
Vorverarbeitungsdetails
Übersicht
Dieser Abschnitt enthält Details zur Vorverarbeitung von Datenpunktwerten. Die Vorverarbeitung von Datenpunktwerten ermöglicht es, Transformationsregeln für die empfangenen Datenpunktwerte zu definieren und auszuführen.
Die Vorverarbeitung wird vom Prozess „preprocessing manager“ zusammen mit den „preprocessing workers“ verwaltet, die die Vorverarbeitungsschritte ausführen. Alle Werte mit Vorverarbeitung, die von verschiedenen Datensammlern empfangen werden, durchlaufen den preprocessing manager, bevor sie dem Verlaufscache hinzugefügt werden. Für die IPC-Kommunikation auf Socket-Basis zwischen Datensammlern (Pollern, Trappern usw.) und dem Vorverarbeitungsprozess wird Socket-basierte IPC-Kommunikation verwendet. Entweder der Zabbix Server oder der Zabbix Proxy (für die vom Proxy überwachten Datenpunkte) führt die Vorverarbeitungsschritte aus.
Verarbeitung von Datenpunktwerten
Um den Datenfluss von der Datenquelle zur Zabbix-Datenbank zu visualisieren, können wir das folgende vereinfachte Diagramm verwenden:
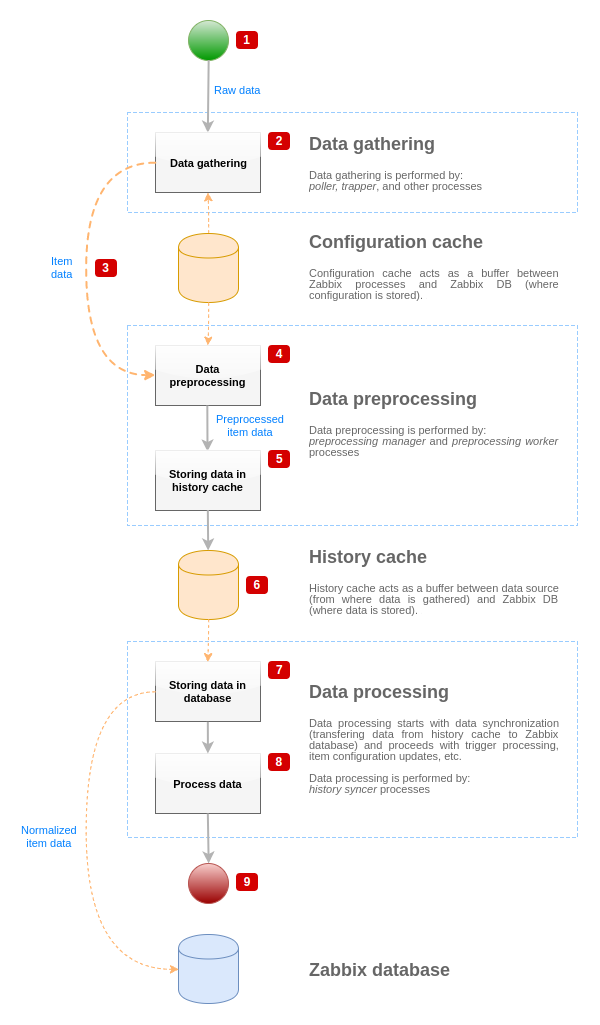
Das obige Diagramm zeigt nur Prozesse, Objekte und Aktionen im Zusammenhang mit der Verarbeitung von Datenpunktwerten in vereinfachter Form. Das Diagramm zeigt weder bedingte Richtungsänderungen noch Fehlerbehandlung oder Schleifen. Der lokale Daten-Cache des Präprozessierungsmanagers wird ebenfalls nicht gezeigt, da er den Datenfluss nicht direkt beeinflusst. Ziel dieses Diagramms ist es, die an der Verarbeitung von Datenpunktwerten beteiligten Prozesse und ihre Interaktion darzustellen.
- Die Datenerfassung beginnt mit Rohdaten aus einer Datenquelle. Zu diesem Zeitpunkt enthalten die Daten nur ID, Zeitstempel und Wert (es können auch mehrere Werte sein).
