
6 ログファイル監視
概要
Zabbixは、ログローテーションサポートの有無にかかわらず、ログファイルの集中監視と分析に利用することができます。
ログファイルに特定の文字列や文字列パターンが含まれる場合、通知機能を使ってユーザに警告することができます。
ログファイルを監視するには、以下の環境が必要です。
- ホスト上でZabbix agent が動作していること
- ログ監視 item の設定
監視するログファイルのサイズ制限は、large file support に依存します。
設定
agent パラメーターの確認
agent configuration fileで以下を確認します。
- 'Hostname' パラメータがフロントエンドのホスト名と一致していること。
- 'ServerActive' パラメータで、アクティブチェックの処理に使用する server が指定されていること。
アイテムの設定
ログ監視のアイテム設定
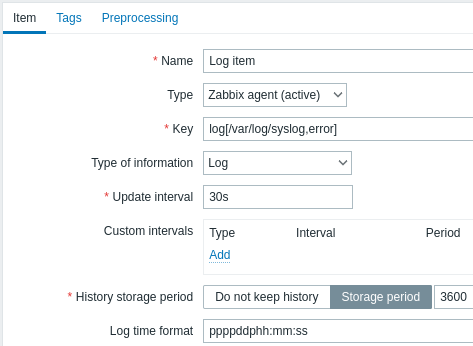
すべての必須入力フィールドには赤いアスタリスクが付いています。
具体的には、ログ監視アイテムに対して次のように入力します。
| タイプ | Zabbix エージェント (アクティブ) を選択 |
| キー | 次の項目キーのいずれかを使用します log[] または logrt[]: これら 2 つのアイテムキーを使用すると、ログを監視し、存在する場合はコンテンツの正規表現によってログエントリをフィルター処理できます。 例: log[/var/log/syslog,error]ファイルに'zabbix'ユーザーの読み取り権限があることを確認してください。そうでない場合、アイテムのステータスは'サポートされていません'に設定されます。log.count[] または logrt.count[]: これら 2 つの項目キーは一致する行の数のみを返すことができます。 これらのアイテム キーとそのパラメーターの使用方法の詳細については、サポートされているZabbix エージェント アイテム キー セクションを参照してください。 |
| データ型 | 自動事前入力: log[] または logrt[] アイテムの場合 - ログlog.count[] または logrt.count[] アイテムの場合 - 数値 (整数).オプションで output パラメータを使用する場合は、Log 以外の適切なタイプの情報を手動で選択できます。非ログ タイプの情報を選択すると、ローカル タイムスタンプが失われることに注意してください。 |
| 監視間隔(秒) | このパラメータは、Zabbix エージェントがログ ファイルの変更をチェックする頻度を定義します。 1 秒に設定するとできるだけ早く新しいレコードを取得できます。 |
| ログの時間の形式 | このフィールドでは、オプションで、ログ行のタイムスタンプを解析するためのパターンを指定できます。 空白のままにすると、タイムスタンプは解析されません。 サポートされているプレースホルダー: * y: 年 (0001 -9999) * M: 月 (01-12) * d: 日 (01-31) * h : 時 (00-23) * m: 分 (00-59) * s: 秒 (00-59)< br>たとえば、Zabbix エージェント ログ ファイルの次の行について考えてみましょう: " 23480:20100328:154718.045 Zabbix agent started. Zabbix 1.8.2 (revision 11211)." PIDの6文字で始まり、その後に日付、時刻、残りの行が続きます。 この行のログ時刻の形式は"pppppp:yyyyMMdd:hhmmss"になります。 "p"と":"の文字は単なるプレースホルダーであり、"yMdhms"以外であれば何でもかまいません。 |
重要な注意事項
- server と agent は、監視対象ログのサイズと最終更新時間(logrtの場合)のトレースを2つのカウンターに保持します。
- また、agent は内部的に inode 番号 (UNIX/GNU/Linux) 、ファイルインデックス(Microsoft Windows上)、 MD5 ログファイルの最初の512バイトの合計を使用しています。ログファイルが切り捨てられたり、 ローテートした場合の判断を改善するためです。
- UNIX/GNU/Linuxシステムでは、ログファイルが保存されているファイルシステムで、 ファイルの追跡のためにinode番号を報告していると仮定します。
- Microsoft Windowsの場合、Zabbix agent はログファイルが存在するファイルシステム の種類を判断して使用します。
- NTFSファイルシステムの場合、64ビットファイルインデックスを使用します。
- ReFSファイルシステムの場合(Microsoft Windows Server 2012から)128ビットのファイルID。
