
10 Reguläre Ausdrücke
Übersicht
Perl Compatible Regular Expressions (PCRE, PCRE2) werden in Zabbix unterstützt.
Es gibt zwei Möglichkeiten, reguläre Ausdrücke in Zabbix zu verwenden:
- manuelle Eingabe eines regulären Ausdrucks
- Verwendung eines globalen regulären Ausdrucks, der in Zabbix erstellt wurde
Reguläre Ausdrücke
Sie können an unterstützten Stellen manuell einen regulären Ausdruck eingeben. Beachten Sie, dass der Ausdruck nicht mit @ beginnen darf, da dieses Symbol in Zabbix für Verweise auf globale reguläre Ausdrücke verwendet wird.
Bei der Verwendung regulärer Ausdrücke kann der Stack-Speicher erschöpft werden. Weitere Informationen finden Sie unter PCRE PERFORMANCE.
Beachten Sie, dass bei der mehrzeiligen Übereinstimmung die Anker ^ und $ jeweils mit dem Anfang bzw. Ende jeder Zeile übereinstimmen, statt mit dem Anfang bzw. Ende des gesamten Strings.
Siehe auch Beispiele für korrektes Escaping in verschiedenen Kontexten.
Globale reguläre Ausdrücke
Im Zabbix-Frontend gibt es einen erweiterten Editor zum Erstellen und Testen komplexer regulärer Ausdrücke.
Sobald ein regulärer Ausdruck auf diese Weise erstellt wurde, kann er an mehreren Stellen im Frontend verwendet werden, indem auf seinen Namen mit vorangestelltem @ verwiesen wird, zum Beispiel \@mycustomregexp.
Um einen globalen regulären Ausdruck zu erstellen:
- Gehen Sie zu: Administration > General
- Wählen Sie Regular expressions aus der Dropdown-Liste
- Klicken Sie auf New regular expression
Auf der Registerkarte Expressions können Sie den Namen des regulären Ausdrucks festlegen und Teilausdrücke hinzufügen.
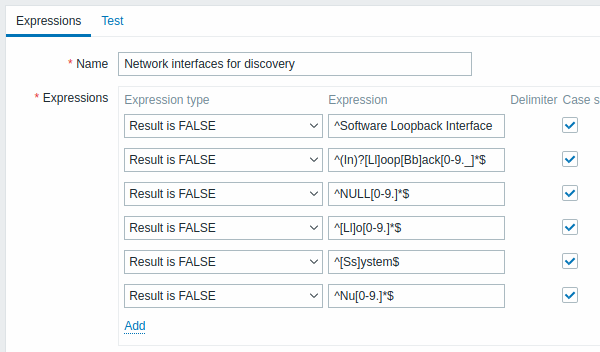
Alle Pflichtfelder sind mit einem roten Sternchen markiert.
| Parameter | Beschreibung | |
|---|---|---|
| Name | Legen Sie den Namen des regulären Ausdrucks fest. Alle Unicode-Zeichen sind zulässig. | |
| Expressions | Klicken Sie im Block Expressions auf Add, um einen neuen Teilausdruck hinzuzufügen. | |
| Expression type | Wählen Sie den Ausdruckstyp aus: Character string included - Teilzeichenfolge abgleichen Any character string included - beliebige Teilzeichenfolge aus einer durch Trennzeichen getrennten Liste abgleichen. Die Liste mit Trennzeichen enthält ein Komma (,), einen Punkt (.) oder einen Schrägstrich (/). Character string not included - jede Zeichenfolge außer der Teilzeichenfolge abgleichen Result is TRUE - den regulären Ausdruck abgleichen Result is FALSE - den regulären Ausdruck nicht abgleichen |
|
| Expression | Geben Sie Teilzeichenfolge/regulären Ausdruck ein. | |
| Delimiter | Ein Komma (,), ein Punkt (.) oder ein Schrägstrich (/) zum Trennen von Textzeichenfolgen in einem regulären Ausdruck. Dieser Parameter ist nur aktiv, wenn der Ausdruckstyp "Any character string included" ausgewählt ist. | |
| Case sensitive | Ein Kontrollkästchen, mit dem festgelegt wird, ob bei einem regulären Ausdruck zwischen Groß- und Kleinschreibung unterschieden wird. | |
Ein Schrägstrich (/) im Ausdruck wird wörtlich behandelt und nicht als Trennzeichen. Auf diese Weise können Ausdrücke, die einen Schrägstrich enthalten, ohne Fehler gespeichert werden.