- Unabhängig davon, welcher Typ von Datensammler verwendet wird, ist die Grundidee bei aktiven oder passiven Prüfungen, bei Trapper-Datenpunkten usw. dieselbe, da sich nur das Datenformat und der Kommunikationsinitiator ändern (entweder wartet der Datensammler auf eine Verbindung und Daten, oder der Datensammler initiiert die Kommunikation und fordert die Daten an). Die Rohdaten werden validiert, die Datenpunktkonfiguration wird aus dem Konfigurations-Cache abgerufen (die Daten werden mit den Konfigurationsdaten angereichert).
- Ein socket-basierter IPC-Mechanismus wird verwendet, um Daten von Datensammlern an den Präprozessierungsmanager zu übergeben. An diesem Punkt setzt der Datensammler die Datenerfassung fort, ohne auf die Antwort des Präprozessierungsmanagers zu warten.
- Die Datenpräprozessierung wird durchgeführt. Dazu gehören die Ausführung von Präprozessierungsschritten und die Verarbeitung abhängiger Datenpunkte.
Ein Datenpunkt kann während der Präprozessierung in den Zustand NOT SUPPORTED wechseln, wenn einer der Präprozessierungsschritte fehlschlägt.
- Die Verlaufsdaten aus dem lokalen Daten-Cache des Präprozessierungsmanagers werden in den Verlaufs-Cache geschrieben.
- An diesem Punkt stoppt der Datenfluss bis zur nächsten Synchronisierung des Verlaufs-Caches (wenn der History-Syncer-Prozess die Datensynchronisierung durchführt).
- Der Synchronisierungsprozess beginnt mit der Datennormalisierung, bevor die Daten in der Zabbix-Datenbank gespeichert werden. Die Datennormalisierung führt Konvertierungen in den gewünschten Datenpunkttyp durch (Typ wie in der Datenpunktkonfiguration definiert), einschließlich der Kürzung von Textdaten auf Basis der vordefinierten Größen, die für diese Typen zulässig sind (HISTORY_STR_VALUE_LEN für string, HISTORY_TEXT_VALUE_LEN für text und HISTORY_LOG_VALUE_LEN für log-Werte). Nach Abschluss der Normalisierung werden die Daten an die Zabbix-Datenbank gesendet.
Ein Datenpunkt kann in den Zustand NOT SUPPORTED wechseln, wenn die Datennormalisierung fehlschlägt (zum Beispiel wenn ein Textwert nicht in eine Zahl konvertiert werden kann).
- Die erfassten Daten werden verarbeitet – Auslöser werden geprüft, die Datenpunktkonfiguration wird aktualisiert, wenn der Datenpunkt NOT SUPPORTED wird, usw.
- Dies gilt aus Sicht der Verarbeitung von Datenpunktwerten als Ende des Datenflusses.
Vorverarbeitung von Datenpunktwerten
Die Datenvorverarbeitung erfolgt in den folgenden Schritten:
- Wenn der Datenpunkt weder Vorverarbeitung noch abhängige Datenpunkte hat, wird sein Wert entweder zum Verlaufscache hinzugefügt oder an den LLD-Manager gesendet. Andernfalls wird der Datenpunktwert über einen UNIX-Socket-basierten IPC-Mechanismus an den Vorverarbeitungs-Manager übergeben.
- Eine Vorverarbeitungsaufgabe wird erstellt, zur Warteschlange hinzugefügt und die Vorverarbeitungs-Worker werden über die neue Aufgabe benachrichtigt.
- An diesem Punkt stoppt der Datenfluss, bis mindestens ein nicht belegter (d. h. aktuell keine Aufgaben ausführender) Vorverarbeitungs-Worker verfügbar ist.
- Wenn ein Vorverarbeitungs-Worker verfügbar ist, nimmt er die nächste Aufgabe aus der Warteschlange.
- Nach Abschluss der Vorverarbeitung (sowohl bei fehlgeschlagener als auch bei erfolgreicher Ausführung der Vorverarbeitungsschritte) wird der vorverarbeitete Wert zur Warteschlange der abgeschlossenen Aufgaben hinzugefügt und der Manager über eine neue abgeschlossene Aufgabe benachrichtigt.