- ファイルインデックスが変更されるファイルシステム(例:FAT32、exFAT)では、ログファイルのローテートにより 同じ最終更新時刻を持つ複数のログファイルが発生する場合、不確実な条件下で賢明なアプローチを取るために フォールバックアルゴリズムが使用されます。
- inode番号、ファイルインデックス、MD5サムはZabbix agent が内部で収集します。 これらはZabbix server に転送されず、Zabbix agent を停止すると失われます。
- ログファイルの最終更新時刻を 'touch' で変更したり、ログファイルをコピーして元の名前に戻したり しないでください(ファイルのinode番号が変更されます)。どちらの場合もファイルが異なるとみなされ、 最初から分析されるため、重複して警告が出されることがあります。
logrt[]item に一致するログファイルが複数あり、Zabbix agent がそのうちの最新のログファイルを 追いかけていて、その最新のログファイルが削除された場合、警告メッセージ"there are no files matching "<regexp mask>" in "<directory>"がログに記録されます。Zabbix agent は、チェック対象のlogrt[]item の agent が見た最新の更新時刻より 短い更新時刻のログファイルを無視します。
- agent は、前回停止した時点からログファイルの読み込みを開始します。
- 解析済みのバイト数(サイズカウンタ)と最終更新時刻(タイムカウンタ)はZabbixデータベースに保存され、 agent が起動したばかりの時や、以前は無効またはサポートされていなかった item を受け取った時に、 agent がこの時点からログファイルを読み始めるようにするために agent に送信されます。ただし、agent が server から0以外の サイズカウンターを受信していても、logrt[] またはlogrt.count[] item が見つからず、一致するファイルがない場合、 サイズカウンターを0にリセットし、後にファイルが現れた場合に最初から解析するようにします。
- ログファイルが agent によって知られているログサイズカウンターより小さくなるたびに、カウンターはゼロにリセットされ、 agent は時間カウンターを考慮して最初からログファイルの読み込みを開始します。
- ディレクトリ内に同じ最終修正時刻を持つ複数のマッチングファイルがある場合、agent は同じ修正時刻を持つすべての ログファイルを正しく分析し、データをスキップしたり同じデータを二度分析することを避けようとしますが、すべての状況で 保証されるわけではありません。agent は、特定のログファイルローテーションスキームを仮定せず、決定もしません。 同じ最終修正時刻を持つ複数のログファイルが提示された場合、agent は辞書的に降順でそれらを処理します。 したがって、いくつかのローテーションスキームでは、ログファイルは元の順序で分析され報告されます。 他のローテーション方式では、元のログファイルの順番は守られず、変更された順番で一致したログファイルのレコードを 報告することになります(ログファイルの最終修正時刻が異なる場合はこの問題は起こりません)。
- Zabbix agentは、ログファイルの新しいレコードをUpdate interval(更新間隔)秒に1回処理します。
- Zabbix agentは1秒間にmaxlines行を超えるログファイルを送信しません。この制限はネットワークとCPUリソースの 過負荷を防ぎ、agent configuration fileのMaxLinesPerSecondパラメータの デフォルト値より優先されます。
- 必要な文字列を見つけるために、ZabbixはMaxLinesPerSecondで設定された10倍以上の新しい行を処理します。
したがって、例えば、
log[]またはlogrt[]item のUpdate interval(更新間隔)が1秒の場合、デフォルトでは agent は 200以上のログファイルレコードを分析せず、1回のチェックで20以上のマッチングレコードをZabbixサーバに送信しません。 エージェント設定ファイルのMaxLinesPerSecondを増やすか、アイテムキーのmaxlinesパラメータを設定することで、 1回のチェックでログファイルの解析レコードを最大10000件、Zabbixサーバに送信するマッチングレコードを最大1000件まで 増やすことが可能です。Update interval(更新間隔)を2秒に設定した場合、1回のチェックの上限は更新間隔*1秒の場合の 2倍となります。 - さらに、ログと log.count の値は、ログ以外の値がない場合でも、常に agent 送信バッファサイズの 50%に制限されます。 したがって、1 つの接続で maxlines 値を送信するには(複数の接続ではなく)、agent の BufferSize パラメータを maxlines x 2 以上にする必要があります。