Ein benutzerdefinierter Name für einen regulären Ausdruck in Zabbix kann Kommas, Leerzeichen usw. enthalten.
In Fällen, in denen dies bei der Referenzierung zu Fehlinterpretationen führen kann (zum Beispiel ein Komma im Parameter eines item-Schlüssels), kann die gesamte Referenz in Anführungszeichen gesetzt werden, etwa so: "\@My custom regexp for purpose1, purpose2".
An anderen Stellen dürfen reguläre Ausdrucksnamen nicht in Anführungszeichen gesetzt werden (zum Beispiel in den Eigenschaften einer LLD-Regel).
Auf der Registerkarte Test können der reguläre Ausdruck und seine Teilausdrücke durch Angabe einer Testzeichenfolge getestet werden.
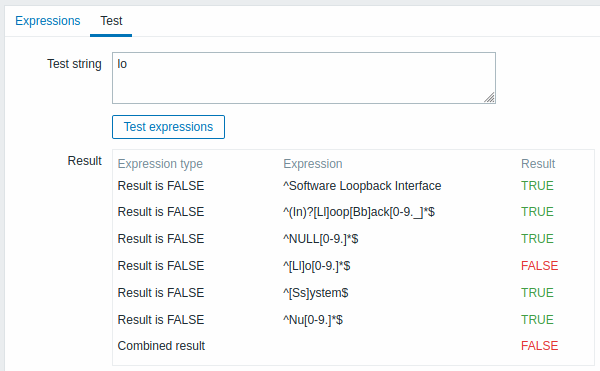
Die Ergebnisse zeigen den Status jedes Teilausdrucks sowie den Gesamtstatus des benutzerdefinierten Ausdrucks.
Der Gesamtstatus des benutzerdefinierten Ausdrucks wird als Combined result definiert. Wenn mehrere Teilausdrücke definiert sind, verwendet Zabbix den logischen UND-Operator, um Combined result zu berechnen. Das bedeutet, dass Combined result ebenfalls den Status False hat, wenn mindestens ein Result False ist.
Standardmäßige globale reguläre Ausdrücke
Zabbix wird mit mehreren globalen regulären Ausdrücken in seinem Standarddatensatz geliefert.
| Name | Expression | Matches |
|---|---|---|
| Dateisysteme für die Erkennung | ^(btrfs|ext2|ext3|ext4|jfs|reiser|xfs|ffs|ufs|jfs|jfs2|vxfs|hfs|refs|apfs|ntfs|fat32|zfs)$ |
"btrfs" oder "ext2" oder "ext3" oder "ext4" oder "jfs" oder "reiser" oder "xfs" oder "ffs" oder "ufs" oder "jfs" oder "jfs2" oder "vxfs" oder "hfs" oder "refs" oder "apfs" oder "ntfs" oder "fat32" oder "zfs" |
| Netzwerkschnittstellen für die Erkennung | ^Software Loopback Interface |
Zeichenfolgen, die mit "Software Loopback Interface" beginnen. |
^lo$ |
"lo" | |
^(In)?[Ll]oop[Bb]ack[0-9._]*$ |
Zeichenfolgen, die optional mit "In" beginnen, dann "L" oder "l" enthalten, dann "oop", dann "B" oder "b", dann "ack", gefolgt von beliebig vielen Ziffern, Punkten oder Unterstrichen. | |
^NULL[0-9.]*$ |
Zeichenfolgen, die mit "NULL" beginnen und optional von beliebig vielen Ziffern oder Punkten gefolgt werden. | |