- Der Vorverarbeitungs-Manager konvertiert das Ergebnis in das gewünschte Format (definiert durch den Typ des Datenpunktwerts) und fügt es entweder zum Verlaufscache hinzu oder sendet es an den LLD-Manager.
- Wenn es abhängige Datenpunkte für den verarbeiteten Datenpunkt gibt, werden die abhängigen Datenpunkte mit dem vorverarbeiteten Wert des Master-Datenpunkts zur Vorverarbeitungswarteschlange hinzugefügt. Abhängige Datenpunkte werden unter Umgehung der normalen Anfragen zur Wertvorverarbeitung in die Warteschlange eingereiht, jedoch nur für Master-Datenpunkte mit gesetztem Wert und nicht im Status NICHT UNTERSTÜTZT.

Beachten Sie, dass im Diagramm die Vorverarbeitung des Master-Datenpunkts leicht vereinfacht dargestellt ist, da das Caching der Vorverarbeitung ausgelassen wurde.
Vorverarbeitungswarteschlange
Die Vorverarbeitungswarteschlange ist wie folgt organisiert:
-
die Liste der ausstehenden Aufgaben:
- Aufgaben, die direkt aus Anfragen zur Wertvorverarbeitung in der Reihenfolge erstellt wurden, in der sie empfangen wurden
-
die Liste der sofortigen Aufgaben (werden vor ausstehenden Aufgaben verarbeitet):
- Testaufgaben (erstellt als Reaktion auf Anfragen zum Testen von Datenpunkt/Vorverarbeitung durch das Frontend)
- Aufgaben abhängiger Datenpunkte
- Sequenzaufgaben (Aufgaben, die in einer strikten Reihenfolge ausgeführt werden müssen):
- mit Vorverarbeitungsschritten, die den letzten Wert verwenden:
- Änderung
- Drosselung
- JavaScript (Bytecode-Caching)
- Caching der Vorverarbeitung abhängiger Datenpunkte
- mit Vorverarbeitungsschritten, die den letzten Wert verwenden:
-
die Liste der abgeschlossenen Aufgaben
Caching für die Vorverarbeitung
Das Caching für die Vorverarbeitung wurde eingeführt, um die Leistung der Vorverarbeitung für mehrere abhängige Datenpunkte mit ähnlichen Vorverarbeitungsschritten zu verbessern (was ein häufiges Ergebnis von LLD ist).
Das Caching erfolgt, indem ein abhängiger Datenpunkt vorverarbeitet wird und einige der internen Vorverarbeitungsdaten für die übrigen abhängigen Datenpunkte wiederverwendet werden. Der Vorverarbeitungs-Cache wird nur für den ersten Vorverarbeitungsschritt der folgenden Typen unterstützt:
- Prometheus-Muster (indiziert die Eingabe nach Metriken)
- JSONPath (parst die Daten in einen Objektbaum und indiziert den ersten Ausdruck
[?(@.path == "value")])
Preprocessing-Worker
Die Konfigurationsdatei des Zabbix-Servers ermöglicht es Benutzern, die Anzahl der Threads für Preprocessing-Worker festzulegen. Der Konfigurationsparameter StartPreprocessors sollte verwendet werden, um die Anzahl der vorab gestarteten Instanzen von Preprocessing-Workern festzulegen; sie sollte mindestens der Anzahl der verfügbaren CPU-Kerne entsprechen.
Wenn Preprocessing-Aufgaben nicht CPU-gebunden sind und häufige Netzwerkanfragen beinhalten, wird die Konfiguration zusätzlicher Worker empfohlen. Die optimale Anzahl der Preprocessing-Worker kann von vielen Faktoren abhängen, darunter die Anzahl der "preprocessable" Datenpunkte (Datenpunkte, die die Ausführung von Preprocessing-Schritten erfordern), die Anzahl der Datenerfassungsprozesse, die durchschnittliche Anzahl der Schritte für das Preprocessing von Datenpunkten usw. Zu wenige Worker können zu einer hohen Speicherauslastung führen. Hinweise zur Fehlerbehebung bei übermäßiger Speicherauslastung in Ihrer Zabbix-Installation finden Sie unter Profiling excessive memory usage with tcmalloc.