- ログ item がない場合、すべての agent バッファサイズは非ログ値に使用されます。ログ値が来ると、指定された50%を 上限として、必要に応じて古い非ログ値を置き換えます。
- 256kB以上のログファイルレコードの場合、最初の256kBのみ正規表現と照合され、残りのレコードは無視されます。 ただし、長いレコードを処理中にZabbix agent が停止した場合、agent 内部の状態は失われ、 agent の再起動後に長いレコードを再度解析し、異なる結果を得る可能性があります。
- "//"パスセパレータに関する特別な注意事項 : file_format が "file//.log" の場合、"file" ディレクトリは存在してはならない。 なぜなら、"." がエスケープされているか、ファイル名の最初のシンボルであるかを明確に定義することができないからである。
logrtの正規表現はファイル名のみサポートされ、ディレクトリの正規表現マッチングはサポートされません。- UNIXプラットフォームでは、ログファイルが見つかると期待されるディレクトリが存在しない場合、
logrt[]item はNOTSUPPORTEDになります。 - Microsoft Windowsでは、ディレクトリが存在しない場合、itemはNOTSUPPORTEDになりません。 (例えば、item キーのディレクトリのスペルが間違っている場合など)
logrt[]item のログファイルがない場合でも、NOTSUPPORTEDになるわけではありません。logrt[]item の ログファイル読み込みのエラーは、Zabbix agent ログファイルに警告として記録されますが、そのアイテムが NOTSUPPORTEDになることはありません。- Zabbix agent ログファイルは、
log[]またはlogrt[]アイテムがNOTSUPPORTEDになった理由を見つけるために役立ちます。 ZabbixはDebugLevel=4以外の場合、agent ログファイルを監視することができます。
正規表現のマッチング部分を抽出する
正規表現にマッチしたときに、行全体を返すのではなく、ターゲットファイルから目的の値だけを取り出したい場合があります。
Zabbix 2.2.0以降、ログアイテムはマッチした行から目的の値を抽出することができます。
これは、logとlogrtitem に追加されたoutputパラメータによって実現されています。
'output' パラメータを使用すると、マッチした行のうち、興味のある "capturing group" を指定することができます。
そのため、例えば
log[/path/to/the/file,"large result buffer allocation.*Entries: ([0-9]+)",,,,\1] で以下のログ内容から、エントリ数(Entries: の数値)を返すことができるはずです。
Fr Feb 07 2014 11:07:36.6690 */ Thread Id 1400 (GLEWF) large result
buffer allocation - /Length: 437136/Entries: 5948/Client Ver: >=10/RPC
ID: 41726453/User: AUser/Form: CFG:ServiceLevelAgreement\1 は最初のキャプチャグループのため、番号のみが返されます。([0-9]+)
また、数値を抽出して返す機能により、その値を使ってトリガーを定義することも可能です。
maxdelay パラメータの使用
ログ項目の'maxdelay'パラメーターを使用すると、ログ ファイルから古い行を無視して、'maxdelay'秒以内に分析された最新の行を取得できます。
maxdelay' > 0を指定すると、重要なログファイルの記録が無視されたり、警告が見逃されたりすることがあります。必要なときだけ、自己責任で慎重に使用してください。
デフォルトでは、ログ監視のための項目は、ログファイルに現れるすべての新しい行に従います。しかし、ある状況下でログファイルに膨大な数のメッセージを書き始めるアプリケーションがあります。例えば、データベースやDNSサーバーが利用できない場合、そのようなアプリケーションは、正常な動作が回復するまで、ほぼ同じエラーメッセージを何千もログファイルに書き出します。デフォルトでは、これらのメッセージはすべて忠実に解析され、 log と logrt の項目で設定されたとおりにマッチする行がサーバに送信されます。