^[Ll]o[0-9.]*$ |
Zeichenfolgen, die mit "Lo" oder "lo" beginnen und optional von beliebig vielen Ziffern oder Punkten gefolgt werden. | |
^[Ss]ystem$ |
"System" oder "system" | |
^Nu[0-9.]*$ |
Zeichenfolgen, die mit "Nu" beginnen und optional von beliebig vielen Ziffern oder Punkten gefolgt werden. | |
| Speichergeräte für die SNMP-Erkennung | ^(Physical memory|Virtual memory|Memory buffers|Cached memory|Swap space)$ |
"Physical memory" oder "Virtual memory" oder "Memory buffers" oder "Cached memory" oder "Swap space" |
| Windows-Dienstnamen für die Erkennung | ^(MMCSS|gupdate|SysmonLog|clr_optimization_v2.0.50727_32|clr_optimization_v4.0.30319_32)$ |
"MMCSS" oder "gupdate" oder "SysmonLog" oder Zeichenfolgen wie "clr_optimization_v2.0.50727_32" und "clr_optimization_v4.0.30319_32", wobei Sie anstelle der Punkte beliebige Zeichen außer einem Zeilenumbruch verwenden können. |
| Windows-Dienststartzustände für die Erkennung | ^(automatic|automatic delayed)$ |
"automatic" oder "automatic delayed" |
Beispiele
Beispiel 1
Verwendung des folgenden Ausdrucks in der Low-Level-Discovery, um Datenbanken zu entdecken, außer einer Datenbank mit einem bestimmten Namen:
^TESTDATABASE$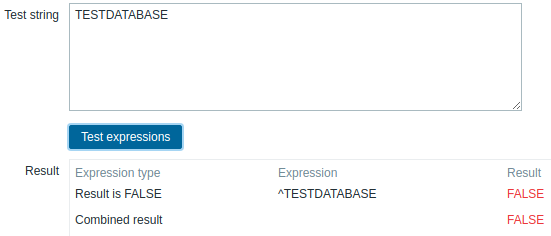
Gewählter Ausdruckstyp: "Result is FALSE". Entspricht nicht dem Namen, der die Zeichenfolge "TESTDATABASE" enthält.
Beispiel mit einem Inline-Regex-Modifikator
Verwendung des folgenden regulären Ausdrucks einschließlich eines Inline-Modifikators (?i), um die Zeichen "error" abzugleichen:
(?i)error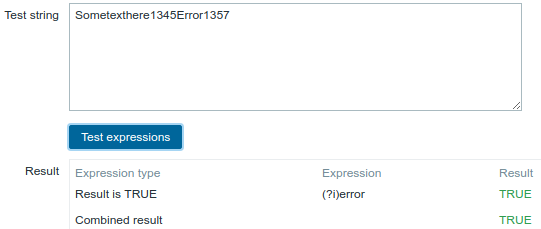
Gewählter Ausdruckstyp: "Result is TRUE". Die Zeichen "error" werden abgeglichen.
Ein weiteres Beispiel mit einem Inline-Regex-Modifikator
Verwendung des folgenden regulären Ausdrucks einschließlich mehrerer Inline-Modifikatoren, um die Zeichen nach einer bestimmten Zeile abzugleichen:
(?<=match (?i)everything(?-i) after this line\n)(?sx).*# we add s modifier to allow . match newline characters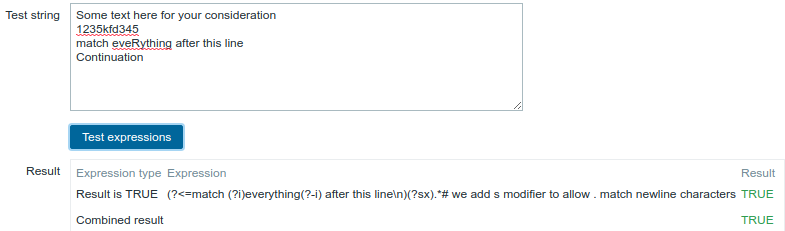
Gewählter Ausdruckstyp: "Result is TRUE". Zeichen nach einer bestimmten Zeile werden abgeglichen.
