、 Zabbixエージェントが長いレコードを処理中に停止すると、エージェントの内部状態が失われるので、エージェントを再起動後に長いレコードが異なる方法で再び分析されます。この制限は、Zabbix **2.2.3**以降に導入されています。
* 「\」パスの区切り文字に関する特別注意事項:「.」の場合、「.」が抜けているのかファイル名の最初の記号なのかを明確に定義するのは難しいため、file_formatが「file\.log」の場合、「file」というディレクトリが存在してはなりません。
* logrtの正規表現はファイル名でのみサポートされており、ディレクトリの正規表現でのマッチングはサポートされていません。
* UNIXプラットフォーム上では、ログファイルが見つかるはずのディレクトリが存在しない場合、logrt[]アイテムは取得不可となります。
* Microsoft Windows上では、ディレクトリが存在しなくても(例えば、アイテムキー中でディレクトリのスペルが間違っていても)、アイテムは取得不可となりません。Zabbix 2.2.3以前では、そのアイテムは取得不可となりますので注意してください。
* logrt[]アイテムのログファイルが存在しなくても、そのアイテムは取得不可となりません(Zabbix 2.2.3以前では、取得不可の原因となりました)。
* logrt[]アイテムのログファイルの読み込みエラーは、警告としてZabbixエージェントのログファイルへ記録されますが、そのアイテムは取得不可となりません(Zabbix 2.2.3以前では、取得不可の原因となりました)。
* Zabbixエージェントのログファイルは、log[]またはlogrt[]アイテムが取得不可となった理由を見つけるのに役立ちます。DebugLevel=4の場合を除き、Zabbixは、Zabbixエージェントのログファイルを監視できます。正規表現の一致した部分を抽出する
正規表現の一致が見つかった時、行全体を返す代わりに、ターゲットファイルから対象となる値だけを抽出したい場合があります。
以前は、Zabbixが正規表現の一致を発見した場合、一致した部分を含む行全体を返していました。Zabbix 2.2.0以降、ログ監視は該当する行から欲しい値を抽出できるように機能拡張されました。行から欲しい値を抽出するにはlogおよびlogrtアイテムのoutputパラメータを使用します。
outputは、対象となる一致をサブグループとして示すことができます。
例えば、
log[/path/to/the/file,"large result buffer allocation.*Entries: ([0-9]+)",,,,\1]上記は以下のログ中のエントリ数を取得できます:
Fr Feb 07 2014 11:07:36.6690 */ Thread Id 1400 (GLEWF) large result
buffer allocation - /Length:437136/Entries:5948/Client Ver: >=10/RPC
ID:41726453/User:AUser/Form:CFG:ServiceLevelAgreementZabbix が数値のみ返却できるのは正規表現指定でサブグループ([0-9]+)が設定されておりoutputに設定した\1がサブグループの1番目を表しているためです。
数値を抽出し返すことができるので、数値を使用してトリガーを定義することができます。
本ページは2014/08/05時点の原文を基にしておりますので、内容は必ずしも最新のものとは限りません。
最新の情報は、英語版のZabbix2.2マニュアルを参照してください。