過負荷に対する組み込みの保護は、構成可能な'maxlines'パラメーター (一致するログ行が多すぎる受信からサーバーを保護する) と 10*'maxlines'制限 (1 回のチェックでエージェントによる過負荷からホスト CPU と I/O を保護する) で構成されます。 それでも、組み込みの保護機能には 2 つの問題があります。まず、あまり有益ではない可能性のある多数のメッセージがサーバーに報告され、データベース内のスペースが消費されます。 第 2 に、1 秒あたりに分析される行数が限られているため、エージェントは最新のログ レコードから数時間遅れる可能性があります。 多くの場合、古いレコードを何時間もクロールするよりも、ログ ファイルの現在の状況についてすぐに知りたいと思うかもしれません。
両方の問題の解決策は、'maxdelay' パラメーターを使用することです。 'maxdelay' > 0 が指定されている場合、各チェック中に、処理されたバイト数、残りのバイト数、および処理時間が測定されます。 これらの数値から、エージェントは推定遅延 (ログ ファイル内の残りのすべてのレコードを分析するのにかかる秒数) を計算します。
遅延が'maxdelay'を超えない場合、エージェントは通常どおりログ ファイルの分析を続行します。
遅延が'maxdelay'よりも大きい場合、エージェントは'maxdelay'秒以内に残りの行を分析できるように、ログ ファイルのチャンクを無視して新しい推定位置に"ジャンプ"します。
エージェントは無視された行をバッファに読み込むことさえせず、ファイル内のジャンプ先のおおよその位置を計算することに注意してください。
ログ ファイルの行をスキップしたという事実は、次のようにエージェント ログ ファイルに記録されます。
14287:20160602:174344.206 item:"logrt["/home/zabbix32/test[0-9].log",ERROR,,1000,,,120.0]" logfile:"/home/zabbix32/test1.log" skipping 679858 bytes (from byte 75653115 to byte 76332973) to meet maxdelay"ジャンプ"の後、エージェントはファイル内の位置をログ行の先頭に調整するため、"バイトまで"の数値は概算です。
成長速度とログ ファイルの分析速度を比較する方法によっては、すべてのチェックで "ジャンプ" が見られない場合、ほとんどまたは頻繁に "ジャンプ" が見られる場合、大きなまたは小さな "ジャンプ" が見られる場合、または小さな "ジャンプ" が見られる場合さえあります。 システム負荷とネットワーク遅延の変動も遅延の計算に影響を与えるため、"maxdelay"パラメータに追いつくために先に"ジャンプ"します。
'maxdelay' < 'update interval' を設定することはお勧めしません (小さな"ジャンプ"が頻繁に発生する可能性があります)
'copytruncate' ログファイルローテーションの取り扱いに関する注意点
logrt の copytruncate オプションは、異なるログファイルには異なる記録がある (少なくともタイムスタンプは異なる) と
仮定しています。したがって、初期ブロック (最初の512バイトまで) のMD5チェックサムは異なることになります。
初期ブロックの MD5 チェックサムが同じである 2 つのファイルは、一方がオリジナルで、もう一方がコピーであることを意味します。
logrt の copytruncate オプションは、ログファイルのコピーを重複して報告することなく、正しく処理するように努力します。
しかし、同じタイムスタンプのログファイルを複数作成したり、ログファイルのローテーションがlogrt[] item のupdate interval より
頻繁になったり、agent を頻繁に再起動することは推奨されません。agent は、これらの状況を合理的に処理しようとしますが、
すべての状況でよい結果を保証することはできません。
log*[] itemのpersistent filesに関する注意事項
永続化ファイルの目的
Zabbix agent の起動時に、Zabbix server または proxy からアクティブチェックのリストを受け取ります。
log*[] メトリクスでは、ログファイルの監視を開始する場所を見つけるために、処理されたログのサイズと変更時間を受け取ります。
ファイルシステムから報告された実際のログファイルサイズと変更時間に応じて、agent は処理されたログサイズから
ログファイル監視を継続するか、ログファイルを最初から再分析するかを決定します。
実行中の agent は、チェックの間に監視されたすべてのログファイルを追跡するために、
より大きな属性のセットを維持します。 このインメモリの状態は、エージェントが停止されると失われます。
新しいオプションパラメータ persistent_dir は、この log[]、log.count[]、logrt[]または logrt.count[] item の状態を
ファイルに格納するディレクトリを指定するものです。Zabbix agent を再起動すると、ログアイテムの状態は永続化ファイルから復元されます。