Der Modifikator g kann nicht in der Zeile angegeben werden. Die Liste der verfügbaren Modifikatoren finden Sie auf der pcresyntax man page. Weitere Informationen zur PCRE-Syntax finden Sie in der PCRE HTML documentation.
Unterstützung regulärer Ausdrücke nach Ort
| Ort | Regulärer Ausdruck | Globaler regulärer Ausdruck | Mehrzeilenabgleich | Kommentare | |
|---|---|---|---|---|---|
| Agent-Datenpunkte | |||||
| eventlog[] | Ja | Ja | Ja | Parameter regexp, severity, source, eventid |
|
| eventlog.count[] | Parameter regexp, severity, source, eventid |
||||
| log[] | Parameter regexp |
||||
| log.count[] | |||||
| logrt[] | Ja/Nein | Parameter regexp unterstützt beides, Parameter file_regexp unterstützt nur nicht-globale Ausdrücke |
|||
| logrt.count[] | |||||
| proc.cpu.util[] | Nein | Nein | Parameter cmdline |
||
| proc.get[] | |||||
| proc.mem[] | |||||
| proc.num[] | |||||
| sensor[] | Parameter device und sensor unter Linux 2.4 |
||||
| system.hw.macaddr[] | Parameter interface |
||||
| system.sw.packages[] | Parameter regexp |
||||
| system.sw.packages.get[] | Parameter regexp |
||||
| vfs.dir.count[] | Parameter regex_incl, regex_excl, regex_excl_dir |
||||
| vfs.dir.get[] | Parameter regex_incl, regex_excl, regex_excl_dir |
||||
| vfs.dir.size[] | Parameter regex_incl, regex_excl, regex_excl_dir |
||||
| vfs.file.regexp[] | Ja | Parameter regexp |
|||
| vfs.file.regmatch[] | |||||
| web.page.regexp[] | |||||
| SNMP-Traps | |||||
| snmptrap[] | Ja | Ja | Nein | Parameter regexp |
|
| Vorverarbeitung von Datenpunktwerten | Ja | Nein | Nein | Parameter pattern |
|
| Funktionen für Auslöser/berechnete Datenpunkte | |||||
| count() | Ja | Ja | Ja | Parameter pattern, wenn der Parameter operator regexp oder iregexp ist |
|
| countunique() | Ja | Ja | |||
| find() | Ja | Ja | |||
| logeventid() | Ja | Ja | Nein | Parameter pattern |
|
| logsource() | |||||
| Low-Level-Discovery | |||||
| Filter | Ja | Ja | Nein | Feld Regulärer Ausdruck | |
| Überschreibungen | Ja | Nein | In den Optionen entspricht und entspricht nicht für Operations-Bedingungen | ||
| Aktionsbedingungen | Ja | Nein | Nein | In den Optionen entspricht und entspricht nicht für die Autoregistrierungsbedingungen Host-Name und Host-Metadaten | |
| Skripte | Ja | Ja | Nein | Feld Eingabevalidierungsregel | |
| Web-Überwachung | Ja | Nein | Ja | Variablen mit dem Präfix regex: Feld Erforderliche Zeichenfolge |
|
| Benutzermakrokontext | Ja | Nein | Nein | Im Makrokontext mit dem Präfix regex: | |
| Makrofunktionen | |||||
| regsub() | Ja | Nein | Nein | Parameter pattern |
|
| iregsub() | |||||
| Link-Indikatoren in Karten | Ja | Nein | Nein | Feld Muster (für Text-Datenpunkte) | |
| Symbolzuordnung | Ja | Ja | Nein | Feld Ausdruck | |
| Wertzuordnung | Ja | Nein | Nein | Feld Wert, wenn der Zuordnungstyp regexp ist |
|