Wenn jedoch keine aufwendigen Preprocessing-Operationen wie das Parsen großer XML-/JSON-Blöcke anfallen, kann die Anzahl der Preprocessing-Worker der Gesamtzahl der Datenerfasser entsprechen. Auf diese Weise wird es meist (außer in Fällen, in denen Daten vom Datenerfasser in großen Mengen eintreffen) mindestens einen unbesetzten Preprocessing-Worker für erfasste Daten geben.
Zu viele Datenerfassungsprozesse (Poller, unreachable pollers, ODBC pollers, HTTP pollers, Java pollers, pingers, trappers, proxypollers) zusammen mit dem IPMI manager, SNMP trapper und Preprocessing-Workern können das pro Prozess zulässige Limit für Dateideskriptoren des Preprocessing-Managers erschöpfen.
Wenn das pro Prozess zulässige Limit für Dateideskriptoren erschöpft ist, wird der Zabbix-Server angehalten, typischerweise kurz nach dem Start, manchmal jedoch erst nach längerer Zeit.
Um solche Probleme zu vermeiden, überprüfen Sie die Zabbix-Server-Konfigurationsdatei, um die Anzahl gleichzeitiger Prüfungen und Prozesse zu optimieren.
Stellen Sie außerdem bei Bedarf sicher, dass das Limit für Dateideskriptoren ausreichend hoch gesetzt ist, indem Sie die Systemlimits prüfen und anpassen.
Pipeline zur Wertverarbeitung
Die Verarbeitung von Datenpunktwerten wird in mehreren Schritten (oder Phasen) von mehreren Prozessen ausgeführt. Dies kann dazu führen:
- Ein abhängiger Datenpunkt kann Werte empfangen, während der Master-Wert dies nicht kann.
Dies lässt sich mit folgendem Anwendungsfall erreichen:
- Der Master-Datenpunkt hat den Werttyp
UINT(es kann ein Trapper-Datenpunkt verwendet werden), der abhängige Datenpunkt hat den WerttypTEXT. - Für weder den Master- noch den abhängigen Datenpunkt sind Vorverarbeitungsschritte erforderlich.
- Ein Textwert (zum Beispiel „abc“) soll an den Master-Datenpunkt übergeben werden.
- Da keine Vorverarbeitungsschritte auszuführen sind, prüft der Vorverarbeitungsmanager, ob sich der Master-Datenpunkt nicht im Zustand NOT SUPPORTED befindet und ob ein Wert gesetzt ist (beides trifft zu), und reiht den abhängigen Datenpunkt mit demselben Wert wie den des Master-Datenpunkts in die Warteschlange ein (da es keine Vorverarbeitungsschritte gibt).
- Wenn sowohl der Master- als auch der abhängige Datenpunkt die Phase der History-Synchronisierung erreichen, wird der Master-Datenpunkt aufgrund eines Fehlers bei der Wertkonvertierung zu NOT SUPPORTED (Textdaten können nicht in eine vorzeichenlose Ganzzahl konvertiert werden).
- Der Master-Datenpunkt hat den Werttyp
Als Ergebnis empfängt der abhängige Datenpunkt einen Wert, während der Master-Datenpunkt seinen Zustand in NOT SUPPORTED ändert.
- Ein abhängiger Datenpunkt empfängt einen Wert, der in der History des Master-Datenpunkts nicht vorhanden ist.
Der Anwendungsfall ist dem vorherigen sehr ähnlich, mit Ausnahme
des Typs des Master-Datenpunkts. Wenn zum Beispiel der Typ
CHARfür den Master-Datenpunkt verwendet wird, dann wird der Wert des Master-Datenpunkts in der Phase der History-Synchronisierung abgeschnitten, während abhängige Datenpunkte ihre Werte aus dem ursprünglichen (nicht abgeschnittenen) Wert des Master-Datenpunkts erhalten.