主な用途は、ミラーリングされたファイルシステム上にあるログファイルの監視です。ある時点まで、ログファイルは
両方のミラーに書き込まれます。その後、ミラーは分割されます。 アクティブなコピーでは、ログファイルは新しいレコードを
取得し、まだ成長しています。Zabbix agent はこれを解析し、処理されたログのサイズと更新時刻を server に送信します。
パッシブコピーでは、ログファイルは同じまま、アクティブコピーよりかなり遅れています。その後、OSとZabbixエージェントが
パッシブコピーからリブートされます。Zabbix agent が server から受け取った処理済みのログサイズと更新時刻は、
パッシブコピー上の状況に対して有効でない場合があります。 ファイルシステムのミラースプリット時に agent が停止した場所から
ログファイルの監視を継続するために、agent は永続ファイルから状態をリストアします。
永続ファイルを使用した agent 操作
起動時、Zabbix agent は永続化ファイルについて何も知りません。Zabbixサーバからアクティブチェックのリストを受け取った後、
agent はいくつかのログアイテムが指定されたディレクトリの永続ファイルでバックアップされることを認識します。
agent 操作の間、永続ファイルは書き込みのために開かれ (fopen(filename, "w")) 、最新のデータで上書きされます。
上書きとファイルシステムのミラーリングが同時に起こった場合、永続ファイルのデータが失われる可能性は非常に低いので、
特別な処理は行いません。 永続ファイルへの書き込みの後にメディアへの強制同期を行わない(fsync() is not called)は呼び出されない)ため、
永続ファイルへの書き込みの後にメディアへの強制同期を行うことはできません。
最新データの上書きは、一致するログファイルのレコードまたはメタデータ(処理されたログのサイズと更新時間)が Zabbix server に正常に報告された後に行われます。ログファイルが変化し続ける場合、item チェックのたびに行われる可能性があります。
agent シャットダウン中の特別な動作はありません。
アクティブなチェックのリストを受け取った後、agent は廃止された永続ファイルを削除するようマークします。
以下の場合、永続ファイルは廃止されます。
1) 対応するログ項目が監視されなくなった、
2) ログ項目が以前と異なる persistent_dir 位置で再設定された。
NOTSUPPORTED状態のログファイルはアクティブチェックのリストに含まれませんが、後にSUPPORTEDになる可能性があり、
その永続ファイルが有用であるため、24時間遅れで削除されます。
24時間経過前に agent を停止した場合、Zabbix agent はZabbix server からファイルの所在情報を取得しなくなるため、
古くなったファイルは削除されません。
agent が停止している間に、ユーザが古い永続ファイルを削除せずに、ログアイテムの persistent_dir を 古い persistent_dir の場所に再構成すると、古い永続ファイルからエージェント状態をリストアすることになり、 メッセージの見逃しや誤った警告が発生します。
永続ファイルの命名と場所
Zabbix agent は、アクティブなチェックをキーで区別します。例えば、 logrt[/home/zabbix/test.log] と
logrt[/home/zabbix/test.log,] は異なるアイテムです。 フロントエンドの item logrt[/home/zabbix/test.log,,,10] を
logrt[/home/zabbix/test.log,,,20] に変更すると、item logrt[/home/zabbix/test.log,,,10] が削除されます。
logrt[/home/zabbix/test.log,,10] を agent のアクティブチェックリストから削除し、logrt[/home/zabbix/test.log,,20] item を作成します。
(いくつかの属性は、agent ではなくフロントエンド/サーバで変更されます)
ファイル名は、item キーの MD5 チェックサムと、衝突の可能性を低減するために item キーの長さを付加したものです。
例えば、 logrt[/home/zabbix50/test.log,,,,,,/home/zabbix50/agent_private] item の状態は、
永続ファイル c963ade4008054813bbc0a650bb8e09266 に保存されます。
persistent_dir は、複数のログ item で同じ値を使用できます。
persistent_dir は、特定のファイルシステムのレイアウト、マウントポイント、マウントオプション、ストレージのミラーリング設定を
考慮して指定されます。
persistent_dir ディレクトリが作成できないか存在しないか、Zabbix agent のアクセス権でファイルの作成/書き込み/読み取り/削除が
できない場合、ログ item はNOTSUPPORTEDになります。
agent 操作中に永続的ストレージファイルへのアクセス権が削除されたり、他のエラー(例:ディスクフル)が発生した場合、 エラーは agent ログファイルに記録されますが、ログ item がNOTSUPPORTEDになることはありません。
I/Oの負荷
Item の永続化ファイル は、item のデータを含むデータを server に送信するたびに更新されます。 例えば、デフォルトの'BufferSize'は100です。
ログアイテムが70件のマッチングレコードを発見した場合、最初の50件のレコードを一括して送信し、永続化ファイルを更新した後、
残りの20レコードが2回目のバッチで送信され、永続化ファイルが再び更新されます。
agent と server 間の通信に失敗した場合の対処法
log[]とlogrt[]item からマッチする各行と、各log.count[]とlogrt.count[]` item チェックの結果は、
agent 送信バッファ内の指定された50%エリアに空きスロットを必要とします。バッファの要素は定期的に server (または proxy)に送信され、
バッファのスロットは再び空きます。
agent 送信バッファの指定ログ領域に空き枠があり、agent と server (または proxy)間の通信に失敗した場合、
ログ監視結果が送信バッファに蓄積されます。これにより、短時間の通信障害を緩和することができます。
長時間の通信障害時には、すべてのログスロットが占有され、次のような動作が行われます。
- log[]
とlogrt[]` の item チェックは停止しています。通信が復旧し、バッファの空きスロットができると、 チェックは前の位置から再開されます。マッチする行は失われず、後で報告されるだけです。 - maxdelay = 0
(デフォルト) の場合、log.count[]とlogrt.count[]のチェックが停止します。動作は上記のlog[]とlogrt[]の項目と同様です。これはlog.count[]とlogrt.count[]` の結果に影響を与えることに注意してください。 例えば、あるチェックでログファイルの100行にマッチしましたが、バッファに空きスロットがないため、チェックは停止されました。 通信が回復したとき、agent は同じ100のマッチする行と、70の新しいマッチする行を数えます。 agent は、あたかも一度のチェックで見つかったかのように、count = 170 を送信します。 maxdelay > 0のlog.count[]とlogrt.count[]のチェック: チェック中に "jump" がなければ、上記の動作と同じになります。 もし、ログファイルの行を "jump" した場合は、 "jump" 後の位置を保持し、カウントした結果は破棄されます。 したがって、agent は、通信障害が発生しても、ログファイルの増加についていこうとします。
正規表現のコンパイルおよび実行時エラーの処理
log[]、logrt[]、log.count[]、または logrt.count[] アイテムで使用されている正規表現が PCRE または PCRE2 ライブラリでコンパイルできない場合、アイテムは NOTSUPPORTED 状態になり、エラーメッセージが表示されます。ログアイテムの監視を継続するには、正規表現を修正する必要があります。
正規表現のコンパイルは成功したものの、実行時に(一部またはすべてのログレコードで)失敗した場合、ログアイテムは引き続きサポートされ、監視は継続されます。実行時エラーは Zabbix エージェントのログファイルに記録されます(ログファイルレコードは記録されません)。
正規表現の実行時エラーのログ記録は、Zabbix 6.0.21 以降でサポートされています。
Zabbix エージェントが独自のログファイルを監視できるように、ログ記録レートはチェックごとに 1 つの実行時エラーに制限されています。例えば、10 件のレコードを分析し、そのうち 3 件のレコードが正規表現の実行時エラーで失敗した場合、エージェントログには 1 つのレコードが生成されます。
例外: MaxLinesPerSecond=1 かつ update interval=1(1回のチェックで1レコードのみ分析可能)の場合、正規表現によるランタイムエラーはログに記録されません。
zabbix_agentd はランタイムエラー発生時にアイテムキーをログに記録し、zabbix_agent2 はどのログアイテムにランタイムエラーが発生したかを特定するためにアイテムIDをログに記録します。ランタイムエラー発生時の正規表現を再設計することをお勧めします。